Microservizi Andrea Fornaia, Ph.D - A.A. 2020/2021 Department of Mathematics and Computer Science - DMI Unict
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Microservizi
Andrea Fornaia, Ph.D.
Department of Mathematics and Computer Science
University of Catania
Viale A.Doria, 6 - 95125 Catania Italy
fornaia@dmi.unict.it
https://www.dmi.unict.it/fornaia/
A.A. 2020/2021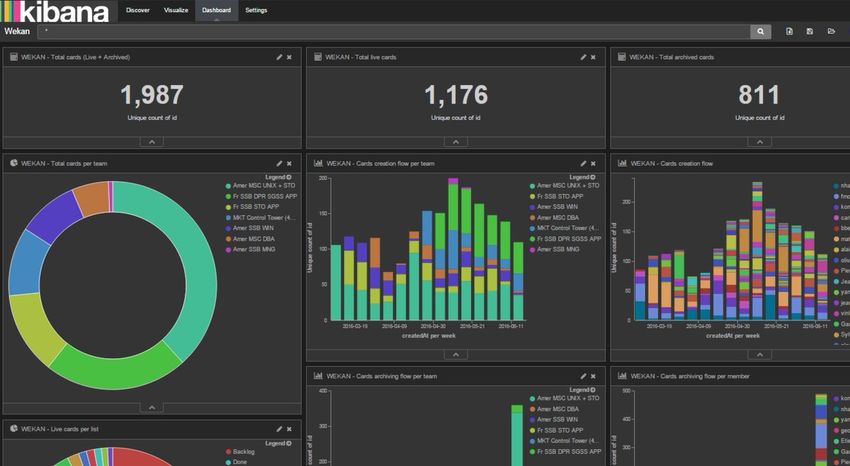
Definizione
• Architettura a Microservizi: design di un’applicazione come
insieme di servizi indipendenti a livello di deploy
• Una modifica in una parte del sistema non deve implicare
l’aggiornamento di tutta l’infrastruttura in produzione
• Un fallimento in una parte del sistema non deve
compromettere il funzionamento dell’intero sistema
• Possibile promuovendo il lasco accoppiamento:
– A livello funzionale (separation of concerns)
–
–
A livello di dati (persistenza decentralizzata)
A livello di sviluppo (piccoli team dedicati) 4
– A livello di processo di esecuzione (container/VM) FORZE
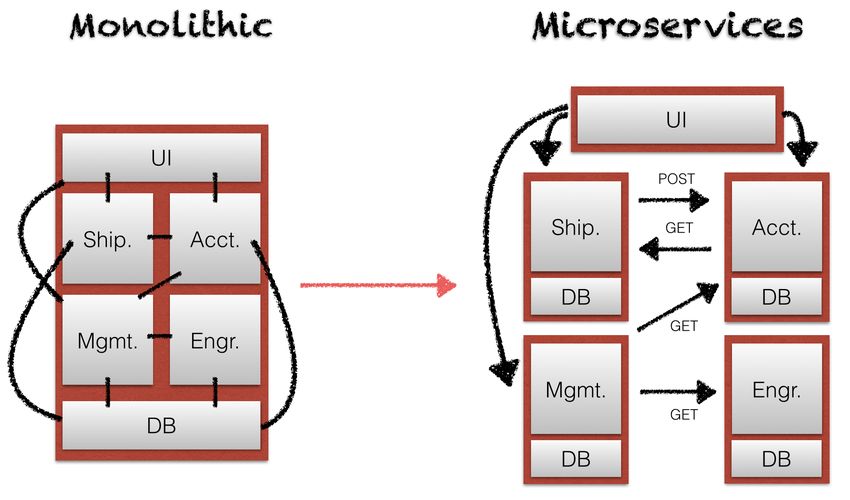
Monolite VS Microsevizi

Monolite VS Microsevizi [https://wordpress.stackexchange.com/questions/253635/are-there-any-initiatives-to-work-wordpress-as-microservices]
Esempio Monolite
Esempio Microservizi
Svantaggi di un monolite • Al crescere della dimensione del sistema la produttività degli sviluppatori diminuisce (complessità) • Difficile introdurre l’uso di nuove tecnologie • Se una parte del sistema va in errore, l’intero sistema ne risente (fault localization) • Se una parte del sistema viene aggiornata, bisogna fare il deploy dell’intera applicazione (EAR/WAR/JAR) • Se una parte del sistema consuma troppe risorse, l’intera applicazione deve essere replicata (scalabilità)
Scalabilità e ottimizzazione risorse
Un’applicazione monolitica Un’architettura a microservizi
esegue tutte le funzionalità esegue ogni funzionalità in un
in un singolo processo… servizio separato…
… e scala replicando il … e scala distribuendo i
“monolite” su più server. servizi tra più server,
replicandoli se necessario.
