Big Data Analytics con SAS
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Elaborato finale in Basi di Dati Big Data Analytics con SAS Anno Accademico 2017-2018 Relatore: Prof. Antonio Picariello Candidato: Giorgio Nicolella matr. N46002262
Dedico questa tesi, a tutti quelli che hanno creduto in me: i docenti, che han-
no contribuito alla mia formazione, i colleghi, con i quali mi sono confrontato
ed arricchito, gli amici ed i parenti che mi hanno sostenuto ed in particolar
modo la mia famiglia che mi é stata sempre accanto in ogni istante. Per tutti
i sacrifici fatti per arrivare fin qui, la dedico anche a me:
”Fino alla fine, non si molla”.
1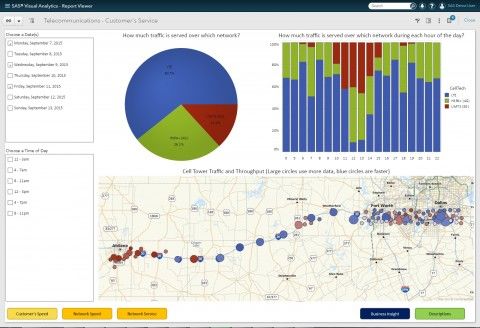
Prefazione
Questo elaborato di tesi finale in Basi di Dati affronta una panoramica sui
Big Data e sui vari tipi di Analytics con riferimento ai Big Data Analytics e
si sofferma in particolare sui Big Data Analytics con SAS. Prima di
analizzare il sistema e le sue potenzialitá si introdurranno i concetti di
informazione e dato, sistema Informativo e basi di dati, scendendo poi in
dettaglio sul loro ruolo nelle analytics. In particolare, per quanto riguarda il
tema centrale della trattazione, che é l’utilizzo delle analisi statistiche dei
Big Data con SAS, piuttosto che effettuare un’arida descrizione dei prodotti
SAS, si é preferito utilizzare un approccio piú snello associando, per
ciascuna fase del ciclo di vita, dalla raccolta dei dati alla preparazione degli
stessi per i report, il possibile aiuto fornito da SAS per la soluzione. Inoltre,
dal momento che il trattamento dei Big Data assorbe notevoli risorse
elaborative, si descrivono le possibili piattaforme e gli aiuti che SAS
fornisce in ciascun approccio per ottimizzare i tempi e/o le risorse. Infine,
un aspetto non meno rilevante, che scaturisce dall’introduzione e
dall’utilizzo di SAS in un’organizzazione é il necessario adeguamento
organizzativo che ne deriva per il corretto e valido utilizzo del prodotto. 1
1
TUTTI I MARCHI REGISTRATI E NON, MENZIONATI NEL PRESENTE TESTO
SONO DI PROPRIETÁ RISERVATA DELLE RISPETTIVE CASE PROPRIETARIE
i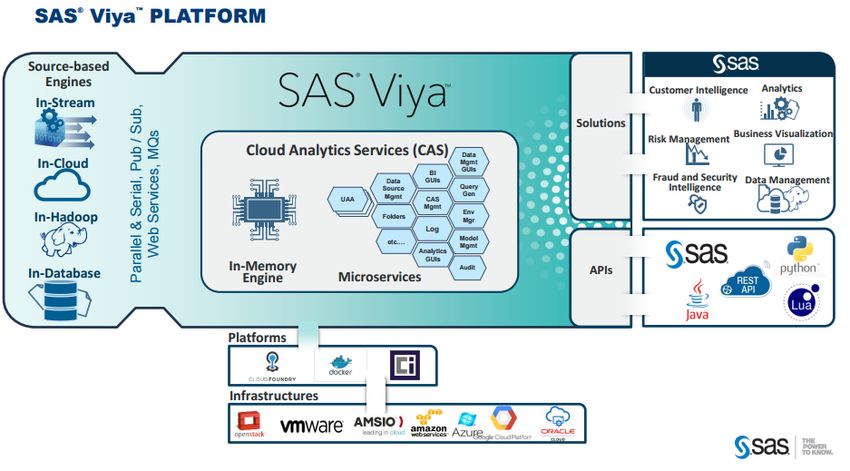
Indice
1 Introduzione 1
1.1 Informazioni e dati . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Sistema informativo . . . . . . . . . . . . . . . . . . . . . . . . 1
1.3 Definizione di Big Data . . . . . . . . . . . . . . . . . . . . . . 2
1.4 Modello dei Big Data . . . . . . . . . . . . . . . . . . . . . . . 2
2 Big Data Analytics 5
2.1 Introduzione ai Big Data Analytics . . . . . . . . . . . . . . . 5
3 SAS 7
3.1 Introduzione a SAS . . . . . . . . . . . . . . . . . . . . . . . . 7
3.2 Introduzione alla piattaforma SAS . . . . . . . . . . . . . . . . 8
3.3 Differenti livelli della piattaforma . . . . . . . . . . . . . . . . 9
3.4 Formato ed informazioni . . . . . . . . . . . . . . . . . . . . . 11
4 Lavorare sui dati 12
4.1 Preparazione dei dati per l’analytics . . . . . . . . . . . . . . . 12
4.2 Transposing . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
4.3 Trasformazione dei dati statistici e matematici . . . . . . . . . 15
5 Analisi con il Software SAS 17
5.1 Analisi descrittiva . . . . . . . . . . . . . . . . . . . . . . . . . 17
5.2 Analisi predittiva . . . . . . . . . . . . . . . . . . . . . . . . . 18
5.3 Analisi prescrittiva . . . . . . . . . . . . . . . . . . . . . . . . 19
