Il codice genetico - Documenti Universitari
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù

Il codice genetico

Cosa è il genoma?
Il genoma di un organismo è ciò che contiene tutte
le informazioni biologiche necessarie alla
costruzione ed al mantenimento di quell’ organismo.
DNA o RNA (virus)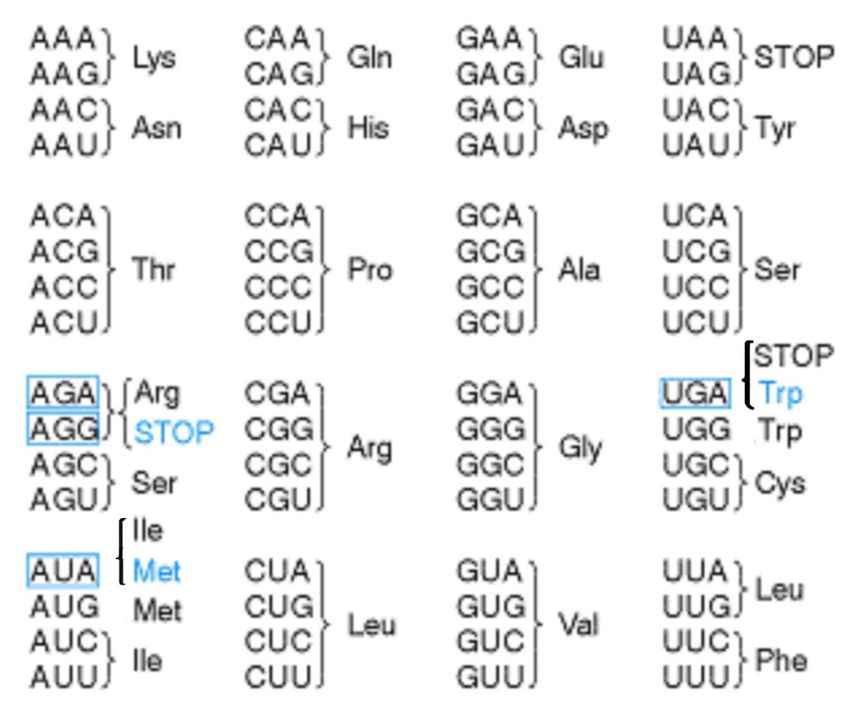
Genomica comparativa
Genoma Umano
Genoma Umano
•Genoma nucleare
•Dimensioni: 3 x 10 9 coppie di basi (bp)
Contenuto di DNA di una
cellula aploide (C)
• 22 autosomi + 2 cromosomi sessuali (molecole lineari di DNA di dimensioni comprese fra 50 e 250 megabasi)
• Genoma mitocondriale umano • Dimensioni: ~ 17000 coppie di basi • DNA circolare • 37 geni(che codificano per 13 polipeptidi sintetizzati dal ribosoma mitocondriale, 22 tRNA e 2 rRNA) • 0,05% del DNA codificante dell’organismo
DIFFERENZE TRA GENOMA NUCLEARE E MITOCONDRIALE
DIFFERENZE NEL CODICE GENETICO TRA GENOMA NUCLEARE E MITOCONDRIALE

I 13 geni che codificano per proteine codificano tutti per componenti del sistema della catena respiratoria
DISORDINI A CARICO DI PROTEINE CODIFICATE DA MITOCONDRI
Corredo diploide di cromosomi non
duplicati nell’uomo:
sei miliardi di bp
2 nucleotidi adiacenti occupano uno spazio
di 0,34 nm
Quindi
sei miliardi di nucleotidi corrispondono ad
una molecola lunga 2 metriI DIVERSI LIVELLI DI ORGANIZZAZIONE DELLA CROMATINA
1995: sequenziamento del genoma di Haemophilus Influenzae, presso the Institute for Genomic Research (TIGR), by Craig Venter TIGR ha sequenziato successivamente più di 50 genomi microbici
Progetto Genoma Umano
(Human Genome Project HGP)
Completato nel 2003, dopo 13 anni
(USA, UK, Francia Germania, Cina e altri)
Goals:
-Determinare la sequenza dell’intero genoma umano
-Identificare tutti i geni del DNA umano
-Immagazzinare queste informazioni su database
-Sviluppare programmi per l’analisi di questi dati
-Stabilire principi etici e legali per l’utilizzo di
questi datiHuman Genome Project ha prodotto: • 2.6 miliardi di coppie di basi. • Utilizzando caratteri di un normale libro 60 nucleotidi/10 cm 2.6 miliardi di nucleotidi = 5000 Km • 3000 libri di medie dimensioni!!!!!!!
