Distributed Tracing con OpenTracing & Jaeger - Andrea Fornaia, Ph.D - DMI Unict
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Distributed Tracing
con OpenTracing & Jaeger
Andrea Fornaia, Ph.D.
Department of Mathematics and Computer Science
University of Catania
Viale A.Doria, 6 - 95125 Catania Italy
fornaia@dmi.unict.it
https://www.dmi.unict.it/fornaia/
A.A. 2020/2021
Microservizi e Complessità • Le aziende decidono di adottare un’architettura a microservizi per ottenerne i benefici: – maggior scalabilità dei componenti – maggiore produttività degli sviluppatori – rilasci più frequenti • L’uso dei microservizi porta con sé nuovi problemi da risolvere e la gestione della complessità tipica dei sistemi (altamente) distribuiti • Aziende come Twitter, Netflix e Uber hanno adottato con successo questo stile perché hanno trovato soluzioni efficienti per gestirne la complessità

Osservabilità
• Nella teoria dei controlli, un sistema si dice osservabile se il suo stato interno, e di conseguenza il
suo comportamento, può essere determinato solo guardandone gli input e gli output
• Questa definizione non è sufficientemente pratica per i sistemi software: a causa della loro
complessità, è difficile spesso determinarne completamente lo stato interno partendo solo dagli
input e dagli output
• Una definizione più appropriata nel nostro contesto: l’osservabilità di un sistema software è
direttamente proporzionale a “quanto è possibile per un operatore umano fare domande e
ottenere risposte sul sistema stesso”
• Simile al concetto di “monitoraggio”: tipicamente con questo si intende la raccolta e
aggregazione di metriche e la segnalazione automatica di allarmi (numero di errori, tempi di
latenza…)
• Per “osservabilità” si intende più la capacità per un operatore di comprendere manualmente,
tramite appositi strumenti, se il sistema si sta comportando come dovrebbe e investigare
(debugging) in caso di anomalie
• Parafrasando Brian Cantrill: L’osservabilità si poggia su “tre pilastri”: metriche, log, tracce, ma le
sue “fondamenta” sono certamente l’operatore umano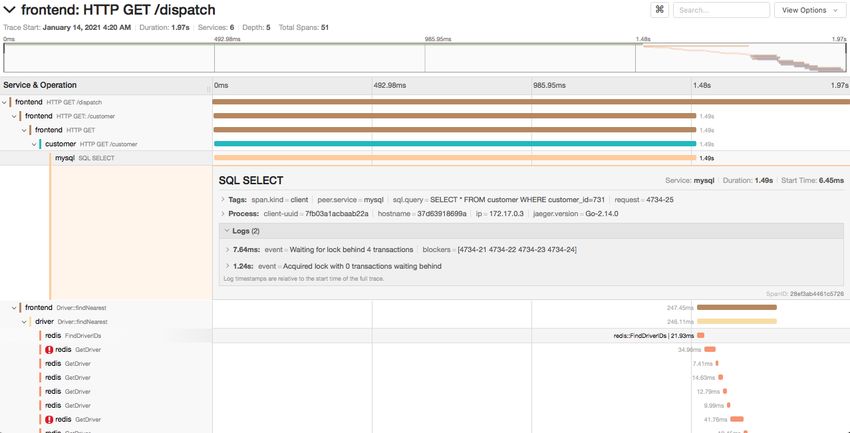
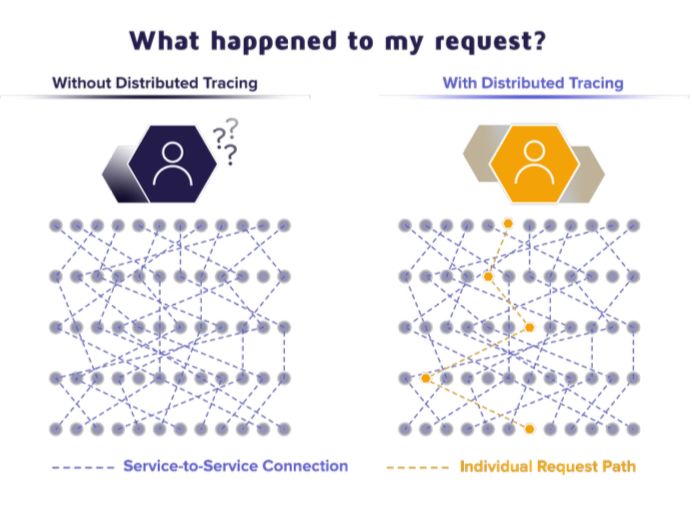
Tracing Distribuito Obiettivi: • Ricostruzione ordinata temporalmente del percorso intrapreso da una singola richiesta • Risalire alla causa di eventuali problemi dell’applicazione (bug) • Analisi della performance dell’applicazione (colli di bottiglia) • Ricostruire il grafo delle dipendenze tra i servizi
Metriche, Log, Tracce
• Metriche: facili da raccogliere, aggregare, e
utili per definire allarmi automatici, ma proprio
l’aggregazione elimina le informazioni sul
contesto necessarie per osservare la
gestione della singola richiesta
• Log: ci permettono di tener traccia del