6 I report con SAS 20
6.1 L’attivitá di report . . . . . . . . . . . . . . . . . . . . . . . . 20
6.2 Procedure basilari per il report . . . . . . . . . . . . . . . . . 21
6.3 Possibilitá avanzate per i report . . . . . . . . . . . . . . . . . 21
6.3.1 Output Delivery System (ODS) . . . . . . . . . . . . . 22
6.3.2 SAS/GRAPH . . . . . . . . . . . . . . . . . . . . . . . 22
ii
7 Altri linguaggi di programmazione di SAS BASE 24
7.1 Il linguaggio di programmazione DS2 . . . . . . . . . . . . . . 24
7.2 Il linguaggio di programmazione Federate SQL (FedSQL) . . . 26
8 Architettura 27
8.1 Le piattaforme per SAS in-database ed in-memory . . . . . . . 27
8.2 Architettura orientata ai servizi e microservizi . . . . . . . . . 28
8.3 Server e Grid SAS . . . . . . . . . . . . . . . . . . . . . . . . 29
8.4 Verso Hadoop . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
8.5 SAS per il Cloud . . . . . . . . . . . . . . . . . . . . . . . . . 31
8.6 Eseguire processi al di fuori della piattaforma SAS . . . . . . . 33
8.7 SAS Viya . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
9 Aspetti organizzativi 35
9.1 Le figure professionali . . . . . . . . . . . . . . . . . . . . . . . 35
9.1.1 Data Scientist . . . . . . . . . . . . . . . . . . . . . . . 35
9.1.2 Data Manager . . . . . . . . . . . . . . . . . . . . . . . 36
9.1.3 Business Analyst . . . . . . . . . . . . . . . . . . . . . 36
9.1.4 ACE Leader . . . . . . . . . . . . . . . . . . . . . . . . 36
9.2 La formazione . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
10 Conclusioni 38
Bibliografia 40
iiiElenco delle figure
1.1 Il Modello delle 5V . . . . . . . . . . . . . . . . . . . . . . . . 3
3.1 SAS Windows Environment . . . . . . . . . . . . . . . . . . . 8
3.2 SAS Enterprise Miner . . . . . . . . . . . . . . . . . . . . . . . 9
3.3 Esempio di programma . . . . . . . . . . . . . . . . . . . . . . 11
4.1 Data management per le Analytics . . . . . . . . . . . . . . . 14
5.1 Ricostruzione rotta Awacs [17] . . . . . . . . . . . . . . . . . . 19
6.1 SAS Visual Analytics . . . . . . . . . . . . . . . . . . . . . . . 20
7.1 Differenza tra DS2 e DATA Step . . . . . . . . . . . . . . . . 26
8.1 Architettura Viya . . . . . . . . . . . . . . . . . . . . . . . . . 29
8.2 Soluzione SAS per il Cloud . . . . . . . . . . . . . . . . . . . . 33
ivCapitolo 1
Introduzione
1.1 Informazioni e dati
La risorsa ”informazione” all’interno di una determinata organizzazione as-
sume la forma di un insieme di dati memorizzati su appositi supporti che
devono essere opportunamente interpretati per dare luogo alle informazioni
vere e proprie che, come si vedrá, rappresentano la base del sistema infor-
mativo [1]. Esistono differenze tra dato e informazione. Il dato puó definirsi
come una segnalazione che ha sicuramente un valore proprio, ma puó assu-
mere diversi significati a seconda del contesto in cui si trova. Ad esempio
il numero 100 puó rappresentare una temperatura se parliamo di gradi cen-
tigradi, tempi lunghi se parliamo di giorni, una dimensione se parliamo di
chilometri. L’informazione é il dato nel suo contesto al quale viene associato
il significato. É dunque di fondamentale importanza valutare il database in
modo che i dati memorizzati possano poi essere considerati informazioni vere
e proprie in grado di offrirci i dovuti vantaggi.