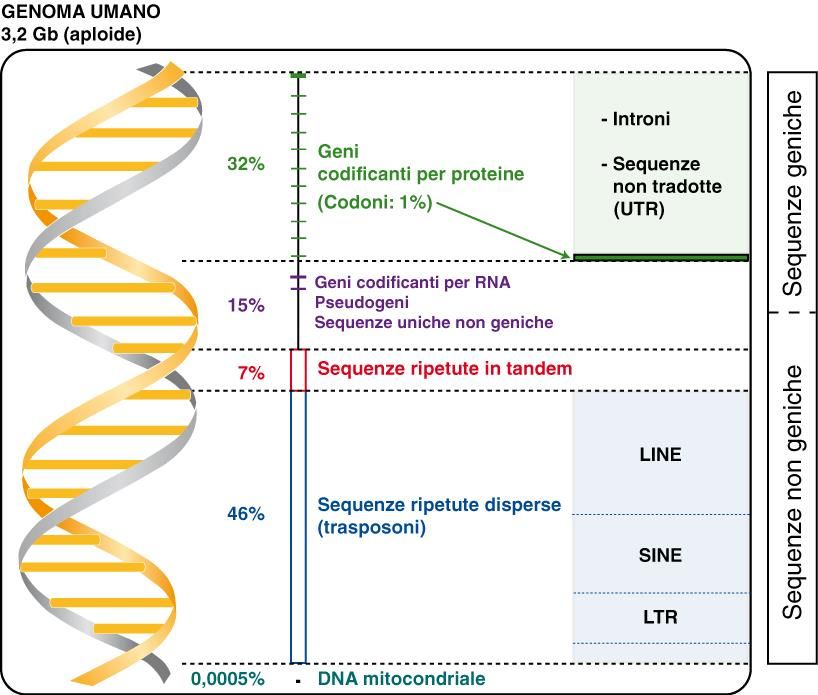
Risultati del progetto genoma: I geni umani sono circa 21000, contengono 8.8 esoni ognuno dei quali è lungo all'incirca 170bp. Il numero di introni è in media 7.8 con una lunghezza media di 5420bp. Il genoma umano è lungo circa 3200Mb, di cui solo 48Mb di DNA codificante (1,5%) 1152Mb (36%) "gene related" DNA (Introni, UTR, Pseudogeni, frammenti genici) 2000Mb costituiscono il DNA formato da sequenze ripetute intersperse chiamate LINE (21%), SINE (15%), LTR (9%), Transposoni a DNA (3%), sequenze ripetute in tandem anche dette microsatelliti (3%)
Collaborazione dell’Italia al Progetto Genoma Per quanto riguarda l’Italia, ha partecipato al Progetto Genoma Umano dal 1988 al 1994. Il coordinamento era stato affidato a Renato Dulbecco e i finanziamenti derivavano dal Cnr, per un totale di 10 miliardi di lire in sei anni. La ragione per la fine della partecipazione italiana a questo progetto `e stata dovuta alla sospensione dei finanziamenti dal 1995 in poi.
Le sequenze di DNA scoperte sono brevettabili? I brevetti vengono concessi in base a quattro caratteristiche. L’inventore deve aver identificato una sequenza genetica nuova, deve specificare il ruolo di questa sequenza e la funzione di questa in natura, deve descriverla in modo che un altro specialista del campo possa utilizzarla per i propri scopi. I prodotti della natura non sono patentabili, e per quanto riguarda il DNA, il brevetto pu`o essere concesso solo su sequenze isolate, purificate o modificate in maniera tale da non esistere in natura. …giudicato invalidi i brevetti concessi riguardo ai geni BRCA1 e BRCA2, che sono usati per la produzione di kit diagnostici dei tumori al seno e alle ovaie. l’accusa che i brevetti ottenuti da queste ultime sullo sfruttamento esclusivo dei geni BRCA1 e BRCA2 – le cui mutazioni sono responsabili dell’insorgenza di tumori al seno e alle ovaie – ostacolassero la libera circolazione delle idee nella ricerca scientifica, in violazione del primo emendamento della costituzione Usa. Già la decisione di primo grado, resa da una corte di New York, aveva giudicato invalidi i brevetti concessi riguardo a quei geni, che sono usati per la produzione di kit diagnostici dei tumori al seno e alle ovaie.
Progetto genoma: problemi etici Il comportamento etico da osservare `e che l’analisi genetica venga fatta solo su esplicita richiesta dell’interessato e i risultati devono essere coperti da privacy. L’8 febbraio 2000 il Presidente Clinton ha firmato un ordine esecutivo che proibisce l’utilizzo dell’informazione genetica nelle procedure che portano all’assunzione al lavoro, alla promozione lavorativa, alla stipulazione di contratti assicurativi.
