OTTIMIZZAZIONE CRITERI DI SCHEDULING PER JOB MULTIPROCESSO IN AMBIENTE GRID
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
UNIVERSITÀ DEGLI STUDI DI PARMA
FACOLTÀ DI SCIENZE MATEMATICHE FISICHE E NATURALI
CORSO DI LAUREA INFORMATICA
OTTIMIZZAZIONE CRITERI DI SCHEDULING
PER JOB MULTIPROCESSO IN AMBIENTE GRID
RELATORE: CANDIDATO:
Chiar.mo Prof. ROBERTO ALFIERI LEONARDO MUTTI
Anno Accademico 2007-2008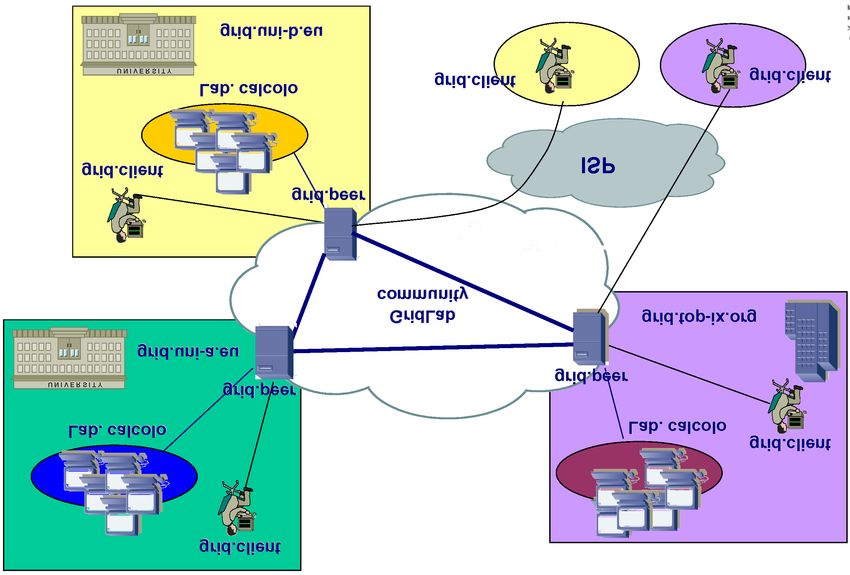
A coloro che nel mio percorso
hanno sempre creduto.
Grazie.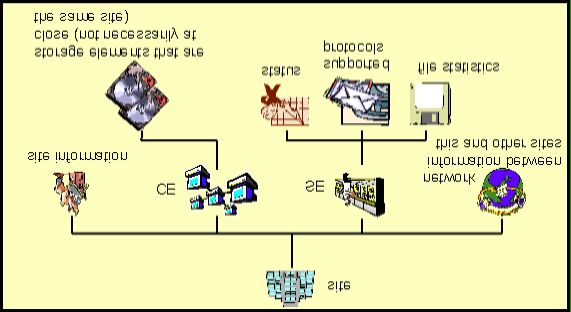
Indice
1 Premessa........................................................................................................................8
2 Teoria delle code..........................................................................................................10
2.1 Schema di un processo a coda.............................................................................10
2.1.1 Processo degli arrivi.....................................................................................11
2.1.2 Capacità della coda.......................................................................................11
2.1.3 Processo di servizi........................................................................................11
2.1.4 Canali di servitori.........................................................................................12
2.1.5 Descrivere una coda – Notazione Kendall...................................................12
2.1.6 Indici di efficienza........................................................................................13
2.1.7 Valutazione indici di efficienza – Legge di Little........................................15
2.2 Fair Queuing........................................................................................................16
2.2.1 Proprietà.......................................................................................................17
2.2.2 Weighted fair queuing..................................................................................18
2.3 Preemption...........................................................................................................19
2.4 Starvation.............................................................................................................20
2.5 Checkpointing......................................................................................................21
3 Scenari.........................................................................................................................22
3.1 Reti.......................................................................................................................22
3.2 Sistemi Operativi.................................................................................................24
3.2.1 Scheduler della CPU....................................................................................25
3.2.2 Scheduling con diritto di prelazione............................................................25
3.2.3 Criteri di scheduling.....................................................................................27
3.2.4 Algoritmi di scheduling................................................................................28
3.3 Job Manager.........................................................................................................28
3.3.1 Algoritmi di assegnazione dei nodi..............................................................30
4 Grid..............................................................................................................................32
4.1 Evoluzione del Grid Computing..........................................................................33
4.2 Il Cluster Grid di Parma.......................................................................................35
5 Job Sheduler................................................................................................................37
55.1 Controllo del traffico............................................................................................38
5.2 Obbiettivo primario..............................................................................................38
5.3 Ottimizzazione.....................................................................................................38
5.4 MAUI...................................................................................................................38
5.4.1 Filosofia e obbiettivi dello scheduler Maui..................................................39
5.4.2 Scheduling Object........................................................................................39
5.4.3 Risorse..........................................................................................................40
5.4.4 Class (or Queue)...........................................................................................41
5.4.5 Partitions......................................................................................................41
5.4.6 Account........................................................................................................42
5.4.7 Priorità..........................................................................................................42
5.4.8 Preemption...................................................................................................42
5.4.9 Fairness........................................................................................................47
5.4.10 Fairshare.....................................................................................................47
5.4.10.1 Obbiettivi del fairshare......................................................................51
5.4.11 Reservation.................................................................................................52
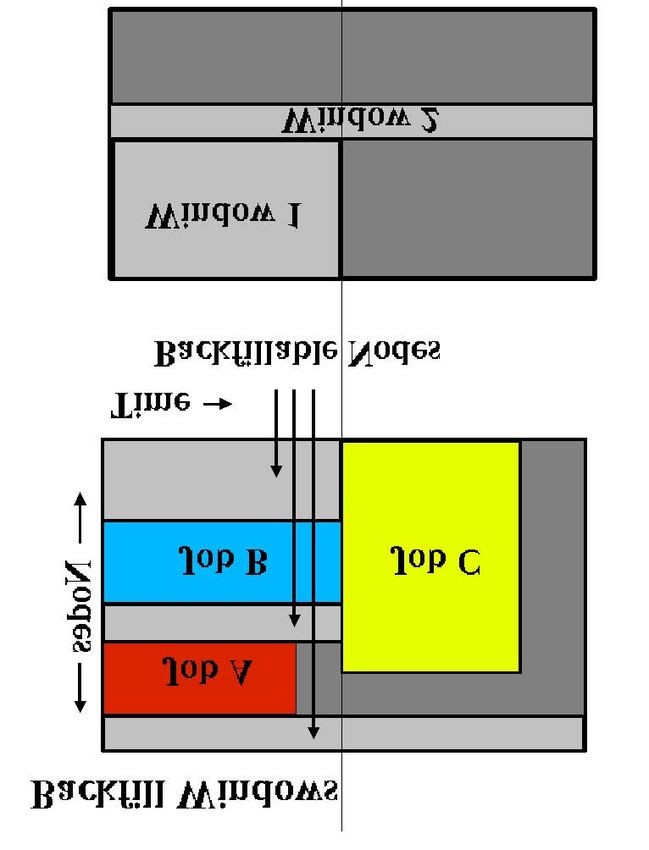
5.4.12 Backfill.......................................................................................................56
5.4.13 Checkpointing............................................................................................58
5.5 MOAB..................................................................................................................59
5.6 LSF.......................................................................................................................59
5.7 Job Multiprocesso................................................................................................60
6 Sviluppo del progetto...................................................................................................61
6.1 TORQUE.............................................................................................................61
6.1.1 Installazione di TORQUE............................................................................61
6.1.2 Creazione dei pacchetti RPM.......................................................................63