1.2 Sistema informativo
L’informazione rappresenta oggi uno dei beni piú preziosi all’interno di una
qualsiasi organizzazione. L’insieme di tali informazioni gestite dai proces-
si aziendali forma ció che é definito come sistema informativo. Un sistema
informativo é costituito dai seguenti elementi: dati, procedure, mezzi e per-
sone, tra cui avvengono interazioni determinanti ai fini del conseguimento
degli obiettivi aziendali. Ogni azienda, dunque, che necessita di produrre o
scambiare informazioni, dispone, in modo consapevole o inconsapevole, di un
proprio sistema informativo.[1]
11.3 Definizione di Big Data
Ogni giorno nel mondo vengono inviati enormi quantitá di dati: sono scam-
biati 288 milioni di e-mail, circa 432 milioni tweet e si pubblicano 250 milioni
di fotografie su Facebook. Il concetto di Big Data é relativamente recente,
per cui una definizione rigorosa e standardizzata dei Big Data non é stata
ancora stabilita. L’evoluzione rapida e caotica della letteratura sull’argomen-
to ha impedito lo sviluppo di una definizione universalmente e formalmente
accettata. I Big Data sono considerati, a loro volta, come un termine che de-
scrive un fenomeno sociale, le risorse informative, i set di dati, le tecnologie di
archiviazione, le tecniche analitiche, i processi e le infrastrutture. Tuttavia la
maggior parte delle definizioni fornite finora puó essere classificata in base a
quattro gruppi, a seconda di dove l’attenzione é stata posta nella descrizione
del fenomeno:
• attributi dei dati;
• esigenze tecnologiche;
• superamento delle soglie;
• impatto sociale.
In effetti si parla di Big Data quando si ha un insieme estremamente
complesso di dati da rendere necessaria la definizione di nuovi strumenti e
metodologie per estrapolare, gestire e processare le informazioni in tempo
utile.
Dato un cosı́ elevato flusso di dati, in tale contesto, viene utilizzato il termine
Big Data per descrivere collezioni di dati, strutturati (come quelli presenti
in basi di dati) e non (e-mail, dati multimediali, dati prodotti da Social
Network, sensori, log di sistemi, ecc.) per cui i metodi convenzionali di
gestione ed analisi non risultano essere piú adeguati [1].