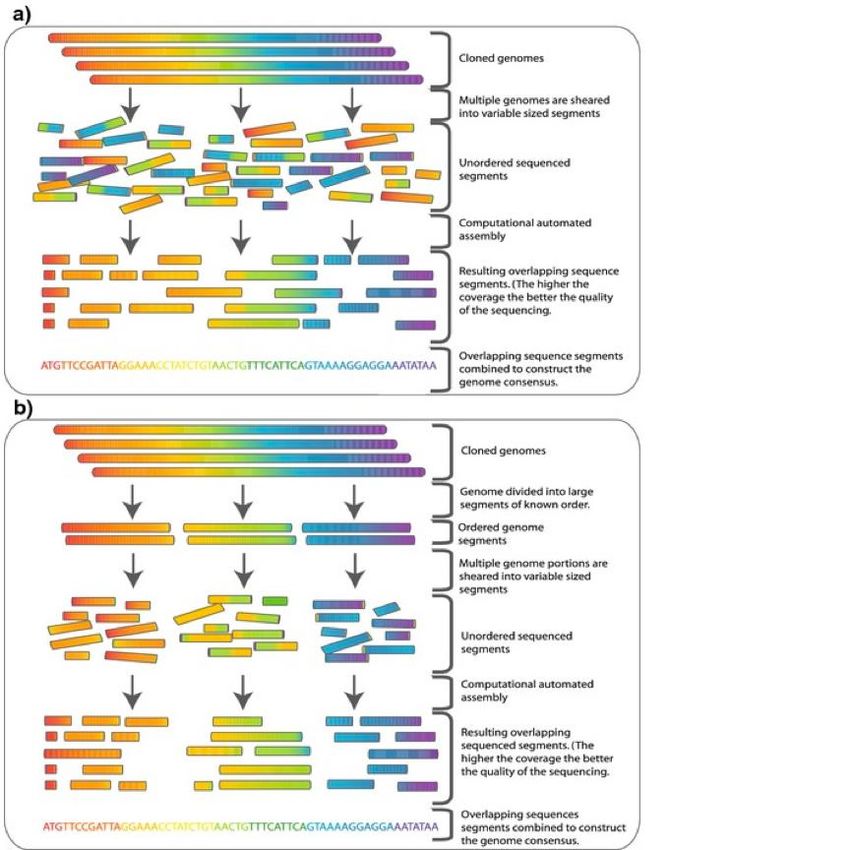
Le sequenze vengono assemblate mediante l’approccio shotgun Il DNA è frammentato ed ogni frammento è sequenziato. L’intera sequenza è assemblata cercando sovrapposizioni tra le singole sequenze. Una sovrapposizione di centinaia di basi ci dice che le sequenze possono essere allineate.
Problema nell’approccio shot-gun:esistenza nel genoma di sequenze ripetute
whole genome shotgun sequencing hierarchical shotgun sequencing
next-generation sequencing The classical shotgun sequencing was based on the Sanger sequencing method: this was the most advanced technique for sequencing genomes from about 1995–2005. The shotgun strategy is still applied today, however using other sequencing technologies, called next-generation sequencing (NGS)These technologies produce shorter reads (anywhere from 25–500bp) but many hundreds of thousands or millions of reads in a relatively short time (on the order of a day). This results in high coverage, but the assembly process is much more computationally intensive. These technologies are vastly superior to Sanger sequencing due to the high volume of data and the relatively short time it takes to sequence a whole genome
I Genomi Eucariotici
97 genomi eucariotici completati
(Ottobre 2008). La scelta dei genomi
da sequenziare è dettata da vari
criteri:
Organismi modello
- facilità di manipolazione (lievito, Drosophila, C.
elegans, Ciona, Danio)
- modelli di studio per malattie umane
(scimpanzé, topo, ratto)
Specie parassite e patogene di interesse per
la salute/ economia umana
- Identificazione di marcatori molecolari utili per
la diagnosi della patologia o per identificare
target per la messa a punto di nuovi farmaci (es.
Plasmodium, tripanosomi, etc.)
Organismi “filogeneticamente interessanti
- Organismi chiave per comprendere la storia
evolutiva di un gruppo tassonomico (es.
anfiosso, Ciona)
Proprietà intrinseche del genoma
- genoma relativamente piccolo rispetto ad altri
organismi evolutivamente vicini, come per
Arabidopsis thaliana e Fugu rubripes) 25
http://www.ensembl.orgImportanza dei progetti genomici • Cataloghi contenenti la descrizione di ogni singolo gene di un genoma (anche di funzione ignota) • Questi cataloghi conterranno non solo le sequenze codificanti di ogni gene ma anche le sequenze delle rispettive regioni regolative • Descrizione globale delle attività molecolari di una cellula vivente e dei modi in cui queste attività sono controllate
A cosa servono questi cataloghi? • Genoma con sequenza nota: ottengo una copia del gene desiderato semplicemente prelevandola dal catalogo • Isolamento e utilizzazione geni importanti (responsabili di malattie ereditarie, prodotti proteici di rilevanza industriale) • Individuazione di ruoli per quello che chiamiamo DNA non codificante attraverso la comparazioni di tali regioni del DNA in genomi provenienti da organismi diversi
Applicazioni della ricerca genomica
• Medicina molecolare
– Diagnosi delle malattie
– Individuazione della predisposizione
genetica per una malattia
– Creazione di farmaci specifici basati sul
profilo genetico del paziente
– Terapia genica
– Creazione di farmaci basati su informazioni
molecolari• Bisogna anche tenere a mente che sebbene sia prassi comune parlare della sequenza del genoma umano ci sono in realtà molte sequenze perché ogni individuo, eccetto i gemelli identici, ha la propria versione. • Le differenze tra individui diversi sono dovute principalmente a polimorfismi di singola base (SNPs). • Sono stati identificati più di 1,4 milioni di SNPs, una media di circa 1 ogni 2000 coppie di basi (alcuni autori valutano le differenze 1/300) • Molti SNPs non hanno effetto sulla funzionalità del genoma mentre altri hanno un effetto • Per esempio 60.000 SNPs si trovano all’interno di geni ed hanno un impatto sull’attività di tali geni, determinando quelle differenze che rendono ognuno di noi un organismo unico.
SNPs
single nucleotide polymorphisms
• Variazioni puntiformi della sequenza
tra due copie del genoma
• Per un SNP un individuo può essere
– Omozigote T/T o C/C
– Eterozigote T/C2 diverse forme alleliche (A e G) per un SNP 3 diversi aplotipi. I due SNP in colore sono sufficienti per identificare (Tag) ogni aplotipo. Ciò vuol dire che se un cromosoma ha A e T, allora possiede il primo aplotipo. Diversi aplotipi sono relativi a corrispondenti regioni cromosomiche nella popolazione
Qual è l’origine di un aplotipo?