6.1.3 Il file “server_name”....................................................................................63
6.1.4 Il file "nodes"...............................................................................................64
6.1.5 Installare Torque in un nodo.........................................................................64
6.1.6 Il file "config"...............................................................................................64
6.1.7 Creazione delle code....................................................................................65
6.1.8 Il comando qsub...........................................................................................66
66.2 MAUI...................................................................................................................67
6.2.1 Installazione di Maui....................................................................................67
6.2.2 Configurazione iniziale................................................................................68
6.2.3 Maui testing..................................................................................................69
6.2.4 File layout.....................................................................................................69
6.3 MOAB..................................................................................................................71
6.3.1 Installazione di Moab...................................................................................71
6.3.2 Variabili d'ambiente......................................................................................71
6.3.3 Avviamo Moab Workload Manager.............................................................72
6.3.4 Installazione Moab Cluster Manager...........................................................72
6.4 Gestione del job CERT........................................................................................73
6.5 Esecuzione di un job multiprocesso.....................................................................74
7 Conclusioni..................................................................................................................75
8 Bibliografia..................................................................................................................77
9 Sitografia.....................................................................................................................78
10 Appendice A : maui.cfg.............................................................................................80
71 Premessa
La necessità di utilizzare strumenti informatici che consentano operazioni molto
complesse in tempi molto ristretti, ha portato l'idea di raccogliere risorse di calcolo per
ottenere strumenti sempre più performanti, al fine di soddisfare le richieste di molti.
Da questa idea nasce Grid: una struttura complessa di strumenti informatici distribuiti
su rete geografica che permetta, a chi né ha la possibilità, di svolgere operazioni
all'interno di siti di calcolo.
Da questa vasta disponibilità di risorse e da un numero sempre più ampio di possibili
fruitori nasce il problema affrontato in questo elaborato di tesi: come è possibile
ottimizzare la gestione di tali risorse in modo da soddisfare tutte le richieste, e renderla
“giusta”, così da ripartirle in modo equo e bilanciato ?
Da queste due domande e stato estrapolato un contesto di studio dal quale non
potevamo esulare, la gestione delle code e dei criteri di scheduling.
Partendo da un analisi teorica di come le code possano essere rappresentate per essere
gestite e studiate e stato analizzato come esse vengano risolte in due contesti informatici
fondamentali: i sistemi operativi e le reti di calcolatori.
Una volta compresi i concetti chiave di tali gestioni si è studiato più nel dettaglio i
diretti gestori di code nei siti di calcolo in ambiente Grid, ovvero i job scheduler.
Analizzando le loro principali caratteristiche e metodi di funzionamento ci siamo
imbattuti nelle problematiche della gestione di code di job come: la gestione degli
utenti, l'assegnazione delle risorse a tali utenti, la preemption, il problema della
starvation, l'introduzione della tecnica del fairshare e altre ancora.
Lavorando sul sito di calcolo dell'Università di Parma si è proceduto a configurare il job
scheduler, in modo da risolvere tali problematiche e ad introdurre con successo alcune
tecniche avanzate di gestione code come la backfill e il fairshare.
In tale contesto si è manifestata la ormai sempre più attuale necessità di gestione di job
multiprocesso, che richiedono una configurazione più complessa e accorta del sito di
8calcolo dovuta alla loro particolare necessità di risorse in modo simultaneo.
92 Teoria delle code
La teoria delle code è lo studio matematico delle linee di attesa (o code) e di vari
processi correlati, quali il processo di arrivo in coda, l'attesa (essenzialmente un
processo di immagazzinamento) e il processo di servizio. Può essere applicata ad
un'ampia varietà di problemi reali, soprattutto nel campo dei trasporti, delle
telecomunicazioni, della fornitura di servizi pubblici (ad es. in sanità) e delle operazioni
aziendali.
Usualmente, la teoria delle code è considerata una branca della ricerca operativa. Le sue
origini vengono fatte risalire al 1909 quando l'ingegnere danese Agner Krarup Erlang
pubblicò un articolo intitolato “The theory of probability and telephone conversations”
relativo alle attese nelle chiamate telefoniche.
2.1 Schema di un processo a coda
Schematicamente un processo in coda possiamo rappresentarlo nel seguente modo:
Sorgente di arrivi Clienti Stazione Clienti serviti
Coda di servizio
Gli elementi fondamentali che caratterizzano un sistema di servizio sono:
• Processo degli arrivi
• Caratteristiche proprie della coda
• Capacità della coda
• Processo di servizio
• Canali di servitori
102.1.1 Processo degli arrivi
La dimensione della sorgente degli arrivi per ipotesi è infinita. Il processo degli arrivi
viene definito in base ai tempi di interarrivo, cioè il tempo che intercorre tra due entrate
di due clienti successivi. In genere si ipotizza che il processo degli arrivi sia stazionario
cioè non dipende dal tempo e che le variabili aleatorie siano indipendenti ed
identicamente distribuite.
Le caratteristiche della coda, sono di due tipi:
• Disciplina del servizio: cioè l'ordine con cui il cliente viene scelto dalla coda per
poter usufruire del servizio:
◦ FCFS (FIFO) First In First Out
◦ LCFS (LIFO) Last In Firs Out
◦ SIRO (Servizio in ordine casuale)
◦ Basata sulla classe di priorità
• Comportamento del cliente: che può essere diverso, ad esempio:
◦ Rinuncia, il cliente aspetta poi si scoraggia
◦ Indecisione, cioè cambia coda
◦ Corruzione, paga un prezzo per avanzare di posto nella coda
◦ Inganno, avanza senza pagare il prezzo
2.1.2 Capacità della coda
Può essere o finita o infinita e questo va a influenzare la capacità del sistema, infatti se
la coda è finita e viene saturata il cliente non può accedere al servizio e deve cambiare
coda.