Replico solo le parti che richiedono più risorse
Vantaggi dello sviluppo a
Microservizi
• Servizi più semplici che fanno “una cosa sola e bene”
• Progetti separati (es. repo git diversi) di dimensioni ridotte
• Più facile per i nuovi sviluppatori comprendere il
funzionamento di un servizio
• Più facile gestire team indipendenti assegnati ad ogni servizio
• Più facile introdurre nuove funzionalità
• I servizi possono essere sviluppati con linguaggi e tecnologie
differenti
• Non ci si lega a lungo termine ad uno stack tecnologico
• Facilita l’adozione di tecniche di Continuous Delivery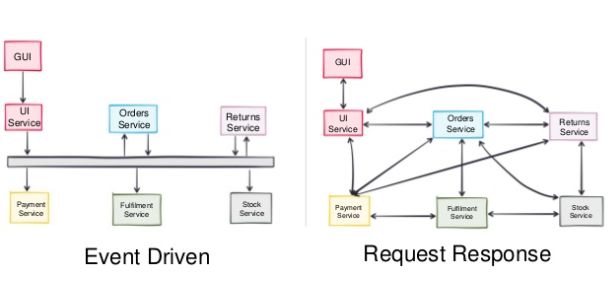
Eterogeneità e Decentralizzazione
Posts Friends Pictures
Document Graph Blob
Store DB Store
governance decentralizzata dei datiDeploy indipendente: VM e Container
Service isolation & deployment
(sia VM che container)
REGISTRY
Java:8
Centos:7
new cached IMAGES
instances & relations Java:8
text description base base Centos:7
CLIENT DEAMON
INSTANCES
run containers
code VMs
artifacts
HOST
colleaguesCloud Native Apps
e (tanti) altri…Quanto “Micro”?
• Tanto piccolo da svolgere un solo compito e bene
• Minore è la dimensione dei servizi, maggiori sono:
– i vantaggi: parti autonome
– gli svantaggi: aumenta la complessità
• Euristiche:
– Two Pizza Team (tutto il team deve essere sfamato con due
pizze americane)
– Tanto piccolo da poterlo rifare da zero in due settimane
• In realtà, è fondamentale:
– dividere ed organizzare i servizi attorno a concetti di business
– promuovere il lasco accoppiamento a più livelli (funzionale, dati,
sviluppo, deploy)
– allineare I servizi alla struttura organizzativaLegge di Conway
Any organization that designs a system (defined broadly) will produce a design
whose structure is a copy of the organization’s communication structure.
Melvyn Conway, 1967Cross-functional teams
Il team di sviluppo ha la responsabilità della
gestione del proprio software in produzione (“you
build, you run it”)
– Resa più semplice dalla maggiore granularità dei
serviziQuindi devo usare i microservizi?