comportamento di una singola istanza di un
servizio; sono “orientati al processo”. Fare
trubleshooting usando solo i log dei singoli
processi è come fare debugging senza avere
uno stack trace: abbiamo indizi sparsi
ovunque, ma ci manca una visione d’insieme
• Traccia: raccoglie in maniera strutturata tutto
il flusso di attività svolte per la gestione di
una singola richiesta (request-centric) con
relazioni di causalità. Le tracce possono
contenere internamente anche log e metriche
Log e Osservabilità in caso di Concorrenza
Supponiamo di voler osservare il comportamento del sistema nella gestione di una richiesta
proveniente da un utente:
• (No Concurrency) Se ogni richiesta viene gestita in un processo separato (fork) i log possono
essere sufficienti (i log sono già separati per ciascuna richiesta)
• (Basic Concurrency) Se ogni richiesta viene gestita in un thread separato, dobbiamo almeno
aggiungere ad ogni riga di log il nome del thread che l’ha generata
• (Async Concurrency) Se più thread sono coinvolti nella gestione di una richiesta, come nel caso
di chiamate asincrone intra-processo, il nome del thread non basta, ma serve creare un
identificativo della richiesta da scambiare tra un thread e l’altro
• (Distributed Concurrency) Se la richiesta viene gestita da più processi, l’identificativo della
richiesta deve essere scambiato anche nelle comunicazioni inter-processo
Aggregazione dei Log
• Esistono varie soluzioni per aggregare i log, come l’uso dello stack ELK
(ElastickSearch, LogStash, Kibana)
• Pur avendo tutti i log del servizi distribuiti in un unico punto, per tracciare una
singola richiesta è comunque necessario:
– Condividere tra i processi l’id della richiesta da inserire nei log (propagazione del
contesto)
– Registrare esplicitamente le relazioni di causalità; il timestamp nei log di processi
distribuiti può non essere affidabile per correlare l’ordine degli eventi, per via di
problemi di disallineamento (clock-skew)
https://github.com/dmi-lab-isd/spring-elk
Costruire la traccia di una richiesta
• Una traccia è una sequenza ordinata temporalmente di attività scaturite da una richiesta
• Rappresentabile come una sequenza temporale di span annidati
• Uno span rappresenta un’unità di lavoro all’interno di un singolo servizio
• Lo span di più alto livello viene detto root span e identifica l’intera gestione della richiesta
• Una traccia può essere visualizzata con un diagramma di Gantt
• L’idea è di inserire nel codice dei servizi (instrumentare) dei trace point, ovvero dei punti in cui
decidere l’inizio e la fine di uno span, assieme ad altre informazioni di contesto
• È buona prassi iniziare uno span prima di ogni chiamata ad un servizio esterno (es.