2.1.3 Processo di servizi
Descrive il modi in cui viene erogato il servizio, viene definito per mezzo dei tempi di
11servizio nel caso in cui essi siano dipendenti, indipendenti ed identicamente distribuiti.
Il più comune è quello con i tempi di servizio esponenziale di Poisson. Può capitare che
il tempo di servizio dipenda dalla dimensione della coda, oppure avere dei servitori a
sequenza cioè una catena di servitori per poter ottenere il servizio completo.
2.1.4 Canali di servitori
Possiamo avere:
• Più canali ed un unico servitore, cioè una fila davanti a un posto di servizio.
• Un unico canale e più servitori, dove i clienti sono in un unica coda e appena un
servitore si libera si accede al servizio.
2.1.5 Descrivere una coda – Notazione Kendall
Nel 1953, David George Kendall introdusse la notazione A/B/C, successivamente estesa
come A/B/s/c/z/p nella quale i numeri sono sostituiti con quanto segue.
• A è la distribuzione dei tempi di interarrivo (processo degli arrivi)
• B è la distribuzione dei tempi di servizio
• s è il numero dei servitori (capacità di servizio)
• c è la capacità del sistema o capacità della sorgente di arrivi (il sistema può
accettare al massimo c clienti, per default è infinita)
• z è la disciplina del servizio (per default è FCFS)
• p è la capacità dell'intero sistema o dimensione della sorgente degli arrivi (per
default è infinita)
A è B possono assumere i seguenti valori:
• M per "di Markov", implicante una distribuzione esponenziale negativa unilatera
per i tempi di servizio o tra gli arrivi: ciò implica l'assenza di memoria di questi
ultimi;
• D per distribuzione "degenere" o "deterministica" dei tempi di servizio, tutti i
12clienti hanno lo stesso valore;
• Ek per una distribuzione di Erlang con k come parametro di forma;
• G per una distribuzione "Generale".
z invece può assumere i valori:
• First Come First Served (FCFS) (o First In First Out - FIFO) (il primo che arriva
viene servito per primo);
• Last Come First Served (LCFS) (o Last In First Out - LIFO) (l'ultimo che arriva
viene servito per primo);
• Service In Random Order (SIRO) (servizio in ordine casuale).
Esempi di code definiti con tali convenzioni sono:
M/M/1: Questa è una coda molto semplice. Qui il tempo di arrivo e il tempo di servizio
rispettano una distribuzione esponenziale negativa (Poisson). Il sistema prevede solo un
server. Questo tipo di coda può essere applicato a una grande varietà di problemi come
un qualsiasi sistema costituito da un numero ampio e indipendente di clienti
approssimabili con un processo di Poisson.
Purtroppo l'uso del processo di Poisson per stimare il tempo di servizio spesso non è
applicabile in modo fedele ma rimarrà solo una cruda approssimazione.
M/D/n: Qui il processo di arrivo è un processo di Poisson mentre il processo di servizio
rispetta una distribuzione deterministica. Il sistema ha n server. Qui il tempo di sevizio
di può essere stimato uguale per tutti i clienti. Per esempio una biglietteria con n
cassieri.
G/G/n: Questa è il sistema più generale dove l'arrivo del cliente e il tempo di servizio
sono entrambi casuali. Il sistema ha n server. Nessuna soluzione analitica è tuttora
conosciuta per questo tipo di code.
2.1.6 Indici di efficienza
Per analizzare le prestazioni del sistema è possibile utilizzare degli indici di efficienza:
13• L numero medio di clienti nel sistema
• Lq numero medio di clienti in coda
• W tempo medio per cliente nel sistema
• Wq tempo medio per cliente in coda
quando è passato poco tempo dalla fornitura del servizio si dice che siamo in uno stato
transitorio che è uno stato difficile da gestire e valutare. Se passa un tempo sufficiente il
sistema passa a condizioni di regime ovvero il sistema diventa stazionario, questa è la
condizione più semplice da considerare. Questi indici valgono solo per condizioni a
regime.
Un altro indice che consideriamo è:
• ρ fattore di utilizzazione del posto di servizio
Altre notazioni in input al nostro sistema sono:
• λ frequenza media dei tempi di interarrivo (ovvero il numero medio di arrivi
nell'unità di tempo)
• µ velocità media del servizio o tasso di servizio (ovvero il numero medio di
clienti per i quali è espletato il servizio nell'unita di tempo)
Partendo da λ e µ possiamo ottenere il tempo medio di interarrivo e il tempo medio di
servizio:
• 1/ λ tempo medio di interarrivo
• 1/ µ tempo medio di servizio
C'è una relazione che lega tutte e tre queste variabili ed è:
ρ = λ/ µ
Esempio
Consideriamo i seguenti intervalli di interarrivo:
3' 7' 10' 4' 6' in 30 minuti
14e di voler calcolare il numero medio di arrivi nell'unità di tempo e il tempo medio di
interarrivo.
Il numero medio di arrivi nell'unità di tempo sarà dato da:
5/30 = 1/6 = λ
per cui il tempo medio di interarrivo sarà:
1/ λ = 6'
2.1.7 Valutazione indici di efficienza – Legge di Little
Schematicamente abbiamo una situazione del genere:
Range di arrivo L
Modello
Range di servizio W
Variabili
Il progettista avrà delle variabili per minimizzare il costo del servizio. Se L e W sono
grandi il modello non funziona bene, e per farlo funzionare bene posso variare il
numero di servitori, la disciplina, le regole del sistema, ecc...
Esiste una legge che ci viene in aiuto:
Legge di Little L=λW
Lq=λWq
15Se µ è costante → W = Wq + 1/µ
Applichiamo ora queste nozioni ad un caso base:
caso D/D/1, è il più facile da analizzare ma anche il più difficile che esista nella realtà:
Informazione a(i) = istante di arrivo del cliente i
s(i) = durata del servizio del cliente i
Variabili X(i) = istante di uscita del cliente i dal sistema
W(i) = tempo di attesa del cliente i
Se supponiamo che X(0) = 0 allora:
X(i) = s(i) + max {a(i), X(i-1)}
W(i) = X(i) – a(i) - s(i)
Il numero medio di clienti nel sistema è dato dalla somma dei clienti che soddisfano la
relazione:
a(i) ≤ t ≤ X(i)
Ora andremo ad analizzare alcuni delle nozioni più importanti, utili per una corretta
gestione delle code.
2.2 Fair Queuing
Il Fair Queuing è una algoritmo di scheduling usato in informatica sia nei computer per
la gestione di processi che nelle telecomunicazioni per permettere a flussi di pacchetti di
condividere equamente la capacità di trasmissione o ricezione del collegamento.