• I microservizi aiutano a gestire sistemi complessi…
• … ma introducono allo stesso tempo tutta la complessità dei
sistema distribuiti
– Inter-service communication – Monitoring
– Automated deployment – Failure
– Testing – Eventual ConsistencyTransazioni Distribuite Estratto del dependence graph (creato con Jaeger) dell’architettura a microservizi di Uber. Ogni nodo è un microservizio, ogni arco una dipendenza (comunicazione) tra due microservizi. Il diametro di ogni nodo è proporzionale al numero di microservizi ad esso connessi; lo spessore di un arco è proporzionale al volume del traffico passante per l’arco. Viene inoltre evidenziata un’ipotetica transazione distribuita scaturita da una richiesta di un utente e servita dalla cooperazione di più microservizi
Produttività & Complessità
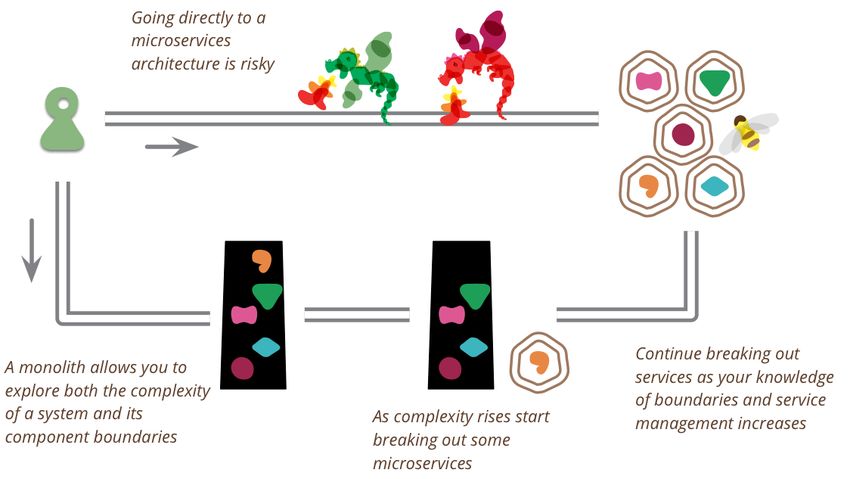
Monolith First
You shouldn’t start with a microservices architecture. Instead, begin with a monolith,
keep it modular, and split it into microservices once the monolith becomes a problem.
----
Martin FowlerDividere il monolite in base al
dominio (Bounded Context)
Domain-Driven Design (Evans, 2003)
[https://martinfowler.com/bliki/BoundedContext.html]Dividere il monolite in base alla
indipendenza di deploy
• Dividere le funzionalità in modo tale creare unità di cui
è possibile fare il deploy in maniera indipendente
• Creare un servizio per team autonomo tipicamente è
la soluzione migliore
• Evitare di dividere componenti che vengono spesso
aggiornate (e ”deployate”) assiemeComplessità e strumenti
Componente/Ruolo Strumento
RESTful Web Service Spring Boot, Flask
Message Queue RabbitMQ
Service Discovery Netflix Eureka
Dynamic Routing e Load Balancer Netflix Ribbon
Circuit Breaker Netflix Hystrix
Monitoring Netflix Hystrix dashboard e Turbine
API Gateway (Edge Server) Netflix Zuul
Central Configuration Server Spring Cloud Config Server
Authentication e API protection Spring Cloud + Spring Security OAuth2
Centralised log analysis Logstash, Elasticsearch, Kibana (ELK)
Service isolation/deployment Docker, Vagrant, AWS, Openstack…
Data Store MySQL, MongoDB, Redis, Cassandra,
Neo4j…Esempio
• Vogliamo creare un’applicazione per permettere agli studenti del
corso di “Ignegneria del Software” di esercitarsi in vista dell’esame.
• R1: Lo studente, dopo aver inserito un alias identificativo (es.
matricola), potrà rispondere ad una o più domande tipiche d’esame
(a risposta chiusa), ottenendo l’esito “corretto” o “sbagliato”.
• R2: Si vuole inoltre incoraggiare lo studente ad esercitarsi
giornalmente tenendo traccia dei progressi e fornendo dei badge di
ricompensa:
– es. ”costante: effettuato l’accesso per 7 giorni di fila”
– es. “instancabile: risposto a 30 domande in un giorno”
– es. “preciso: risposto a più di 100 domande con correttezza dell’80%”Iniziamo con un Monolite • Cominciamo lo sviluppo implementato il primo requisito funzionale (R1). • Il requisito suggerisce un servizio che chiameremo Training. • Scegliamo un database relazionale (MySQL)
Training Service
Training Service
UI
Business Logic Business Logic
(Training) (Auth)
Training / Auth
DB
componente funzionalità DBConsiderazioni
• Possiamo usare Spring Boot per la creazione di servizi REST indipendenti
• Per il momento le funzionalità di identificazione dell’utente sono minimali,
non è necessaria la creazione di un servizio a parte (es. Auth Service)
• Assumiamo che le domande siano state precaricate nel DB con strumenti
esterni
• Attualmente non sono richieste funzionalità di gestione delle domande
(Aggiunta/Modifica/Cancellazione), quindi non è richiesta una business
logic separata
• Se in futuro fossero aggiunte le operazioni CRUD sulle domande, si
potrebbe separare la nuova business logic in un servizo separato (es.