A partire da due cromosomi ancestrali
mediante RICOMBINAZIONE
nel corso delle generazioni
si otterranno cromosomi differenti.Come misurare la Complessità biologica ?
La complessità biologica può essere “misurata” in diversi modi, ad es.
sulla base della diversità di tipi cellulari, della complessità dei circuiti
del cervello,……o del n° teorico di stati dell’espressione genica.
Ipotizzando N geni umani e supponendo che ciascuno possa essere
presente in due soli stati, ON o OFF, il numero di possibili stati
sarebbe pari a 2N. In questo modo si potrebbe anche calcolare quanto
un organismo è più complesso di un altro.
32,000 geni nel genoma umano
Complessità = 232,000
Se si calcola la complessità solo sul numero di geni, non vi sono
differenze macroscopiche nella complessità negli eucarioti.• L’approccio minimalista della biologia molecolare in cui ci si attendeva che lo studio di un gene o un gruppo di geni potesse portare ad una completa descrizione biomolecolare di come un essere umano è fatto e funziona ha subito un forte ridimensionamento dalle bozze di sequenze del genoma • Non ci sono rivelazioni sorprendenti su cosa rende un uomo diverso da uno scimpanzè • Sulla base del numero di geni noi siamo solo 3 volte più complessi del moscerino della frutta e solo due volte più complessi del verme microscopico Caernorhabditis elegans
Il genoma dei procarioti • Dimensioni: variabili da 580.000 a 7 milioni coppie di basi • Numero di geni di solito tra 1000 e 2000 (480 Mycoplasma genitalium, 4.400 E.coli) • Densità genica costante di circa 1 gene/1000 coppie di basi (genoma più grande-più geni) . Geni per trascrizione e traduzione numero simile tra le varie specie (anche se dimensione del genoma variabili) . Geni per metabolismo numero variabile secondo specie
• 12,1 milioni di coppie di basi • 6.100 geni di cui 5.900 codificano per proteine • Densità genica: 1 gene/2000 coppie di basi • 239 introni • 30% dei geni in due o più copie (ridondanza)
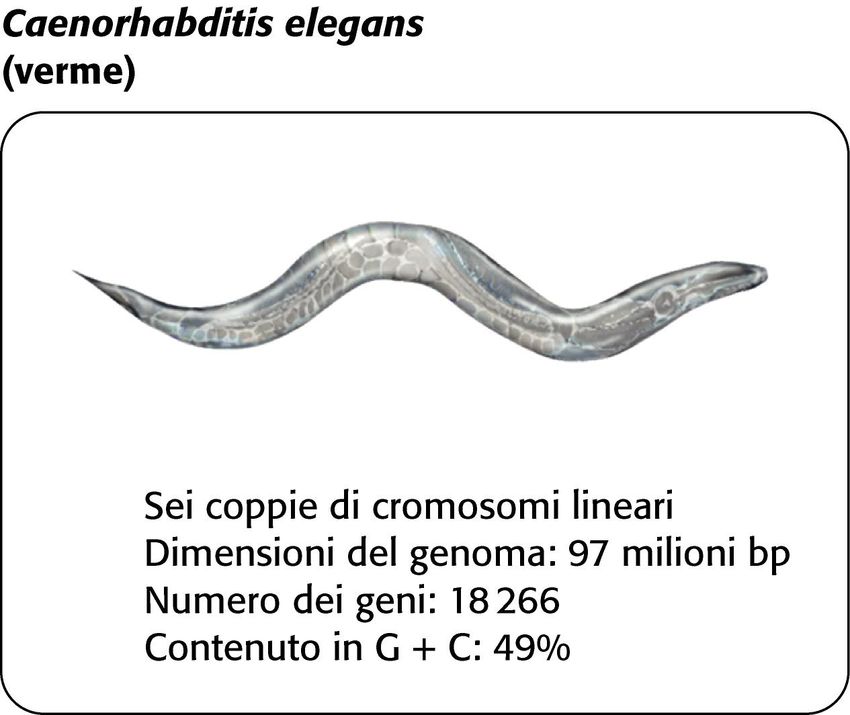
• 97 milioni di coppie di basi • 18.000 geni codificanti per proteine • Densità 1 gene/5000 coppie di basi
• 167 milioni di coppie di basi • 25.700 geni presunti • Densità 1 gene/6.500 coppie di basi • 60% del genoma formato da segmenti replicati (poliploidia) (duplicazione genica importante nell’evoluzione) • 17% geni disposti in tandem (crossing over ineguale)
• 180 milioni di coppie di basi • 13.000 geni • Densità 1 gene/14.000 coppie di basi
3,2 miliardi di coppie di basi 25% trascritto in RNA 2% codifica per proteine Un gene umano medio 27 Kb con circa 9 esoni Splicing alternativo 1 gene 2-3 proteine 32.000 geni 96.000 proteine Densità genica diversa nei diversi cromosomi (1 circa 3000 geni, Y circa 231) 3 milioni SNP (Single Nucleotide Polimorphism) Sequenze ripetute almeno il 50% del totale
Sizes of eukaryotic genomes
size (Mb)
Fungi
Saccharomyces cerevisiae 12.1
Aspergillus nidulans 25.4
Protozoa
Tetrahymena pyriformis 190
Invertebrates
Caenorhabditis elegans 97
Drosophila melanogaster 180
Bombyx mori (silkworm) 490
Locusta migratoria (locust) 5000
Vertebrates
Takifugu rubripes (pufferfish) 400
Homo sapiens 3200
Mus musculus (mouse) 3300
Plants
Arabidopsis thaliana (vetch) 125
Oryza sativa (rice) 430
Zea mays (maize) 2500
Pisum sativum (pea) 4800
Triticum aestivum (wheat) 16 000
Fritillaria assyriaca (fritillary) 120 00050 anni fa: – La quantità totale di DNA di un organismo non correla con la complessità dell’organismo qualche anno fa: - Il numero di geni di un organismo non correla con la complessità dell’organismo