La nascita del Fair Queuing avviene nel 1985 grazie a John Nagle durante i suoi studi
nel campo delle telecomunicazioni.
16Il vantaggio rispetto agli algoritmi di gestione delle code convenzionali è la migliore
gestione di flussi ad alto carico di lavoro, con la possibilità di sfruttare a pieno le
potenzialità del sistema. Fair Queuing può essere vista come una approssimazione del
processo di sharing della CPU in un calcolatore.
2.2.1 Proprietà
Il fair queuing è usato principalmente nei router, switch e multiplexer che inoltrano i
pacchetti da un buffer, con l'evolversi della tecnologia il fair queuing è stato utilizzato
anche per risolvere altri tipi di problemi, come nel nostro caso, la gestione di job
multiprocesso in un ambiente Grid.
Il fair queuing lavora con un buffer che può essere visto come un insieme di code dove i
pacchetti o i job vengono temporaneamente depositati prima di essere trasmessi o
eseguiti. Il buffer è suddiviso appunto in code dove vengono memorizzati i pacchetti o i
job in base alle loro caratteristiche. Ad esempio per quanto riguarda i pacchetti di rete
vengono suddivisi in base all'IP di destinazione oppure per quanto riguarda i job sono
assegnati ad una coda specifica in base a chi sottomette il job, quale è la sua priorità
oppure in base alle risorse richieste per la sua computazione.
La proprietà principale del fair queuing è quella di fissare degli obbiettivi di
massimizzazione o minimizzazione di alcuni valori, e in base a questi obbiettivi
l'algoritmo modula la gestione delle code.
Ecco il motivo del suo nome fair queuing, “code giuste”, infatti tramite l'assegnazione
di obbiettivi efficienti e corretti l'algoritmo si sviluppa nel tempo e si modula per gestire
al meglio il flusso di lavoro.
Ad esempio possiamo impostare come obbiettivo la minimizzazione del tempo di attesa
medio per ogni utente che sottomette un job, oppure nell'ambito delle reti il tempo di
attesa di ogni pacchetto in base all'IP di destinazione. L'algoritmo lavorerà per ottenere
questa minimizzazione così da soddisfare tutti i “clienti” delle code da esso gestite in
modo equo. Per ottenere tale obbiettivo l'algoritmo di scheduler farà in modo di
memorizzare tutti i dati relativi a quanto ogni utente che sottometto job oppure che deve
17ricevere dei pacchetti di rete è stato già soddisfatto e in base a questi dati deciderà quale
utente ha ora la priorità di gestione.
2.2.2 Weighted fair queuing
WFQ è un algoritmo della famiglia degli algoritmi fair, è stato sviluppato nel 1989,
quattro anni dopo l'introduzione di Nagle del Fair Queuing, da Lixia Zhang. Questo
algoritmo è stato introdotto sempre nell'ambito della gestione delle reti in modo da
garantire un accesso equo alle risorse di rete, così da evitare che una flusso potesse
occupare tutte le risorse del canale di comunicazione.
Infatti a differenza del Fair Queuing classico dove i pacchetti vengono distribuiti su
varie code e le code vengono processate tutte simultaneamente suddividendo il canale
per le code presenti, il Weighted Fair Queuing classifica al momento dell'arrivo il
pacchetto, assegnando ad esso un peso (weight) in base ai dati contenuti nell'header del
pacchetto stesso e in base a questo peso andrà a posizionare il pacchetto in una coda
opportuna così da poter classificare le code presenti in base al peso dei pacchetti e in
base a tale peso lo scheduler andrà a ripartire la capacità di banda.
18Illustrazione 1: Weighted Fair Queuing
2.3 Preemption
La preemption (o prelazione) è, in informatica, l'operazione in cui un processo viene
temporaneamente interrotto e portato al di fuori della CPU, senza alcuna richiesta di
cooperazione e con l'intenzione di ripristinarlo in un secondo momento, per dare spazio
ad un altro processo a priorità più alta. Tale scambio è noto come context switch (o
cambiamento di contesto). La preemption può avvenire tramite uno scheduler, che ha il
compito di interrompere e/o ripristinare i processi presenti nel sistema operativo a
seconda del loro stato; in tal caso si parla di preemptive scheduling (o scheduling con
diritto di prelazione).
Tramite il metodo di preemption vengono gestiti i sistemi operativi più performanti e
vengono gestiti i Batch System che necessitano di riservare maggiore attenzione e
priorità di esecuzione a certi job rispetto altri già in esecuzione.
19La preemption è un metodo che interviene su due processi distinti, un primo processo
subisce la preemption e viene sospeso durante l'esecuzione per rilasciare risorse ad un
altro processo detto “processo preemptor”. Con risorse non intendiamo solo la CPU
come citato precedentemente ma vengono intese tutte le risorse necessarie al processo
“preemptor” presenti nel sito di calcolo.
2.4 Starvation
In informatica, per starvation (termine inglese che tradotto letteralmente significa
inedia) si intende l'impossibilità, da parte di un processo pronto all'esecuzione, di
ottenere le risorse di cui necessita.
Un esempio tipico è il non riuscire ad ottenere il controllo della CPU da parte di
processi con priorità molto bassa, qualora vengano usati algoritmi di scheduling a
priorità. Può capitare, infatti, che venga continuamente sottomesso al sistema un
processo con priorità più alta. Un aneddoto riguardo questo problema è la storia del
processo con bassa priorità, scoperto quando fu necessario fermare il sistema sull'IBM
7094 al MIT nel 1973: era stato sottomesso nel 1967 e fino ad allora non era ancora
stato eseguito.
Per evitare questi problemi si possono utilizzare, oltre ad algoritmi di scheduling
diversi, come Round Robin, le cosiddette tecniche di invecchiamento (aging). Ovvero si
provvede ad aumentare progressivamente, ad intervalli regolari, la priorità dei processi
qualora questi non siano riusciti ad ottenere le risorse richieste. Questo fa sì che anche
un processo con la priorità più bassa possa potenzialmente assumere quella più alta,
riuscendo così ad ottenere, in un tempo massimo predefinito, quanto di cui necessita.
Altri usi del termine starvation sono in relazione alle risorse di accesso alla memoria o
CPU: si dice che un programma è bandwidth-starved quando la sua esecuzione è
rallentata da un'insufficiente velocità di accesso alla memoria, o CPU-starved quando il
processore è troppo lento per eseguire efficacemente il codice.
202.5 Checkpointing
Il checkpointing è una tecnica utilizzata per fornire fault tolerance nei sistemi
informatici. Fondamentalmente si basa sulla memorizzazione dello stato corrente di una
applicazione così da poter utilizzare tali informazioni salvate per ripristinare
l'applicazione in caso di blocco o chiusura inaspettata dell'applicazione stessa.