1.4 Modello dei Big Data
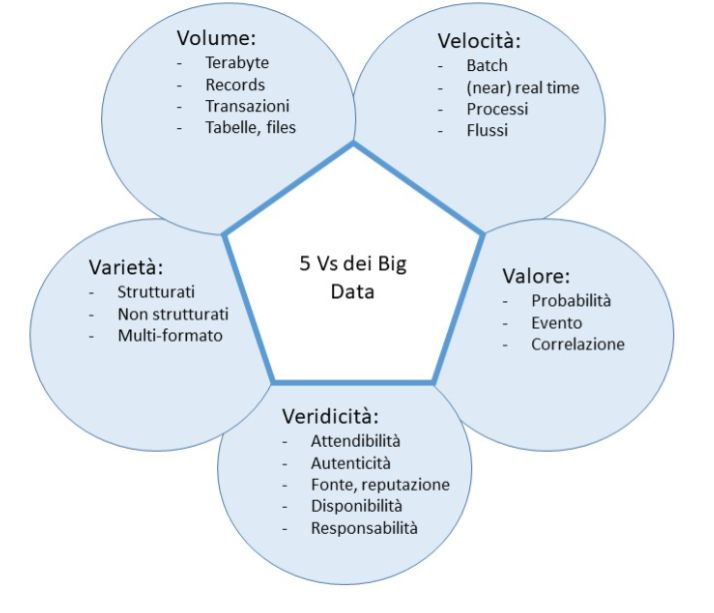
Il modello che ha ricevuto il maggior numero di consensi é quello da cui
é partito l’analista Doug Laney nei primi anni 2000, delle cosiddette 3V ,
secondo cui il concetto di Big Data include i seguenti aspetti:
• Volume: fa riferimento alle dimensioni del dataset, che devono essere
molto grandi. Le organizzazioni raccolgono dati da una grande varietá
di sorgenti, incluse transazioni finanziarie, social media, sensori o da
2macchina a macchina. In passato la memorizzazione su supporti ma-
gnetici esterni sarebbe stato un problema, ma le nuove tecnologie (quali
Hadoop) facilitano il compito;
• Velocitá: fa riferimento all’elevata velocitá di generazione dei dati ed
al fatto che l’analisi dei dati necessita di essere effettuata a ”ritmo
sostenuto”, se non addirittura in alcuni casi in tempo reale [1];
• Varietá: fa riferimento alle tipologie dei dati, che sono differenti, in
quanto provengono dalle fonti piú disparate, nonché alla necessitá di
esplorare sia i dati tradizionali che quelli non strutturati.
Figura 1.1: Il Modello delle 5V
In aggiunta a questo modello iniziale delle 3V, sono stati aggiunti due ulteriori
fattori:
• Veridicitá: legata alla qualitá dei dati e che assume un’importanza ri-
levante specie nei social media, dove possono imperversare ”fake-news”;
• Valore: che enfatizza il valore aggiunto al business che proviene dal-
l’analisi dei dati stessi;
3giungendo cosı́ ad un modello finale a 5V [1], rappresentato nella figura 1.1.
Per completezza della trattazione, occorre aggiungere che SAS considera
i seguenti ulteriori due fattori:
• Variabilitá: L’aumento esponenziale della velocitá e della varietá dei
dati va unito al fatto che i flussi possono essere altamente inconsistenti
e con picchi periodici. Gestire i picchi di dati giornalieri, stagionali o
innescati da eventi puó essere una vera sfida per assicurare adeguate
prestazioni, specie in caso di dati non strutturati;
• Complessitá: Al giorno d’oggi i dati arrivano da molteplici fonti, il
che rende difficile collegare, abbinare, ripulire e trasformare i dati tra-
sversali. Tuttavia, é necessario connettere e correlare le relazioni, le
gerarchie e i collegamenti se non si vuole che i dati sfuggano di mano.
[10]
In definitiva, il termine Big Data puó essere usato per descrivere raccolte
di dati di dimensioni considerevoli, strutturati e non, per i quali i metodi
tradizionali di analisi e gestione risultano essere inadeguati.
É importante per molte aziende lavorare sui Big Data per acquisire un
vantaggio competitivo.
4Capitolo 2
Big Data Analytics
2.1 Introduzione ai Big Data Analytics
L’analisi statistica dei Big Data (Big Data Analytics) é il processo grazie al
quale é possibile estrarre informazioni nascoste dall’analisi di grandi volumi
di dati. Attraverso questa analisi dei dati é possibile ad esempio conoscere le
abitudini dei clienti ed il ciclo di vita di un prodotto, conoscere i dati di geo-
localizzazione degli utenti, la previsione di trend futuri, ma anche previsioni
di eventi di grande portata, quali contagi ed epidemie. [5]
Le societá hanno cominciato a memorizzare ed analizzare i grandi volumi
di dati sin dalla nascita dei primi data warehouse, all’inizio degli anni ’90.