microservizio o DB) e chiuderlo dopo aver ricevuto la risposta (inter-process)
• Altri span più granulari possono essere aggiunti per tener traccia di chiamate a metodo
all’interno del servizio (intra-process), migliorando l’osservabilità nella gestione della richiesta
Propagazione del contesto
• Gli span dei singoli servizi devono essere correlati tra loro per formare un’unica traccia
• Vengono scambiati dei metadati di contesto, come un ID della richiesta, assieme alle
chiamate o scambio di messaggi tra i servizi in rete (RPC, HTTP, RabbitMQ) es. tramite
header in una richiesta HTTP o metadati in un messaggio su coda
• Viene scambiato anche un riferimento allo span padre (span reference) (es. sia “Catalog”
che “Promos” riceveranno l’ID della richiesta e il nome dello span “Web Server”) in modo da
tener esplicitamente traccia della relazione di causalità
• Tutti gli span vengono inviati (a intervalli regolari) ad un servizio centrale, detto back-end di
tracing, o semplicemente tracer che si occupa di ricostruire le tracce e di renderle fruibili
agli operatori tramite UI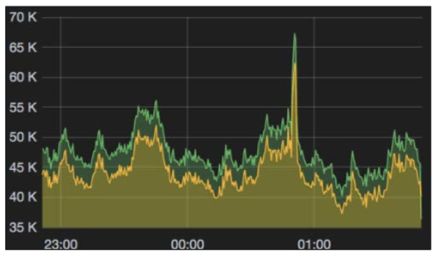
Tipi di Span Reference
• “child-of”: A
B
– A accade-prima-di B
– A dipende-dal-risultato-di B
– Astart – Bstart – Bend – Aend
– Es. RPC/REST, query su DB, chiamate a metodo sincrone
• “follows-from”: A
– A accade-prima-di B B
– A non-dipende-dal-risultato-di B
– Astart – Aend – Bstart – Bend
– Es. message queue, chiamate asincrone, fire and forget,
producer-consumerClock Skew
• Per stimare i tempi di latenza tra due richieste è importante che i clock dei servizi siano quanto più
allineati possibile
• Anche l’uso di un protocollo NTP può comunque causare dei disallineamenti (seppur minimi)
• Le relazioni di causalità permettono di correggere lo slittamento dei clock tra i servizi (clock skew)
• Se il server ha una relazione del tipo “chilf-of” sicuramente l’intero span deve essere contenuto
all’interno dello span padre (client)
• Possiamo quindi shiftare a sinistra lo span del server, correggendone i timestamp, e di
conseguenza anche tutti gli altri span del server verranno shiftati a sinistra
• All’interno dello span padre rimane comunque dell’incertezza: all’inizio viene semplicemente
centrato (d1 e d2 uguali)
• Più relazioni di causalità sono note, più abbiamo possibilità di correggere lo slittamentoItra e inter-process
context propagation
• La propagazione del contesto è necessaria sia tra gli span di servizi diversi che
tra gli span dello stesso servizio
• Possono essere passati come parametri al metodo chiamato
• Ma vedremo come librerie di supporto permettano uno scambio più semplice e
trasparente del contesto, senza richiedere la modifica delle API (signature dei
metodi) del nostro sistemaTag, Log, Baggage
• Oltre all’ID della richiesta (inserito automaticamente) e il riferimento allo
span padre (da specificare), il programmatore può aggiungere diverse
informazioni ad uno span:
– Tag: coppie chiave-valore che valgono per tutto lo span
– Log: identificano eventi, caratterizzati da un timestamp nello span e una
struttura gerarchica di coppie chiave-valore (quindi differiscono dai log
tradizionali)
– Baggage: metadati che vengono trasferiti con le chiamate tra un servizio
ed un altro; mentre tag e log sono pensati per essere solo scritti (e letti solo
dal tracer centrale) i baggage possono essere letti dal codice in fase di
instrumentazione, fornendo maggiori dettagli di contesto utili per migliorare
i log di uno span figlio (diretto o indiretto)
– Nota sui baggage: vengono scambiati in maniera trasparente,
permettendo ai servizi intermedi di ignorarli se non necessari. Devono
essere usati solo al fine del tracing e dell’osservabilità, non devono quindi
essere usati come supporto alla logica di businessOpenTracing • API standard per la generazione di informazioni di tracing • Definisce il modello dati delle tracce, span, ecc • Vendor-neutral: adottato da diversi back-end di tracing (es. Zipkin, Jaeger) • Esistono implementazioni (librerie) per diversi linguaggi • Permette l’instrumentazione del codice per l’inserimento dei trace point
Instrumentazione
• I trace point possono essere inseriti manualmente dallo sviluppatore nel codice
del servizio (Service Instrumentation)
• La programmazione ad aspetti permette di separare la logica di
instrumentazione da quella funzionale
• Diversi framework come Spring, forniscono delle librerie già instrumentate
(Library Instrumentation), generando automaticamente degli span ogni volta
che viene ricevuta una richiesta da parte di un controller HTTP, ogni volta che
viene usato il restTemplate per fare una chiamata HTTP, o quando vengono
effettuate delle query a DB (redis, MySql, MongoDB…)Jaeger
• Creato da Uber, e Ispirato a Zipkin (Twitter)
• Adotta lo standard (data-model) di OpenTracing
• Può appoggiarsi a Cassandra o ElasticSearch per lo storage delle tracce
• Un client (passando per l’agent) invia le tracce al tracer centrale (buffering per ridurre i
costi di rete)
• Strategie di sampling per ridurre il costo del tracing (overhead, rete e storage) es. 1 traccia
completa (tutti i tag, log, baggage) ogni 1000 richieste è la configurazione di default in
produzione
• Anche se non completa, le informazioni di base della traccia vengono comunque
propagate (id richiesta e altri metadati di contesto per la causalità)Jaeger All-in-one (Docker)
docker run -d --name jaeger \
-p 6831:6831/udp \
-p 16686:16686 \
-p 14268:14268 \
jaegertracing/all-in-one:1.6
• -d esecuzione in modalità detached (in background)
• --name il nome assegnato al container (servirà per renderlo accessibile da altri container)
• -p per esporre (mappare) una porta del container sull’host (localhost)
• jaegertracing/all-in-one:1.6 immagine di container pensata per lo sviluppo
• Tutti i microservizi di cui è composto risiedono nello stesso container
• Tracce solo in memoria (può essere configurato Cassandra o ElasticSearch)
• http://localhost:16686 per la web UI
• 6831 per l’invio degli span (UDP)
• 14268 soluzione di backup HTTP/TCP per l’invio degli span in caso di problemi con UDP• I servizi di Jaeger hanno il self-tracing attivato, facendo quinidi il
refresh della pagina più volte possiamo vedere che sono state
tracciate delle richieste al servizio jaeger-query (il servizio della UI)
• Nome span: nome-servizio: nome-operazione
• Nome traccia (mostrato): nome root-span (in celeste la durata)Tutorial: Hot R.O.D.