Abbiamo 3 diverse tipologie di checkpointing: la prima cosiddetta kernel-checkpoint
dove è il kernel linux stesso che si occupa di fornire il servizio di checkpointing , la
seconda, user-checkpointing dove sono software definita dall'utente ad occuparsi di
effettuare checkpointing della applicazione in esecuzione e la terza, application-
checkpointing dove è l'applicazione stessa che è stata progettata e programmata per
effettuare checkpointing.
Come vedremo il checkpointing è ampiamente utilizzato anche nei Batch System per
una corretta gestione dei processi.
213 Scenari
In questo capitolo vogliamo porre l'attenzione su come la gestione delle code sia
fondamentale nelle componenti più importanti di un sistema informatico.
Sia la progettazione di reti di calcolatori che la progettazione dei sistemi operativi base
dei nostri calcolatori ha dovuto scontrarsi con la gestione di code. Senza una gestione
corretta di tali code non si sarebbe mai arrivati ad avere reti cosi preformanti e sistemi
operativi così complessi come siamo abituati ad usare.
3.1 Reti
Il primo scenario dove incontriamo la necessita di gestire le code è nella gestione dei
protocolli di comunicazione di reti di calcolatori. Infatti proprio sugli algoritmi utili alle
comunicazioni telefoniche è nata la teoria delle code che si è andata via via
approfondendosi con l'avvento delle reti di calcolatori.
Con la trasmissione di dati in formato di pacchetto la prima necessità è stata quella di
suddividere in modo equo un unico canale di comunicazione evitando il più possibile la
perdita di dati e la congestione del canale.
Con congestione del canale si intende quando il traffico offerto dalla rete è vicino o
superiore alla capacità della rete stessa.
Proprio nella gestione della congestioni si individuano gli algoritmi più complessi e il
primo approccio per una gestione “Fair” della problematica.
La congestione può essere causata da più fattori. Se improvvisamente diversi flussi di
pacchetti cominciano ad arrivare attraverso tre o quattro linee di input e tutti i pacchetti
necessitano della stessa linea di output, inizia a formarsi una coda. Se la memoria non è
sufficiente, non sarà possibile conservare tutti i dati, perciò alcuni pacchetti andranno
persi. Aggiungere memoria può aiutare fino ad un certo punto, ma Nagle (1987) ha
scoperto che se i router hanno memoria infinita la congestione peggiora anziché
migliorare, poiché quando raggiungeranno il fronte della coda, i pacchetti saranno già
22scaduti (ripetutamente) e quindi saranno già stati trasmessi dei duplicati.
Si conoscono molti algoritmi di controllo della congestione, e per organizzarli in modo
sensato, Yang and Reddy (1995) hanno sviluppato una tassonomia. I due studiosi hanno
diviso prima di tutto gli algoritmi in soluzioni a ciclo aperto e soluzioni a ciclo chiuso;
poi hanno diviso gli algoritmi a ciclo aperto in soluzioni che agiscono sulla sorgente e
soluzioni che lavorano sulla destinazione. Anche gli algoritmi a ciclo chiuso sono stati
divisi in due categorie: soluzioni a retroazione esplicita e soluzione a retroazione
implicita.
Con algoritmi a ciclo aperto si intende quegli algoritmi che cercano di prevenire il
verificarsi della congestione ricorrendo ad una buona progettazione della rete. Mentre
gli algoritmi a ciclo chiuso si basano sul concetto di controreazione; la rete viene
costantemente monitorata, al verificarsi di una congestione i router si scambiano
informazioni al fine di migliorare la situazione.
Le tecniche più utilizzate per il controllo della congestione sono:
• Bit di allarme
Tramite un bit all'interno del pacchetto viene segnalato uno stato di congestione così da
poter diminuire il flusso di dati sino al ristabilirsi della condizione normale.
• Chole packet
In questo caso la comunicazione di congestione viene data tramite l'invio di un
pacchetto “chole packet” che comunica alla sorgente lo stato di congestione ed eventuali
altri canali da sfruttare per effettuare l'invio di pacchetti.
• Chole packet hop-by-hop
• Load shedding
Con load shedding indichiamo l'azione di eliminazione intrapresa dai router inondati da
troppi pacchetti.
• RED (Random Early Detection)
Si tratta di un algoritmo che permette ai router di scartare i pacchetti prima che tutto lo
23spazio del buffer sia completamente esaurito, in pratica, facendo in modo che i router
scartino i pacchetti prima che la situazione diventi senza speranza è possibile bloccare il
problema sul nascere
Illustrazione 2: Random Early Detection
• Jitter
Con jitter viene indicata la variazione nel tempo di arrivo del pacchetto, tramite il
controllo di questo valore è possibile effettuare controllo della congestione è diminuire
il flusso appena si osserva che i tempi di consegna stanno aumentando.
3.2 Sistemi Operativi
Il secondo scenario informatico in cui possiamo trovare la problematica della gestione
delle code è quello dei sistemi operativi. Infatti il sistema operativo ha come compito
principale quello di gestire in modo ottimale i processi in esecuzione sul calcolatore.
Tali processi vengono spesso eseguiti in modo concorrenziale richiedendo risorse come
CPU, memoria e dispositivi di input e output per essere portati a termine, proprio il
sistema operativo si occupa di tale gestione così da evitare lunghe attese dell'utente per
24l'esecuzione del proprio processo e situazioni di stallo del sistema operativo e quindi del
calcolatore stesso.
In questo contesto andremo ad dare una breve analisi di come il sistema operativo
gestisce l'allocazione della risorsa più importante la CPU, chi in particolare si occupa di
tale gestione, che algoritmi usa e quali problematiche possono sorgere se tale risorsa
non fosse gestita correttamente.
3.2.1 Scheduler della CPU
Lo scheduling della CPU è alla base dei sistemi operativi multi programmati: attraverso
la commutazione del controllo della CPU tra i vari processi, il sistema operativo può
rendere più produttivo il calcolatore.
L’obbiettivo della multi programmazione è avere sempre processi in esecuzione al fine
di massimizzare l’utilizzo della CPU. In un sistema con una sola unità di elaborazione si
può eseguire al più un processo alla volta; gli altri processi, se presenti, devono
attendere che la CPU si liberi e possa essere nuovamente sottoposta a scheduling.
Ogni qualvolta la CPU passa nello stato d’inattività il sistema operativo sceglie per
l’esecuzione uno dei processi presenti nella coda dei processi pronti. In particolare è lo
scheduler a breve termine, o scheduler della CPU che, tra i processi nella memoria
pronti per l’esecuzione, sceglie quale assegnare alla CPU.