Inizialmente l’unitá di misura per questi data warehouse era il Terabyte, ma
ben presto si é passati in pochissimi anni a dimensioni di Petabyte. Il volume
dei dati é in crescita a dismisura soprattutto per quelle organizzazioni che
cercano di ottenere dai moderni strumenti a disposizione (Web, sensori, ecc.)
profilazioni degli utenti per poterli guidare ed indirizzare nelle scelte.
Le organizzazioni, oggi, catturano tipi di dati estremamente diversificati.
Infatti, fino a pochi anni fa, la maggioranza dei dati era di natura transa-
zionale, essendo costituita da dati alfabetici/numerici che facilmente si po-
tevano adattare alle righe ed alle colonne di database relazionali o di fogli
elettronici. Ad oggi, invece, la crescita dei dati é alimentata da sorgenti non
strutturate in quanto, ad esempio, vengono prelevati dal web (come i dati
del traffico e/o i contenuti dei ”social media”) oppure possono anche essere
generati automaticamente da apparecchiature tramite un immenso numero
di sensori (IoT). Si ha dunque una maggioranza di nuovi dati semistrutturati
(ad esempio la coesistenza di intestazioni seguita da stringhe di testo) o non
strutturati affatto (ad esempio dati di natura audio e video con un contesto
testuale estremamente limitato). Questi dati sono piú difficili da analizzare,
5ma il loro peso sta sempre piú crescendo nel tempo.
Per mantenere il ritmo con i desiderati livelli di memorizzazione e di
analisi di grandi volumi di dati strutturati, i venditori di database relazionali
hanno distribuito e venduto piattaforme specializzate per le Analytics, che
forniscono un livello maggiore di rapporto prestazioni/prezzo comparato con
i sistemi tradizionali di gestione di database. Queste piattaforme, per le
Analytics, esistono in diverse forme e grandezze, da strumenti analitici e
database unicamente software, a servizi analitici completi che girano in un
ambiente ospitato su terze parti.
I nuovi venditori di database non relazionali combinano l’indicizzazione
dei testi e le tecniche di elaborazione del linguaggio naturale con le tecnolo-
gie tradizionali dei database per ottimizzare query fatte appositamente per
dati semistrutturati. Infatti, molte societá di internet e di media usano nuo-
ve strutture di supporto ”Open Source” quali ”Hadoop” e ”MapReduce”,
per memorizzare ed elaborare grandi volumi di dati sia strutturati che non
strutturati in processi batch su server cluster.
La presenza dei Big Data in un’organizzazione, non considerando la tipo-
logia dei dati stessi, é di per se senza valore se gli utenti aziendali non rie-
scono a sfruttarli adeguatamente in modo da apportare benefici alla propria
organizzazione: qui entrano in gioco le analisi statistiche (Analytics).
Mentre gli utenti possono controllare le configurazioni in piccoli gruppi
di dati utilizzando semplici metodi statistici, sono necessarie, invece, delle
query personalizzate e dei tool di analisi per poter scrutare all’interno dei
Big Data. Queste tecniche e questi tool esistono giá da tempo grazie a
compagnie come SAS Institute che hanno sviluppato ”workbench” per le
analisi statistiche dettagliate. In particolare questi strumenti incorporano
al loro interno tutti i tipi di algoritmi analitici che sono stati sviluppati e
ridefiniti dai ricercatori del mondo accademico e commerciale degli ultimi
40 anni. I Big Data favoriscono le Analytics supportando la consegna di
informazioni ”just-in-time”. Il mercato é testimone di uno stravolgimento
in cui esiste la convergenza di Big Data, approfondite analisi statistiche e
consegna di informazioni in real time.
6Capitolo 3
SAS
3.1 Introduzione a SAS
Esistono sul mercato molteplici prodotti per trattare le analisi statistiche.