I Genomi degli Eucarioti: contenuto in DNA Si osserva che il contenuto totale di DNA negli eucarioti e quindi la dimensione del genoma è correlata alla complessità dell’organismo (ad es., il genoma umano è più grande di quello degli insetti che è a sua volta più grande di quello funghi). Esistono però diverse eccezioni: es. il genoma di X. laevis è grande quanto quello dei mammiferi; altri anfibi hanno un genoma circa 50 volte più grande del genoma umano; tra le piante, il genoma di Zea Mais (5000 Mbp) è più grande di quello umano. In genere, per un dato raggruppamento tassonomico, la dimensione minima del genoma è approssimativamente proporzionale alla complessità dell’organismo
Che cosa è un GENE Brown T.A. Genomi 2 Un segmento di DNA contenente informazioni biologiche, che codifica per una molecola di RNA e/o proteina. Ma….
Definizione di GENE
• Un gene può utilizzare diversi promotori
• La trascrizione di un gene si può arrestare in corrispondenza di diversi terminatori
• I trascritti espressi da un gene possono subire splicing alternativo che generano
trascritti che differiscono sia nelle regioni non tradotte (5’ e 3’UTR) che nella
regione codificante
Il gene per tp73L codifica per 10 trascritti alternativi, e utilizza 2 promotori e 3 diversi
45
terminatori della trascrizione (predizione ottenuta dal programma ASPIC).I geni possono essere sovrapposti I geni possono essere sovrapposti tra loro, nello stesso orientamento o in orientamento opposto, o anche essere completamente contenuti in altri geni.
Geni dentro i geni Nei mammiferi sono descritti geni contenuti nei grandi introni di alcuni geni. spesso viene utilizzato il filamento opposto al gene “canonico” L’introne 26 del gene neurofibromatosis type I (NF1) contiene 3 geni diversi nell’orientamento opposto (OMGP, EVI2A, EVI2B).
Definizione di GENE
Maggiore complessità
Una specifica regione di DNA, la cui trascrizione è regolata da uno o più
promotori e altri elementi di controllo trascrizionale che contiene l’informazione per
la sintesi di proteine e RNA non codificanti funzionali, tra loro correlati per la
condivisione di informazione genetica (con un tratto di sequenza genomica in
comune) a livello dei prodotti finali (proteine o ncRNA).
In questo modo è possibile associare al gene specifiche coordinate genomiche
che coincidono con il sito di inizio della trascrizione più a monte e il sito di
terminazione più a valle.
Gene
48La struttura dei geni eucariotici
I geni eucariotici presentano una grande varietà di strutture e dimensioni.
Ad esempio nel genoma umano:
Il più piccolo: Il più grande:
tRNAGLU (69 bp) Distrofina (2.4 Mb, la sua
trascrizione richiede circa 16h)
Il numero di esoni può variare da 1 (geni privi di introni come molti geni
per ncRNA, interferoni, istoni, ribonucleasi, ecc.) sino a 363 (Titina). Le
dimensioni degli esoni e degli introni sono estremamente variabili.
A fronte di esoni costituiti da pochi nucleotidi, l’esone più grande è
presente nel gene per ApoB (7.6 kbb). Anche le dimensioni degli introni
possono variare da pochi nucleotidi fino a 800 kbp (gene WWOX).
Le proteine codificate possono variare nelle dimensioni da pochi residui
(piccoli ormoni) sino a molte migliaia (Titina, 38.138 aa).
49Splicing Alternativo Oltre il 90% dei geni umani è in grado di esprimere più di un trascritto (ed è quindi soggetto a splicing alternativo). Le diverse isoforme di splicing possono avere specificità a livello di tessuto, di condizione fisiologica, o patologica.
Splicing alternativo
Splicing Alternativo
Lo splicing alternativo aumenta in modo considerevole la complessità del
trascrittoma (e quindi del proteoma).
52Uno stesso gene può esprimere proteine con funzioni opposte:
l’esempio dell’attività della Caspasi 9 (CASP9)
La forma costitutiva della proteina (CASP9, 9 esoni, 416 aa) induce apoptosi. Essa contiene
un Caspase recruitment domain (CARD) e un dominio caspasi Peptidase_C14.