Question Service) assieme ai suoi dati
– Richiederebbe la divisione delle tabelle in DB distintiAggiunta del Badge Service
Training Service Badge Service
UI
Business Logic Business Logic Business Logic
(Training) (Auth) (Badge)
Training / Auth Badge
DB DB
• Stiamo facendo evolvere il sistema aggiungendo la gestione dei badge
• Invece di aggiungere altre funzionalità al sistema esistente (monolite)
decidiamo di creare un servizio indipendente
• Inseriamo un controllo decentralizzato dei dati: ogni servizio gestisce i
propri dati
• Le funzionalità saranno accessibili tramite l’UI di Training (per ora)
• I servizi adesso devono comunicare. Come?Coordinamento tra servizi
Supponiamo di voler realizzare un business process per la registrazione
di un nuovo utente, dovendo coordinare più microservizi
Registrazione utente
Crea record cliente
Inizializza punti Spedisci kit di Invia email di
fedeltà benvenuto benvenuto
Registrazione
completataDatabase Condiviso
Servizio Punti
Servizio Clienti DB Servizio Spedizione
Clienti
Servizio Email
Tecnica di integrazione spesso usata per la sua semplicità.
Usato anche per integrare sistemi di terze parti.
I dati vengono scritti e letti all’interno delle entità del database condiviso.
Espone i dettagli interni (anche a terze parti).
Una modifica alla rappresentazione dei dati si ripercuote su tutto il sistema.
L’intero DB diventa di fatto un’API.
Troppo semplice creare delle “eccezioni alla regola”, perdendo il lasco accoppiamento.Orchestrazione
inizializza punti fedeltà
Servizio Punti
crea cliente spedisci kit
Servizio Clienti Servizio Spedizione
invia email di benvenuto
Servizio Email
Viene utilizzata una comunicazione request-response (sincrona o asincrona).
Interfaccia di comunicazione esplicita (API), maggiore separazione.
La logica di coordinamento risiede in uno dei servizi (Servizio Clienti).
Si possono usare tecnologie di RPC (RMI, CORBA).
Si possono usare tecniche basate su API REST.Coreografia
subscribe
Servizio Punti
crea
cliente publish subscribe
Servizio Clienti Servizio Spedizione
cliente creato
Event Bus
subscribe
Servizio Email
Viene utilizzata una comunicazione event-based (asincrona) basata su message broker.
Detto anche event-based architecture o reactive system.
La logica di coordinamento è decentralizzata, ogni servizio sa come reagire all’evento.
”Servizio Clienti” si limita a generare l’evento (fatto compiuto).
Potrebbe non sapere chi lo consumerà.
Nuovi consumatori possono essere aggiunti per cambiare il comportamento del sistema.Event Driven VS Request Response
Comunicazione ibrida
Combinare event bus e REST API
GET /esito/{id}
5
Training Service Badge Service
2 6
1 Mostra Domanda
Controlla Esito
Ottieni Risposta
Assegna Punti
3 Mostra Esito
Aggiorna Badge
Genera Evento
4 sync
Answer async
Event
Message Broker
L’evento potrebbe non contenere tutte le informazioni necessarie (minimale). Badge
richiederà ciò che gli serve in risposta all’evento usando le API REST di Training. Gli
identificatori vengono usati per operare in maniera disambigua sulla stessa richiesta.Separare la UI
Prendi
contenuto
browser statico
UI Server Nginx,
8080
http://localhost:8080 Serve static content Tomcat
(HTML, JS, CSS) …
link link
Trainig Service Badge Service
9090 9091
REST API REST API
Business Logic Business Logic
Training Badge
DB DB
Message Broker
RabbitMQService Discovery
• Allo stato attuale ogni riferimento ad un servizio è hardcoded (es.
Training Service: http://localhost:9090).
• Questo causa problemi di scalabilità:
– se un servizio viene spostato dovrei aggiornare ogni riferimento
– se un servizio viene replicato, contatterei sempre lo stesso
• Un Service Discovery (es. Netflix OSS Eureka, integrato con
Spring Cloud) permette di risolvere il problema, associando un
nome, invece che un indirizzo in rete, a ciascun servizio.