La coda dei processi pronti non è necessariamente una coda in ordine di arrivo (FIFO).
Come si nota analizzando i diversi algoritmi di scheduling, una coda dei processi pronti
si può realizzare come una coda FIFO, una coda con priorità, un albero o semplicemente
una lista concatenata non ordinata.
3.2.2 Scheduling con diritto di prelazione
Le decisioni riguardanti lo scheduling della CPU si possono prendere nelle seguenti
circostanze:
1. Un processo passa dallo stato di esecuzione allo stato di attesa
2. Un processo passa dallo stato di esecuzione allo stato pronto
253. Un processo passa dallo stato di attesa allo stato pronto
4. Un processo termina
Il primo e l’ultimo caso non prevedono alcuna scelta di scheduling; a essi segue la scelta
di un nuovo processo da eseguire, sempre che ce ne sia uno nella coda dei processi
pronti per l’esecuzione; in questo caso si dice che lo schema di scheduling è senza
diritto di prelazione (non preemptive). Una scelta si deve invece fare nei due casi
centrali; in tal caso parliamo di scheduling con diritto di prelazione (preemptive).
Nel caso dello scheduling senza diritto di prelazione, quando si assegna la CPU ad un
processo, questo rimane in possesso della CPU fino al momento del suo rilascio, dovuto
la termine dell’esecuzione o al passaggio nello stato di attesa. Questo metodo di
scheduling è impiegato nell’ambiente Microsoft Windows ed è l’unico che si può
utilizzare in certe architetture che non prevedono la presenza di un temporizzatore,
necessario per lo scheduling con diritto di prelazione.
La capacità di prelazione si ripercuote anche sulla progettazione del nucleo del sistema
operativo. Durante l'elaborazione di una chiamata del sistema, il nucleo può essere
impegnato in attività a favore di un processo; tali attività possono comportare la
necessità di modifiche a importanti dati del nucleo, come le code I/O. Se si ha la
prelazione del processo durante tali modifiche e il nucleo deve leggere e o modificare
gli stessi dati, si può avere il caos.
Alcuni sistemi operativi, tra cui la maggior parte delle versioni dello UNIX, affrontano
questo problema attendendo il completamento della chiamata del sistema o che si abbia
il blocco dell'I/O prima di eseguire un cambio di contesto (context switching).
Purtroppo questo modello d'esecuzione del nucleo non è adeguato alle computazioni in
tempo reale e alle multielaborazioni.
Per quel che riguarda lo UNIX, sono ancora presenti sezioni di codice a rischio. Poiché
le interruzioni si possono, per definizione, verificare in ogni istante e il nucleo non può
sempre ignorarle, le sezioni di codice eseguite per effetto delle interruzioni devono
essere protette da un uso simultaneo. Il sistema operativo deve ignorare raramente le
interruzioni, altrimenti si potrebbero perdere dati in ingresso, o si potrebbero
26sovrascrivere dati in uscita.
Per gestire in modo efficiente sistemi con sempre più numerose unità di elaborazione, si
devono ridurre al minimo le modifiche allo stato del sistema delle interruzioni, e si deve
aumentare al massimo la selettività dei meccanismi di bloccaggio.
3.2.3 Criteri di scheduling
Diversi algoritmi di scheduling della CPU hanno proprietà differenti e possono favorire
una particolare classe di processi. Prima di scegliere l'algoritmo da usare in una
specifica situazione occorre considerare le caratteristiche dei diversi algoritmi.
Per il confronto tra gli algoritmi di scheduling della CPU son stati suggeriti molti criteri.
Le caratteristiche usate per il confronto possono incidere in modo rilevante sulla scelta
dell'algoritmo migliore. Di seguito riportiamo alcuni criteri:
• Utilizzo della CPU. La CPU deve essere più attiva possibile. Teoricamente,
l'utilizzo della CPU può variare dallo 0 al 100 per cento. In un sistema reale può
variare dal 40 per cento, per un sistema con poco carico, al 90 per cento per un
sistema con utilizzo intenso.
• Produttività. La CPU è attiva quando si svolge un lavoro. Una misura del lavoro
svolto è data dal numero dei processi completati nell'unità di tempo: tale misura
è detta produttività (throughput). Per processi di lunga durata questo rapporto
può essere di un processo all'ora, mentre per brevi transazioni è possibile avere
una produttività di 10 processi al secondo.
• Tempo di completamento. Considerando un processo particolare, un criterio
importante può essere relativo al tempo necessario per eseguire il processo
stesso. L'intervallo che intercorre tra la sottomissione del processo e il
completamento dell'esecuzione è chiamato tempo di completamento (turnaround
time), ed è la somma dei tempi passati nell'attesa dell'ingresso in memoria, nella
coda dei processi pronti, durante l'esecuzione nella CPU e nel compiere
operazioni di I/O.
• Tempo di attesa. L'algoritmo di scheduling della CPU non influisce sul tempo
27impiegato per l'esecuzione di un processo o di un operazione di I/O; influisce
solo sul tempo di attesa nella coda dei processi pronti. Il tempo d'attesa è la
somma degli intervalli d'attesa passati nella coda dei processi pronti.
• Tempo di risposta. In un sistema interattivo il tempo di completamento può non
essere il miglior criterio di valutazione: spesso accade che un processo emetta
dati abbastanza presto, e continui a calcolare i nuovi risultati mentre quelli
precedenti sono in fase d'emissione. Quindi, un'altra misura di confronto è data
dal tempo che intercorre tra la sottomissione di una richiesta e la prima risposta
prodotta. Questa misura è chiamata tempo di risposta, ed è data dal tempo
necessario per iniziare la risposta, ma non dal suo tempo di emissione.
Generalmente il tempo di completamento è limitato dalla velocità del dispositivo
d'emissione dati.
Utilizzo e produttività della CPU si devono aumentare al massimo, mentre il tempo di
completamento, il tempo d'attesa e il tempo di risposta si devono ridurre al minimo.
Nella maggior parte dei casi si ottimizzano i valori medi; in alcune circostanze è più
opportuno ottimizzare i valori minimi o massimi, anziché i valori medi; ad esempio, per
garantire che tutti gli utenti ottengano un buon servizio, può essere utile ridurre al
massimo tempo di risposta.
3.2.4 Algoritmi di scheduling
• Scheduling in ordine d'arrivo
• Scheduling per brevità
• Scheduling per priorità
• Scheduling circolare
• Scheduling a code multiple
3.3 Job Manager
In questo paragrafo viene descritto lo scenario in cui andrà a definirsi l'attività di
28tirocinio.
Con Job Manager o anche detti Batch System si intende tutti quegli applicativi che si
occupano della gestione dei processi sottoposti ad un calcolatore o ad un insieme di
calcolatori collegati tra loro, i così detti cluster.