• Mock-app di un servizio per la prenotazione di corse stile Uber (Hot Ride
On Demand)
• Fornito con Jaeger per mostrarne le funzionalità
• Simula un’applicazione a microservizi che si appoggiano su redis e mysql
• In realtà è implementato in un unico processo e l’accesso ai database è
simulato
• Questo non influisce con la validità delle informazioni di tracingHot R.O.D. (Docker)
docker run --rm -it \
--link jaeger \
-p8080-8083:8080-8083 \
jaegertracing/example-hotrod:1.6 \
all \
--jaeger-agent.host-port=jaeger:6831
• --rm il container verrà cancellato dopo aver terminato
• -it modalità interattiva (output/log visibili su stdout/terminale)
• --link per permettere al container di risolvere il nome di rete jeager con il
riferimento al container (con nome) jeager
• -p8080-8083:8080-8083 esposto il range di porte del container su localhost
• jaegertracing/example-hotrod:1.6 Hot R.O.D.
• all il comando eseguito all’avvio del container (per lanciare tutti le parti in un
unico processo, quindi volendo si potrebbe creare un container parte)
• --jaeger-agent.host-port=jaeger:6831 il riferimento che il client jaeger userà
per inviare le tracce al back-endRichiediamo una corsa
• Ogni bottone corrisponde ad una destinazione
• Il sistema restituisce la targa del veicolo che ha preso in carico la richiesta
della corsa, assieme al tempo di arrivo stimato
• Vengono inoltre fornite alcune informazioni di debug, ovvero l’ID della
richiesta (4734) e i tempo di latenza (quanto tempo ha impiegato il back-
end del servizio Hot R.O.D. a fornire la risposta al front-end)Scoprire l’architettura interna di
Hot R.O.D.
• Già con una sola richiesta jaeger è stato in grado di ricostruire empiricamente l’architettura
(fino a quel momento esplorata) dell’applicazione (Dependencies/DAG)
• Ogni nodo corrisponde ad un servizio
• I pesi sugli archi corrispondono al numero di chiamate avvenute tra due serviziRicerca di una traccia
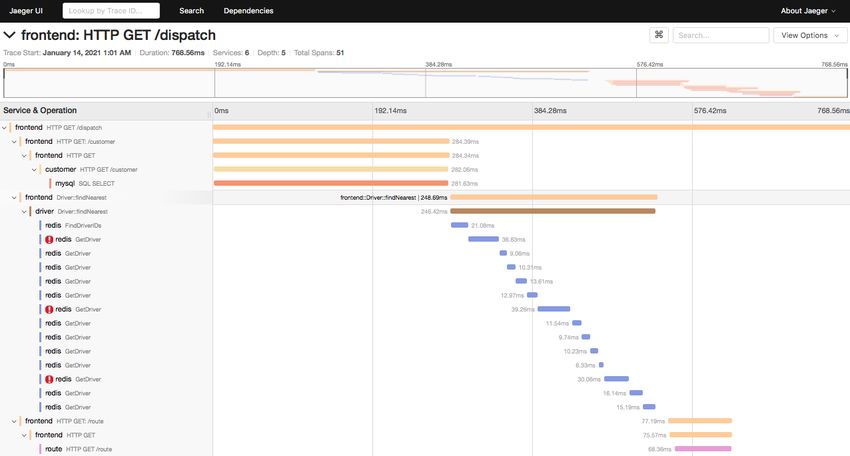
• Service: frontend -> Find Traces
• Sono presenti due tracce: la prima get fatta sull’endpoint “/” quando abbiamo aperto la
pagina e la seconda sull’endpoint “/dispatch” quando abbiamo richiesto la corsa
• Dall’anteprima della tracia possiamo vedere la durata (768.56 ms) quali servizi sono
coinvolti, di quanti span è composta la traccia (51), quanti span ha ogni servizio e
l’eventuale presenza di errori (3)Data Flow della traccia (Gantt)
• Sulla sinistra vediamo le gerarchia di chiamate ai servizi (servizio: operazione)
• Sulla destra i corrispettivi span nel tempo
• Anche solo da questa visione di alto livello (senza ispezionare le informazioni degli span)
possiamo capire molto su come è stata gestita la richiesta da parte dei servizi
• Notiamo anche alcuni problemi (errori) e possibilità di ottimizzazione…Informazioni su una chiamata
HTTP
• Sono presenti dei tag che descrivono la chiamata (es. endpoint e
parametri e il codice restituito, 200) e dei log che descrivono gli
eventi interni allo span (notare il timestamp, a differenza del log)Informazioni su una query a DB • Sono presenti dei tag con le informazioni sulla query, e dei log sull’evento
Span con errore
• Uno span viene segnato come in errore se ha un tag error = true