L’isoforma più corta della proteina (CASP9S, 5 esoni, 266 aa) contiene un dominio Caspase
recruitment domain (CARD) e un dominio tronco della Peptidase_C14. Questa isoforma è
priva dell’attività proteasica e agisce da inibitore dell’apoptosi.Uno stesso gene può codificare per proteine indirizzate a diversi
compartimenti cellulari: l’esempio del gene NFS1
La proteina codificata dal gene NFS1 fornisce zolfo inorganico ai cluster ferro-zolfo rimuovendo lo
zolfo dalla cisteina, e formando alanina nel processo. Questo gene utilizza siti di inizio alternativi della
traduzione per generare una isoforma mitocondriale ed una isoforma citoplasmatica. La selezione del
sito di inizio della traduzione è regolata dal pH citosolico.
L’isoforma che codifica per la proteina mitocondriale (457 aa) contiene un peptide segnale e un dominio
aminotransferasico.
L’altra isoforma, che deriva sa un sito di inizio alternativo della trascrizione codifica per una proteina
più corta (397 aa) priva del peptide segnale ma contenente il dominio aminotransferasico.La funzione dei geni eucariotici
La funzione di una grossa frazione dei geni umani rimane sconosciuta
55Geni umani Geni codificanti per proteine (circa 25.000) Geni per i tRNA e rRNA Geni per RNA non codificanti (ncRNA) Struttura-regolazione-funzione Distribuzione nel genoma
Geni per ncRNAs I genomi eucariotici codificano per un gran numero di RNA non codificanti proteine (ncRNA). Circa il 30% dei trascritti identificati nel topo risulta non codificante per proteine. snoRNA: Processing e modificazione di rRNA nel nucleolo. metilazione a livello del 2’-O-ribosio (105-107 siti), gli H/ACA snoRNA guidano la pseudouridinazione sito-specifica (95 siti). snRNA: ricchi in U, numerati U1, U2, U3, etc. RNA coinvolti nello splicing (U1, U2, U4, U6…), presenti in copie multiple. 57
Geni codificanti i tRNA I singoli geni codificanti per i tRNA sono presenti in copie multiple nel genoma. Nella sequenza del genoma umano, sono stati individuati 497 geni per tRNA, che rappresentano 49 specie di tRNA sulla base dell’anticodone (21 isoaccettori). I geni per tRNA sono dispersi nel genoma ma sono organizzati in cluster: più del 50% sono localizzati sul cromosoma 6 (140 geni in una regione di 4Mpb) e sul cromosoma 1. Altri cromosomi hanno meno di 10 geni per tRNA.
Geni codificanti gli rRNA I geni codificanti per per gli rRNA 28S, 5,8S e 18S sono organizzati in un’unità trascrizionale ripetuta in tandem. Nel genoma umano, le ripetizioni sono organizzate in 5 cluster di circa 150-200 copie presenti sul braccio corto dei cromosomi 13,14,15, 21 e 22. I geni l’rRNA 5S sono organizzati in unità ripetute che formano un cluster di ~200- 300 geni in prossimità dell’estremità telomerica del cromosoma 1
Geni codificanti i miRNA
miRNA inducono la degradazione dell’mRNA corrispondente
o il blocco della traduzione
Ago1-complesso RISC
Dicer effettua tagli sfalsatiGeni codificanti per proteine - geni presenti in unica copia (single-copy genes) - geni presenti in copie multiple
Famiglie geniche All’interno del genoma umano esistono sequenze simili ad altre che si trovano in localizzazioni diverse. Se la somiglianza (similarity) supera una certa soglia si dice che appartengono alla stessa famiglia (BLAST, Altschul et al., 1997) La somiglianza è un parametro puramente decrittivo ma spesso usato per dedurre la derivazione di due sequenze da un progenitore ancestrale comune, fenomeno indicato come omologia di sequenza (homology).
Famiglie di geni o geniche Copie multiple di geni, tutte con sequenza identica o simile. La famiglia multigenica corrisponde a un insieme di geni correlati che si sono evoluti da un certo gene ancestrale mediante un processo di duplicazione genica. I membri di una famiglia genica possono trovarsi raggruppati oppure dispersi su cromosomi diversi.
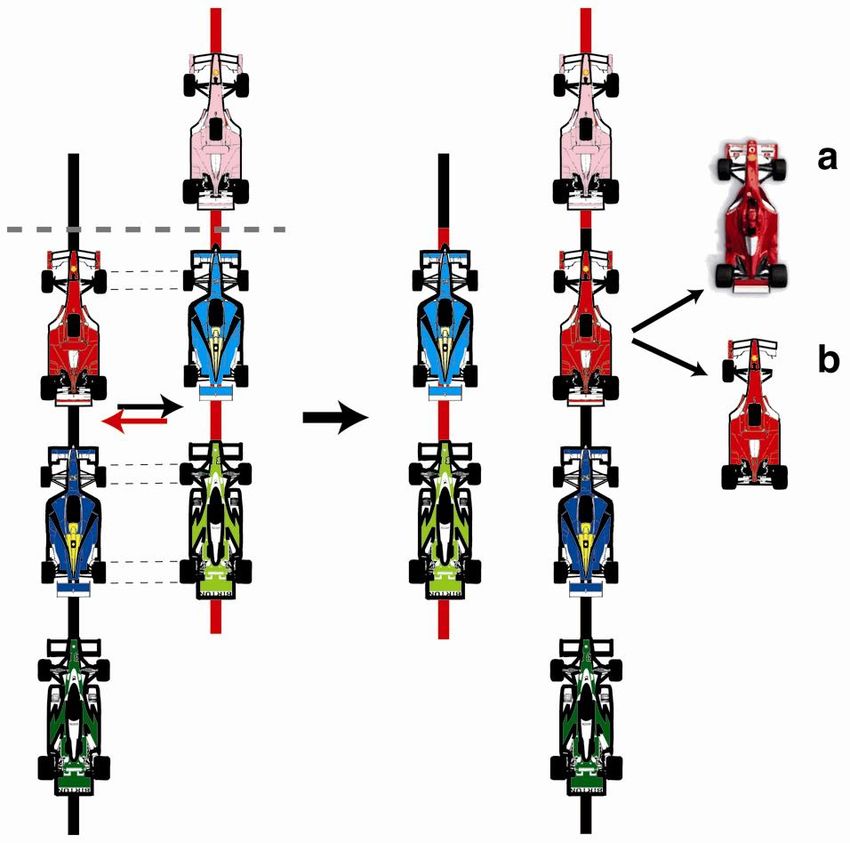
Il meccanismo principale alla base della duplicazione genica è il crossing- over ineguale, derivante da piccoli errori d’appaiamento dei cromatidi omologhi durante la meiosi.