In maniera molto semplificata un Job Manager può essere visto come il sistema di
gestione della CPU di un sistema operativo con la capacità di gestire molteplici risorse
sia del calcolatore su cui risiede il Job manager che di altri calcolatori che tramite rete
mettono a disposizione le loro risorse computazionali.
Le risorse gestite da un Job Manager posso essere di tipo hardware e software, infatti il
Job Manager di un sito di calcolo ha in gestione le CPU, la memoria RAM e i dischi
fissi presenti sui calcolatori; inoltre il Job Manager si occupa di gestire anche le risorse
software necessarie di volta in volta ai job a lui sottomessi, infatti possono essere
richieste librerie o sistemi operativi specifici per l'esecuzione di un determinato job.
I Job Manager per svolgere il loro compito di “organizzatori del sito” sfruttano
principalmente le code, in tali code vengono inseriti i vari job sottomessi al sito di
calcolo per poi essere eseguiti.
Le code possono essere organizzate e servite in moltissimi modi diversi, infatti tramite
diversi algoritmi, diverse policy e tramite l'uso di preemption e di QoS i job vengono
serviti con criteri ben precisi e definiti dall'amministratore del sito.
I Job Manager per prima cosa devono essere configurati in modo da poter conoscere le
risorse a disposizione del sito così da poterle distribuire hai vari processi in modo
ottimale.
I Job Manager per la gestione delle code si avvalgono di un altro applicativo in diretta
collaborazione con il Job Manager stesso i così detti Job Scheduler, è proprio sull'analisi
e configurazione ottimale di tali applicativi che si snoderà il percorso pratico dell'attività
di tirocinio. In particolare andremo ad analizzare principalmente due Job Scheduler:
Maui e Moab, secondariamente andremo ad analizzare le principali caratteristiche di un
terzo Job Scheduler: LSF.
293.3.1 Algoritmi di assegnazione dei nodi
Mentre la priorità dei job permette al sito di calcolo di determinare quale job eseguire, le
policy di allocazione dei nodi permettono al sito di specificare quale è lo stato delle
risorse disponibili e come può essere allocato a ciascun job.
L'algoritmo usato per l'assegnazione delle risorse è specificato nel file di
configurazione, più precisamente per quanto riguarda Maui e Moab nel parametro:
NODEALLOCATIONPOLICY
Da Maui e Moab vengono messi a disposizione più algoritmi che permettono di
eseguire la selezione delle risorse su canoni di valutazione diversi.
FIRSTAVAIABLE, LASTAVAIABLE, MACHINEPRIO, CPULOAD,
MINRESOURCE, CONTIGUOUS, MAXBALANCE, FASTEST and LOCAL
Altri tipi di algoritmi possono essere aggiunti attraverso estensioni di librerie.
Ora analizziamo come questa servizio offerto da Maui e Moab può essere al meglio
sfruttato, abbiamo osservato che una gestione dell'allocazione delle risorse diviene
fondamentale soprattutto in alcune situazioni:
• nei sistemi eterogenei
• nei sistemi a nodi condivisi
• nei sistemi basati sulla prenotazione del nodo
• nei sistemi senza una connessione “illimitata”
Descriviamo ora le caratteristiche principali dei vari algoritmi.
• CPULOAD
I nodi vengono scelti sulla base del carico della CPU, o meglio, viene selezionato il
nodo maggiormente scarico. Tale algoritmo può essere applicato ai job che entrano in
esecuzione immediatamente, infatti, la valutazione del carico della CPU è una
30valutazione istantanea, se volessimo gestire job con partenza ritardata l'algoritmo
consigliato e il MINRESOURCE.
• FIRSTAVAIABLE
Questo algoritmo molto semplicemente assegna il primo nodo libero che è stato
elencato nel Resource Manager. Algoritmo molto veloce.
• LASTAVAIABLE
Questo algoritmo è un algoritmo “best fit in time” infatti minimizza l'impatto della
prenotazione dei nodi.
• MACHINEPRIO
Questo algoritmo permette di specificare la priorità di assegnazione dei nodi, è una
versione personalizzabile del MINRESOURCE.
• MINRESOURCE
Questo algoritmo seleziona il nodo con le caratteristiche e le risorse il più possibile
simili a quelle richieste da job.
• CONTIGUOUS
Questo algoritmo assegna i nodi in modo lineare uno dopo l'altro, era un algoritmo
richiesto dal Compaq RMS system.
• MAXBALANCE
Questo algoritmo tenta di allocare il più “bilanciato” set di nodi al job, la maggior parte
dei casi la misura per effettuare la scelta è data dalla velocità. Ad esempio se sono
richieste due CPU l'algoritmo tenta di assegnare CPU con la stessa velocità.
• FASTEST
Questo algoritmo seleziona il nodo che presenta la CPU più veloce.
• LOCAL
Questo è l'algoritmo di default, non ha nessun criterio particolare.
314 Grid
Il termine Grid Computing (calcolo a griglia) sta ad indicare un paradigma del calcolo
distribuito, di recente introduzione, costituito da un'infrastruttura altamente
decentralizzata e di natura variegata in grado di consentire ad un vasto numero di utenti
l'utilizzo di risorse (prevalentemente CPU e storage) provenienti da un numero
indistinto di calcolatori (di potenza spesso non particolarmente elevata) interconnessi da
una rete (Internet). Il termine “griglia” deriva dalla similitudine fatta dai primi ideatori
del Grid Computing secondo i quali in un prossimo futuro si sarebbe arrivati a poter
reperire risorse di calcolo con la stessa facilità con la quale oggi si può usufruire
dell'energia elettrica, ovvero semplicemente attaccandosi ad una delle tante prese
presenti nel nostro appartamento Power Grid.
Le prime definizioni di Grid Computing, di cui si sente spesso parlare come della
prossima rivoluzione dell'informatica, (come a suo tempo fu per il Word Wide Web),
risalgono di fatto a circa metà degli anni novanta.
Le griglie di calcolo vengono prevalentemente utilizzate per risolvere problemi
computazionali di larga scala in abito scientifico e ingegneristico (la cosiddetta e-
Science). Sviluppatesi originariamente in seno alla fisica delle alte energie, il loro
impiego è già da oggi esteso alla biologia, all'astronomia e in maniera minore anche ad
altri settori.
I maggiori player dell'ITC in ambito commerciale hanno già da tempo cominciato ad
interessarsi al fenomeno, collaborando ai principali progetti grid word-wide con
sponsorizzazioni o sviluppando propri progetti grid in vista di un utilizzo finalizzato al
mondo del commercio e dell'impresa.