• Un sistema di Service Descovery è composto da:
– Service Registry: il registro che associa nomi a indirizzi (unico)
– Registry Agent: usato da ciascun servizio per registrarsi (all’avvio)
– Registry Client: usato da ciascun servizio per risolvere i nomiService Discovery
browser
UI Server
8080
http://localhost:8080 Serve static content
(HTML, JS, CSS)
9090 9091
http://training/esito
Trainig Service Badge Service
Registry Registry Registry Registry
Agent Client Client Agent
risolvi http://training
registrati Service registrati
Registry
Message BrokerLoad Balancing • Che succede se abbiamo più istanze di uno stesso servizio? • Serve un load balancer in modo da distribuire il carico delle richiesta tra più istanze • Netflix OSS Ribbon (sempre in Spring Cloud) è un load balancer client-side integrato con Eureka • Più istanze di uno stesso servizio (in ascolto su porte diverse, es. http://localhost:9090 e http://localhost:9092) verranno registrate con lo stesso nome (es. training) • In fase di risoluzione, Eureka manderà al client tutte le risoluzioni per il nome richiesto • Lato client, Ribbon (usando una strategia round robin) sceglierà solo una di questa per risolvere il nome • Il meccanismo è client side ma trasparente al microservizio
Load Balancing
Service Registry Table browser
UI Server
trainig: http://localhost:9090 8080
http://localhost:9092 Serve static content
badge: http://localhost:9091 (HTML, JS, CSS)
9090 9091
http://training/esito Load
Trainig Service Balancer Badge Service
9092 risolvi http://training
Trainig Service Service lista completa risoluzioni
Registry
Message BrokerAPI Gateway
• Service Discovery e Load Balancing nel backend
promuovono il lasco accoppiamento, rendendo il
sistema scalabile
• Al momento però:
– il client web (sul browser) non può interagire con il
service discovery e non beneficia del load balancing
(i riferimenti sono ancora hardcoded)
– non abbiamo al momento un servizio di
autenticazione che gestisca il contesto distribuito
– le API REST sono fortemente accoppiate con
l’architettura del sistema. Qualsiasi modifica si
ripercuoterebbe anche sui client (struttura interna
esposta)API Gateway • Netflix OSS Zuul è un API Gateway disaccoppia i client dalle API REST dei singoli microservizi • Funge da router per le richieste da parte dei client, associando le API esterne (applicazione unica) alle API interne (vari microservizi) • Sarà un microservizio separato in ascolto su di una porta specifica (es. 8000)
API Routing
/nuovadomanda --> training/domanda
/risposta --> training/risposta
/badge/{id_utente} --> badge/lista/{id_utente}
Integrando Zuul, Eureka e Ribbon, le richieste vengono risolte e
smistate ad una delle possibili istanze del servizio richiesto,
ottenendo così anche il service descovery e il load balancing
1. Il client web chiederà http://localhost:8000/nuovadomanda
2. L’API gateway farà il routing della richiesta su http://training/domanda
3. L’API gateway chiede al Service Registry di risolvere training
4. Il Service Registry fornisce la lista di possibli risoluzioni
5. Il Load Balancer ne sceglie una, es. http://localhost:9092
6. La richiesta viene inoltrata a http://localhost:9092/domandaAPI Gateway
browser
8080
UI Server
8000
API Gateway
LB RC
9090 9091
Trainig Service Badge Service
9092
Trainig Service Service
Registry
Message BrokerEdge Server • API Gateway può essere usato come unico punto di accesso per l’intero sistema a microservizi (edge server) • Altri servizi di accesso, come autenticazione o filtro possono essere inseriti a questo livello (es. Spring Security OAuth2) • Non bisogna esagerare con le responsabilità, richieremmo di creare un single point of failure