Crossing over Da “Biologia cellulare e genetica” Fantoni, Bozzaro, Del Sal, Ferrari, Tripodi Parte II Genetica, Piccin
Crossing over ineguale
Destino geni duplicati
Duplicazione genica
Produzione di due copie identiche di un gene
Delle due copie, una continua a svolgere la propria
funzione, l’altra può andare incontro a diversi destini
Il gene duplicato mantiene la stessa Il gene duplicato, non essendo
funzione del gene ancestrale (istoni) sottoposto alla stessa pressione
Gene redundancy selettiva del gene ancestrale, può
accumulare mutazioni casuali
L’accumulo di mutazioni porta L’accumulo di mutazioni fa sì che il
all’inattivazione del gene gene duplicato possa acquisire una
duplicato, trasformandolo in nuova funzione utile per l’organismo
pseudogene (pseudogeni delle a e (le nuove funzioni acquisite possono
b globine) diventare specie-specifiche)I geni paraloghi Gene A
derivano da un unico
gene ancestrale che ha
Duplicazione
subìto duplicazione
genica. Le due copie si
trovano nello stesso Gene A Gene B
organismo e codificano
per proteine con
strutture e funzioni Geni paraloghi
diverse (evoluzione
divergente).Gene A I geni ortologhi sono geni omologhi, presenti in specie diverse ma Speciazione correlate, che codificano per proteine che hanno Gene A1 funzioni simili e che si sono separati non per un evento di duplicazione Gene A2 ma in seguito a speciazione (separazione delle specie). Geni ortologhi
Duplicazione di un singolo gene
Famiglia dei geni per le globineTipi di famiglie geniche Famiglie geniche classiche (istoni, a e b globine) Geni codificanti prodotti con grandi domini altamente conservati (es. geni omeotici) Geni codificanti proteine contenenti corti motivi aminoacidici conservati, correlati ad una comune funzione (es. DEAD box) Superfamiglie (es. immunoglobuline, globine)
Famiglie geniche classiche I membri presentano un elevato grado di omologia per quasi tutta la lunghezza del tratto di DNA codificante Esempi: - Famiglia di geni per gli rRNA - Famiglia di geni per gli istoni - Geni per le globine
Le due famiglie dei geni per le globine a e b
7 geni a-simili sul cromosoma 16
6 geni b-simili sul cromosoma 11Superfamiglie geniche
I membri non presentano motivi aminoacidici particolarmente conservati
ma hanno comuni caratteristiche strutturali.
Esempi:
- Superfamiglia delle Ig
Superfamiglia delle IgDa “Biologia cellulare e genetica” Fantoni, Bozzaro, Del Sal, Ferrari, Tripodi Parte II Genetica, Piccin
Pseudogeni Gli pseudogeni possono essere classificati in: 1) non processati; 2) processati. Nel primo caso il gene inattivo è originato dal gene funzionale e contiene la tipica struttura in esoni ed introni. La copia genica può essere completa o parziale. Gli pseudogeni processati sono privi di introni in quanto derivano da mRNA (retropseudogeni). Il numero di copie di retropseudogeni è correlato al livello di espressione del gene da cui derivano.
Uno pseudogene processato o maturato deriva dall’mRNA di un gene su cui viene sintetizzata una copia di DNA che successivamente viene reinserita nel genoma (a caso, stesso o diverso cromosoma) e duplicata Uno pseudogene processato non contiene le sequenze introniche e le sequenze 5- UTR che regolano l’espressione gene. Uno pseudogene processato è inattivo.
Pseudogeni Nel genoma umano sono stati descritti ~8.000 pseudogeni (~5.000 nel genoma del topo).