Come accennato in precedenza, sin dalla prima comparsa di questa tipologia
di prodotti sul mercato uno dei leader nell’analisi statistica é stato SAS, il
cui acronimo sta per Statistical Analysis System proprio in riferimento al suo
primo software per l’analisi statistica, della omonima societá SAS Institu-
te, riconosciuta come azienda leader e come miglior piattaforma nell’analisi
da piú di 40 anni. L’azienda nacque da un progetto di manipolazione dati
nel settore agricolo negli anni ’70. Successivamente i software SAS vennero
utilizzati e personalizzati da societá farmaceutiche, banche ed entitá gover-
native. Nel tempo é stata sempre, ed é tuttora, leader nel campo dell’analisi
statistica, ed oggi l’azienda é attiva principalmente nel campo delle solu-
zioni ”business intelligence” orientate alle imprese. Per poter raggiungere
e mantenere la leadership di mercato SAS investe annualmente un’elevata
percentuale del proprio fatturato in ”Ricerca e Sviluppo” che é pertanto un
impegno in cui SAS crede sin dalla sua fondazione. Da sempre, dunque, SAS
unisce ”know-how” specialistico e ingegno tecnologico per progettare soluzio-
ni innovative, dedicate ad aziende e pubbliche amministrazioni, che creano
un valore inestimabile. Non a caso il motto scelto che accompagna il logo
é appunto: Il potere che deriva dalla conoscenza (The power to know ). La
particolaritá di SAS é che, oltre ad essere un linguaggio di programmazione,
é un vero e proprio ambiente per il processo di analisi. Esso é costituito da
una famiglia di prodotti ed é progettato in modo da poter essere utilizzato
sia da chi possiede poche competenze o conoscenze di base (casual users),
sia da chi lo utilizza in modo approfondito come strumento avanzato (data
scientist e/o power users).
73.2 Introduzione alla piattaforma SAS
Il sistema SAS era inizialmente scritto in un linguaggio per essere eseguito sui
mainframe degli anni ’70, e funzionava mediante linea di comando (command
line). Non vi erano dunque applicazioni a finestra, ma si poteva scrivere una
linea di codice ed eseguirla. Quando fu riscritto in C nel 1980, l’intefaccia
venne chiamata SAS Display Management System (DMS) ed esiste tutt’ora
con il nome di SAS Windows Environment, che consiste di tre principali
finestre, come da figura 3.1:
• un editor di programma per scrivere e inviare il codice;
• un log per il debugging del codice inviato;
• una finestra di output per mostrare i risultati.
Figura 3.1: SAS Windows Environment
8Invece, un’interfaccia piú avanzata e complessa é quella definita da SAS
Enterprise Miner, figura 3.2 , che oltre a consentire molte operazioni di ”drag
and drop”, produce anche un’auto-documentazione del processo.
Figura 3.2: SAS Enterprise Miner
3.3 Differenti livelli della piattaforma
Il linguaggio SAS inizialmente era un insieme dei seguenti strumenti:
• BASE, interfaccia flessibile (oggi Web-Based) per l’accesso, la trasfor-
mazione e i report dei dati;
• SAS/STAT, tool di analisi statistica scalabile, per andare incontro
alle necessitá dell’utente;
• SAS/GRAPH, tool per creare una vasta gamma di rapporti di natura
commerciale e scientifica;
9• SAS/ETS (Econometrics and Time Series Analysis), per modellare,
prevedere e simulare processi con analisi temporali ed econometriche.
Oggi le funzioni BASE, SAS/STAT, SAS/GRAPH sono raggruppate nel pac-
chetto piú elementare commercializzato da SAS e noto come SAS Analytics
Pro. A metá degli anni ’90, SAS sviluppó una piattaforma basata su metadati
al cui centro si trovava ció che é definito come SAS Integration Technologies,
che si é evoluto in SAS Intelligence Platform. Al di sopra di queste soluzioni
”orizzontali” di base si trovano SAS Enterprise Miner, la migliore interfaccia,
facile da utilizzare, per analisi descrittive e predittive, e SAS Forecast Server,
che propone un’interfaccia intuitiva per il forecast (previsione).
Sono descritte come soluzioni orizzontali in quanto sono utilizzabili da
tutte le societá per risolvere i propri specifici tipi di problemi commerciali.
Intorno agli anni 2000, SAS inizió ad introdurre sul mercato, in seguito al-
le richieste dei loro clienti, quelle che vengono definite ”soluzioni verticali”.
Queste soluzioni verticali sono invece progettate appositamente per risolve-
re un determinato problema aziendale in un determinato reparto (come ad
esempio quello di marketing) o un problema specifico di un particolare settore
industriale (ad esempio manifatturiero).