• L’errore risiede su una richiesta fatta a redis per ottenere le informazioni su un guidatore,
data la targa
• Possiamo vedere dai log sia la targa interessata che il messaggio di errore: “redis
timeout”
• Si tratta quindi di un problema di redis sicuramente da investigare nel codice
• Ma dallo span successivo l’errore viene subito fatta una nuova richiesta per la stessa
targa: le politiche di robustezza (pattern retry) funzionano correttamente!Individuare le cause di latenza (1)
• Notiamo un tipico pattern a scala: tutte le richieste sono sequenziali, ma
in realtà sospettiamo non siano realmente dipendenti tra loro – visione
macroscopica
• Ognuna riguarda la richiesta di informazioni su di un numero di targa
diverso (a parte i retry)… possiamo ora indagare meglio guardando il
codice del servizio o i rispettivi log completi – visione microscopica
• Questo suggerisce di inserire una gestione parallela delle richieste,
risparmiando così tempo per soddisfare la richiestaIndividuare le cause di latenza (2)
• Anche qui notiamo una situazione simile alla precedente, ma notiamo che
un certo livello di parallelismo è stato introdotto, ma solo per 3 operazioni
alla volta
• Questo potrebbe essere dovuto ad una configurazione stringente di un
fixed executor pool (pool di thread di dimensioni fisse, a 3 in questo caso)
• Si potrebbe quindi aumentare la dimensione del poolProviamo ad aumentare il numero
di richieste
• Lanciando alcune richieste in parallelo le
prestazioni del sistema peggiorano notevolmente
(3750 ms contro i 768.56 ms della prima)Diagnosi del problema
• Osservando la traccia (possiamo identificarla perché è la più lunga o tramite una ricerca di
un tag, es. il numero di targa)
• Tutti gli span sono indicizzati in base alle informazioni sui tag e sui log
• Il problema è dato da una maggiore latenza sull’accesso al DB (servizio mysql)
• Dai log notiamo che il problema è un lock di attesa, sicuramente da attenzionare
• La traccia c’è servita ad avere una visione di insieme e capire meglio la radice del problema
(es. è dovuto all’accesso a mysql e non a redis) – visione macroscopica
• Possiamo ora investigare meglio il motivo del problema guardando il codice del servizio
specifico o I relativi log – visione microscopicaRiferimenti
• Yuri Shkuro: Mastering Distributed Tracing (Packt, 2019)
• Austin Parker et al.: Distributed Tracing in Practice: Instrumenting, Analyzing, and Debugging
Microservices (O’REILLY, 2020)
• Steve Flanders: An intro to distributed tracing
https://sflanders.net/2019/03/28/an-intro-to-distributed-tracing/
• Adam Quan: Distributed Tracing, OpenTracing and Elastic APM
https://www.elastic.co/blog/distributed-tracing-opentracing-and-elastic-apm
• OpenTracing Specification: https://opentracing.io/specification/
• Jaeger Architecture: https://www.jaegertracing.io/docs/1.13/architecture/
• OpenTracing: Instrumenting your application:
https://opentracing.io/docs/best-practices/instrumenting-your-application/
• Yuri Shkuro: Take OpenTracing for a HotROD ride
https://medium.com/opentracing/take-opentracing-for-a-hotrod-ride-f6e3141f7941
• Spring OpenTracing Starter: https://github.com/opentracing-contrib/java-spring-jaegerPuoi anche leggere

















