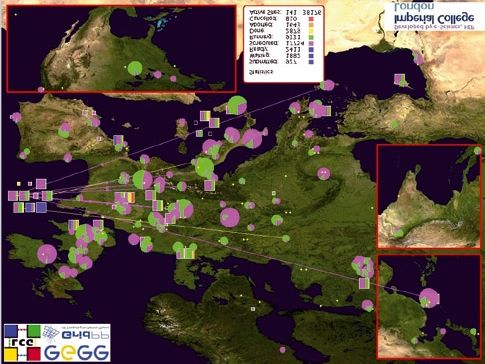
32Illustrazione 3: LHC Grid Project
L'idea del Grid Computing è scaturita dalla constatazione che in media l'utilizzo delle
risorse informatiche di un organizzazione è pari al 5% delle sue reali potenzialità. Le
risorse necessarie sarebbero messe a disposizione da varie entità in modo da creare
un'organizzazione virtuale (VO) con a disposizione un 'infrastruttura migliore di quella
che la singola entità potrebbe sostenere.
LHC@home è un progetto di calcolo distribuito partito il 1º settembre 2004 con lo
scopo di raccogliere dati per simulare l'attività del Large Hadron Collider, un progetto
del CERN di Ginevra in Svizzera per la costruzione di un acceleratore di particelle,
divenuto operativo nel settembre 2008.
4.1 Evoluzione del Grid Computing
Il progetto SETI@home, lanciato nel 1999 da Dan Werthimer, è un esempio molto noto
di un progetto, seppur semplice, di Grid Computing. SETI@home è stato seguito poi da
33tanti altri progetti simili nel campo della matematica e della microbiologia.
Illustrazione 4: The Directory Information Tree (DIT)
A differenza di quella utilizzata da SETI@home, attualmente una grid viene concepita
prevedendo un livello middleware fra le risorse di calcolo, dette computing element
(CE) e memoria, dette storage element (SE) e gli utenti della griglia stessa.
Lo scopo principale del middleware è quello di effettuare il cosiddetto match-making,
ossia l'accoppiamento tra le risorse richieste e quelle disponibili in modo da garantire il
dispatching dei job nelle condizioni migliori avendo sempre visibilità dello stato
dell'intera grid.
Attualmente, la più importante grid europea è quella del CERN di Ginevra che ora si
chiama EGEE (gLite è il nome del middleware che viene utilizzato; precedentemente
LCG e prima ancora DataGrid), sviluppato da un team italo-ceco e prevalentemente
presso l'IFN, Istituto Nazionale di Fisica Nucleare.
L'organismo di riferimento per lo sviluppo di omogeneità e standard dei protocolli usati
dalle grid è GGF (Global Grid Forum), che ha creato gli standard OGSA (Open Grid
Services Architecture). Nel 2004 è stato emanato WSRF (Web Services Resource
34Framework), che è un insieme di specifiche per aiutare i programmatori a scrivere
applicazioni capaci di accedere alle risorse di Grid.
Illustrazione 5: GridLab
4.2 Il Cluster Grid di Parma
Presso INFN di Parma sono attivi diversi gruppi di ricerca che si occupano di
simulazione numerica, particolarmente nei campi della Relatività Generale e della
Teoria di Gauge su Reticolo.
Riguardo la simulazione numerica della Relatività Generale, Parma fa parte di una
collaborazione nazionale che ha installato a Parma 2 cluster MPI:
• Albert100, installato nel 2002, è composto da 44 Dual PIII a 1.13 GHz, con
interconnessioni in Fast Ethernet.
• Albert2, installato nel 2004, è dotato di 16 Dual Opteron e Infiniband.
35Le simulazioni su reticolo della QCD vengono svolte prevalentemente con strumenti di
calcolo dei progetti APE, con cui Parma collabora attivamente, anche con cluster di PC.
Attualmente vi sono 2 installazioni:
• HAM, composto da 10 Dual Athlon a 2GHz con rete Myrinet.
• Exalibur, dotato di un blade con 7 DualXeon.
Esiste inoltre una farm di Calcolo Dipartimentale, senza supporto MPI, con 4 nodi di
calcolo a 64 bit e 3 nodi a 32 bit, a disposizione di tutti gli utenti locali del sito.
Infine, dal 2004, è attivo un sito INFN-Grid con 4 dual Xeon 2.4GHz dedicato
prevalentemente per il calcolo Mpi e per lo storage di dati delle Virtual Organization di
Theophys e ILDG (International Lattice Data Grid).
Il Resource Manager utilizzato da tutti i cluster (che ne fanno uso) è OpenPBS o
Torque/Maui.
Illustrazione 6: Il cluster Grid di Parma
365 Job Sheduler
L'obbiettivo di uno scheduler nel senso più ampio è quello di rendere gli utenti e gli
amministratori felici. Gli utenti desiderano la possibilità di specificare le risorse,
svolgere rapidamente il loro job e ricevere affidabile allocazione delle risorse. Gli
amministratori desiderano utenti soddisfatti e gestione semplice e completa. Così da
comprendere al meglio sia il carico di lavoro alla quale il loro sistema è sottoposto che
le risorse a loro disposizione. Questo include stato del sistema, statistiche dettagliate e
informazione su cosa sta avvenendo all'interno del sistema.
Gli amministratori dei siti necessitano di un completo set di comandi e funzioni che
permettano la gestione del sistema, la gestione degli utenti e la regolazione delle
statistiche.
I job scheduler sono componenti fondamentali di sistemi più ampi, i Sistemi Batch
(Batch system), tali sistemi si occupano dei meccanismi per sottomettere, lanciare e
tracciare un job all'interno di un pool di risorse condivise. Il servizio di scheduling
provvede a fornire un accesso gestito e centralizzato di tali risorse.
I job-scheduler spesso sono integrati in un batch-system, il batch system è colui che si
occupa di eseguire il match-making tra le richieste e le risorse, i batch-system
maggiormente utilizzati sono principalmente 4:
• LSF: (Load Sharing Facility), sviluppato da Platform, fa sia da batch-system che
da job-scheduler. E' il sistema attualmente in uso dal CNAF, è a pagamento.
• SGE: (Sun Grid Engine), sistema sviluppato da Sun a pagamento.
• TORQUE-MOAB: sviluppati dalla Cluster Resource inc., Moab è un scheduler a
pagamento.
• TORQUE-MAUI: in questo caso il batch-system è Torque mentre il job-
scheduler è Maui, sono entrambi open source. Vengono sviluppati dagli stessi
produttori di Moab.
La soluzione Torque-Maui è quella attualmente utilizzata dall'Università di Parma e sarà
37Puoi anche leggere

















