I programmi SAS, infine, sono costituiti da fasi ben distinte e separate
dette ”step”. Ogni passo viene completato prima di passare a quello suc-
cessivo. Le fasi dei dati (DATA step) sono scritte direttamente dall’utente e
sono principalmente usate per la manipolazione dei dati (da cui il nome). Le
fasi procedurali (PROC step) sono, invece, delle istruzioni di programmi rese
disponibili direttamente da SAS. Uno step inizia con la parola DATA o con
la parola PROC e termina con la parola RUN, che peró non é strettamente
mandatoria, poiché SAS suppone che l’utente voglia iniziare un nuovo step
quando vede le parole DATA o PROC. Tuttavia, il codice sará piú chiaro e
piú facile da capire se si rende esplicita la fine di ogni passaggio e miglioran-
done la leggibilitá per una successiva manutenzione anche da parte di altri
utenti.
10Di seguito, in figura 3.3 viene indicato a titolo d’esempio il codice di
quello che é di solito il primo programma che si scrive quando si impara un
nuovo linguaggio, in questo caso riadattato al contesto con la scritta ”Big
Data Analytics With SAS ”.
Figura 3.3: Esempio di programma
3.4 Formato ed informazioni
Un’importante funzionalitá del linguaggio SAS, e della sua archiviazione dei
dati, é fornita dal concetto di ”format” ed ”informat”. I format indicano
come visualizzare i dati memorizzati e gli informat indicano invece come
leggere i dati in variabili SAS. Mentre alcuni linguaggi di programmazione
offrono funzionalitá di formattazione limitate, SAS offre un sistema di formati
robusto ed espandibile dall’utente. Gli informat sono tipicamente utilizzati
per leggere input da file esterni di tipo flat (ad esempio file di testo ASCII)
e sono raggruppati in tre categorie: caratteri, numerico, data/ora.
All’interno della piattaforma SAS esistono due tipi di format/informat:
quelli forniti da SAS denominati ”formati di sistema” e quelli che consentono
a un programmatore SAS di estendere il formato del sistema.[11]
11Capitolo 4
Lavorare sui dati
4.1 Preparazione dei dati per l’analytics
In generale i dati possono essere salvati in diversi formati e su differenti
sistemi e SAS puó salvare ed utilizzare i dati memorizzati in molteplici for-
mati/sistemi. Infatti uno dei punti di forza di SAS é proprio la capacitá di
gestire i dati e, soprattutto, di scriverli in maniera efficiente su tutti i sup-
porti di memorizzazione, ivi compreso i sistemi di gestione di database, file
sequenziali (tipo .txt in windows), fogli di lavoro, formati basati sia su main-
frame che su piattaforme per la memorizzazione di Big Data quali Hadoop ed
Hana. Addirittura talvolta le soluzioni di gestione dei dati sono utilizzate da
molti utenti come ponte di collegamento per consolidare e/o condividere dati
attraverso sistemi diversi. Oltre al motore di SAS/ACCESS, appositamente
sviluppato per poter leggere, scrivere ed aggiornare i dati senza considerare
la sorgente o la piattaforma usata, SAS ha anche sviluppato motori che fun-
zionano con le istruzioni ”libname” e ”fileref” che permettono agli utenti di
SAS di poter lavorare con file di altri standard (XML, http o FTP, solo per
citarne alcuni). Dal momento che SAS é anche un linguaggio di programma-
zione, vi é la possibilitá, da parte degli utenti, di scrivere il proprio codice
personalizzato per importare specifici tipi di file non molto diffusi.