Da “Biologia cellulare e genetica” Fantoni, Bozzaro, Del Sal, Ferrari, Tripodi Parte II Genetica, Piccin
sequenze di DNA non geniche
Il DNA ripetitivo può essere distinto in due categorie secondo la localizzazione: • Ripetizioni intersperse: le cui unità sono distribuite nel genoma in modo casuale e occupano il 44% del genoma • Sequenze ripetute in tandem: le cui unità sono disposte in serie l’una vicina all’altra
Da “Biologia cellulare e genetica” Fantoni, Bozzaro, Del Sal, Ferrari, Tripodi Parte II Genetica, Piccin
Sequenze ripetute a tandem: • -DNA satellite (centromeri) 5-171bp • - minisatelliti a numero variabile (VNTR) in cui l’unità ripetitiva può essere lunga fino a 64 nucleotidi (es. telomeri e regioni peritelomeriche) • - i microsatelliti o ripetizioni a tandem semplici (STR) le cui unità ripetitive sono di di- o tetra-nucleotidi ripetute un numero variabile di volte con una media di uno ogni 2000 coppie di basi • Funzione? • Si sa che derivano da errori nel processo di copiatura del genoma durante la la divisione cellulare e potrebbero essere prodotti inevitabili della replicazione del genoma
Nel genoma umano si possono riconoscere 4 tipi di
ripetizioni intersperse:
- SINE (sequenze Alu = 1.1 milione di copie nel
genoma)
- LINE
- elementi LTR
- transposoni a DNA
Sono tutti derivati da elementi trasponibiliThe types of genome-wide repeats in the human genome
Type of repeat Subtype Approximate number of copies in the human
genome
SINEs 1 558 000
Alu 1 090 000
MIR 393 000
MIR 375 000
LINEs 868 000
LINE-1 516 000
LINE-2 315 000
LINE-3 37 000
LTR elements 443 000
ERV class I 112 000
ERV(K) class II 8000
ERV(L) class III 83 000
MaLR 240 000
DNA transposons 294 000
hAT 195 000
Tc-1 75 000
PiggyBac 2000
Unclassified 22 000
from IHGSC (2001). The numbers are approximate and are likely to be under-estimates
( Li et al., 2001).Quasi metà del genoma umano deriva da elementi trasponibili
Nel genoma umano la quantità di DNA derivante da
elementi trasponibili è 20 volte la quantità di DNA che
codifica per tutte le proteine umanePorzione non codificante:Ripetizioni intersperse
Costituite da sequenze di DNA ripetute, disperse in tutto il genoma.
Sono definite anche Elementi mobili del DNA, perché derivano da elementi
trasponibili (sequenze di DNA che si muovono o sono duplicate da una
posizione ad un’altra nel genoma)
Classe I o Retrotrasposoni
si originano per eventi di
retrotrasposizione, attraverso un
intermedio ad RNA
• elementi LTR
• LINEs: long interspersed nuclear
elements
• SINEs: short interspersed nuclear
elements
Classe II o Trasposoni a DNA
si originano attraverso un intermedio a
DNA, secondo meccanismo di
trasposizione conservativa o replicativa
87Retrotrasposoni
La caratteristica di tutti i retrotrasposoni
è la presenza di brevi ripetizioni dirette
alle estremità 3’ e 5’ , copia della
sequenza del sito d’integrazione.Elementi LTR
Gli elementi LTR o retrotrasposoni virali (6-7kb) presentano analogie
con i retrovirus.
Caratteristici degli invertebrati (piante, funghi, insetti) dove sono presenti
in gran numero di copie
Elementi Ty in S. cerevisiae mancano del gene env e non
elementi copia in Drosophila possono formare particelle virali
250-600pb
89LINEs:long interspersed nuclear elements
promotore anche endonucleasi ripetizioni
Pol II RNA binding dirette
Gli elementi LINEs o trasposoni non-LTR
contengono un promotore per l’RNA polimerasi II (derivano da trascritti della l’RNA
pol II), una o due ORF e un segnale di poliadenilazione all’estremità 3’.
•ORF1 codifica per una proteina a funzione ignota (lega l’RNA?),
•ORF2 codifica per un’enzima che possiede sia un’attività di trascrittasi inversa (RT),
simile a quella dei retrovirus e dei retrotrasposoni virali, che un’attività di DNA
endonucleasi (EN).
Le copie attive inserendosi in punti critici del genoma possono inattivare dei geni con
conseguente insorgenza di patologie.SINEs: short interspersed nuclear elements
A B AAAA SINE
Gli elementi SINEs sono elementi non-autonomi
Hanno un promotore (interno) per L’RNA polimerasi III (derivano da trascritti
della l’RNA pol III), e una regione ricca in A all’estremità 3’ ma non contengono
un segnale di poliadenilazione.
Gli elementi SINEs non contengono alcuna ORF codificante per una trascrittasi
inversa, ma sono in grado di trasporre utilizzando la trascrittasi inversa
sintetizzata da altri retroelementi (trasposizione LINEs-dipendente).Danni genomici indotti da Alu Numerose patologie sono provocate dall'integrazione casuale di Alu (Neurofibromatosi, haemophilia, sindrome di Apert, ecc.) o da ricombinazione disuguale (diabete di tipo II, sindrome di Lesch–Nyhan, malattia di Tay–Sachs, ipercolesterolemia familiare, α-thalassaemia, ecc.).
Trasposoni a DNA I Trasposoni a DNA sono elementi mobili distinti in due categorie: •Trasposoni a DNA che si spostano replicandosi: una copia rimane nel sito originale, mentre la nuova copia si inserisce altrove nel genoma •Trasposoni a DNA che si spostano in maniera conservativa, da un sito all’altro del genoma senza aumentare il numero di copie Sono caratterizzati da una sequenza codificante la trasposasi contenente introni, fiancheggiata da ripetizioni terminali
Puoi anche leggere