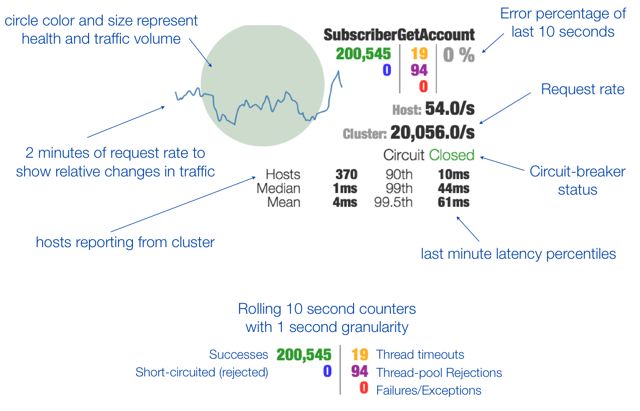
Circuit Breaker
• I servizi possono fallire:
– andare in errore
– non rispondere in tempo
• Cicuit Breaker isola temporaneamente un servizio
non funzionante
• Wrapper della chiamata remota (serve un
intermediario, es. API Gateway)
• Se il numero di timeout supera una soglia, il circuito
viene aperto
• Le successive richieste seguiranno un fallback
path (messaggio di errore di default, chiamata ad
altra istanza del servizio…)
• Il circuito verrà chiuso dopo alcuni tentativi andati a
buon fine (test stabilità)
• Netflix OSS Hystrix fornisce un’implementazione
• Turbine aggrega le informazioni sullo stato dei
circuiti su più servizi (monitoraggio)
• Hystrix Dashboard per visualizzare lo stato globale
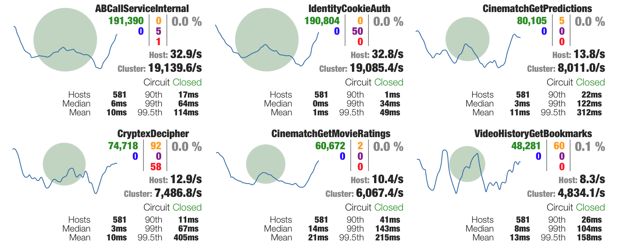
[https://martinfowler.com/bliki/CircuitBreaker.html]Hystrix Dashboard [https://medium.com/netflix-techblog/hystrix-dashboard-turbine-stream-aggregator-60985a2e51df]
Aggregazione e analisi dei Log
ElasticSearch
LogStash
Kibana
• Mantenere i servizi sotto controllo
• Analisi degli eventi e delle prestazioni del sisema
• Ricostruzione situazioni di errore può essere complesso in un sistema distribuito
• Soddisfare una richiesa può coinvolgere più microservizi (workflow)
• L’dentificativo di una richiesta può essere usato per ricostruire il flusso di operazioniKibana Dashboard
Stateless Microservices • Service discovery, load balancing ed API Gateway non bastano a garantire la scalabilità • I microservizi devono essere stateless: non devono mantenere dati o uno stato in memoria (es. sessione utente) • Evitare affinità di sessione: forza tutte le richieste di uno stesso utente ad essere inoltrate alla stessa istanza di servizio (poiché ha mantenuto internamente le informazioni sul contesto)
Affinità di sessione
es. “lo studente deve rispondere a due domande prima di ottenere il risultato”
answer 1, answer 2 answer 1, answer 2
Load Balancer Load Balancer
answer 2 answer 1 answer 2
answer 1
Trainig Trainig Trainig Trainig
Service 1 Service 2 Service 1 Service 2
cnt
cntDB condiviso tra le istanze dello
stesso servizio
• Nel nostro esempio, i database erano incorporati
(embedded) con il servizio, impedendo una
corretta scalabilità
• Il database deve essere esterno al servizio
(istanza separata) ma ad uso esclusivo del
servizio
• Tutte le istanze di uno stesso servizio devono
condividere lo stesso database
• La scalabilità del database è tipicamente gestita
dal database engine, che fornirà un unico punto
di accesso per le istanze (trasparente)Servizi diversi, DB diversi • Promuove lasco accoppiamento (a livello dei dati) • Altrimenti il DB diventerebbe una “API condivisa”
Riferimenti
• M. Fowler: “Microservices: a definition of this new architectural item”
https://martinfowler.com/articles/microservices.html
• M. Fowler: “Microservices Resource Guide”
https://martinfowler.com/microservices/
• M. Fowler: “Microservice Premium”
https://martinfowler.com/bliki/MicroservicePremium.html
• S. Newman: “Building Microservices”. O’Reilly, 2015
• M. Macero: “Learn Microservices with Spring Boot”. Apress, 2017
• B. Stopford: “Microservices in the Apache Kafka Ecosystem”
https://www.slideshare.net/ConfluentInc/microservices-in-the-apache-
kafka-ecosystem
• https://blog.avanscoperta.it/2020/06/11/about-bounded-contexts-and-
microservices/
• Y. Shkuro: Mastering Distributed TracingPuoi anche leggere

















