Molto spesso vi é un accostamento tra la Business Intelligence e le Analitycs,
tuttavia esistono delle sottili differenze: la Business Intelligence é soprattutto
orientata a portare efficienza nei processi operativi aziendali, ottimizzandoli,
ed é quindi soprattutto focalizzata su ció che é successo nel passato e come
questo possa influenzare il comportamento attuale; le analytics, invece, anche
queste tramite un’attenta analisi dei dati storici e di quelli generati dai piú
disparati processi, aiutano ad identificare trend, a comprendere le informa-
zioni capaci di apportare cambiamenti nelle strategie aziendali. É essenziale
12comprendere che preparare i dati per le analytics é differente da memorizzarli
in modo efficiente nei data warehouse. Questi ultimi, infatti, si focalizzano
sul normale tipo di report/business intelligence e/o sulle query sviluppate ad
hoc. É molto importante preparare i dati per il processo di analisi in modo
che l’elaborazione effettiva venga eseguita in modo tempestivo. Gli addetti
dell’Information Tecnology (IT) giocano un ruolo sempre maggiore nel sup-
portare le aziende per sfruttare i dati e le analytics. Non é necessario che
i tecnici dell’IT comprendano la statistica e le analytics. É tuttavia impor-
tante che essi supportino i ”data scientist” nell’acquisizione dell’hardware e
del software appropriati per costruire una piattaforma di analisi che funzioni
efficientemente in modo che il business possa sfruttare al meglio l’insieme di
informazioni scaturenti dai propri dati, indipendentemente dalla dimensione
dei dati stessi e dalle piattaforme su cui essi sono memorizzati. Una trat-
tazione approfondita sulla preparazione dei dati esula dagli scopi di questo
lavoro. Qui giova soltanto menzionare che forme tipiche di memorizzazio-
ne dei database relazionali quali la Terza Forma Normale (3NF), non sono
considerate spesso la maniera piú efficiente e veloce per le elaborazioni delle
analisi statistiche dei Big Data. Tipicamente, i dati devono essere preparati
in un Analytic Base Table (ABT), che di solito contiene una riga di dati o un
record corrispondente ad un’entitá (ad esempio un cliente, un prodotto e cosı́
via), e molte variabili o colonne associate a quell’entitá. A seconda del par-
ticolare dipartimento o industria, non é affatto raro avere decine, centinaia
o addirittura migliaia di colonne che sono attributi associati a quella deter-
minata entitá. Questo consente l’esecuzione del processo di analisi nel modo
piú efficiente possibile, dando per scontato che vi sia un hardware adeguato
per le necessitá e che questo sia predisposto ed ottimizzato per l’analisi. [6]
Si é visto come uno degli aspetti piú importanti di SAS sia quello di avere
un’adeguata banca dati con cui poter lavorare. Un programmatore SAS puó
creare un dataset (set di dati) SAS usando un codice per il passaggio dei
dati oppure una specifica procedura SAS come ad esempio la IMPORT, che,
come suggerisce il nome, é progettata specificatamente per importare dati da
fonti esterne. La procedura IMPORT é presente nel modulo di SAS BASE
e lavora con file con estensione JMP (nativa di SAS) e con file delimitati,
quali ad esempio i CSV (Comma Separated Variable), cioé file i cui campi
sono separati dal delimitatore virgola. Queste capacitá di base, per la veritá
limitate, vengono ampliate con il programma SAS/ACCESS che consente di
importare, tra gli altri, anche i file Excel e Lotus. In analogia esiste anche la
procedura EXPORT per poter esportare dati a programmi esterni nei formati
consentiti. Tuttavia la grande flessibilitá di SAS di comunicare con l’esterno,
che é uno dei suoi punti di forza, non si esaurisce qui.
13Infatti esistono anche delle procedure speciali quali:
• PROC HADOOP: per interagire con dati memorizzati in Hadoop,
un ambiente di lavoro open source scritto in Java che consente la
memorizzazione distribuita di grandi moli di dati;
• PROC HDMD: che genera metadati basati su XML, un metalinguag-
gio che consente di definire e controllare il significato degli elementi
contenuti in un file (anche di testo). In particolare in questo modo
é possibile leggere dati Hadoop direttamente, senza un repository di
metadati quale Hive;
• PROC JSON: che permette il colloquio con dataset SAS e file esterni
in JSON (Java Script Object Notation), un formato di dati aperto,
basato su un sottoinsieme di linguaggio JavaScript.
Esiste, infine, anche la possibilitá di interfacciarsi con linguaggi di pro-
grammazione o addirittura di generare codice che viene eseguito in una JVM
(Java Virtual Machine). Il passo seguente alla creazione dei file é la prepa-
razione per la successiva fase di analisi. Nel percorso per passi successivi vi
sono delle procedure che consentono al programmatore di salvare il tempo e
lo sforzo nel preparare i dati per le analytics. La gestione dei dati analitici
(data management) e le analisi statistiche costituiscono un processo iterativo
che deve, quindi, essere ripetuto piú volte finché non é disponibile il risultato
finale, come mostrato in figura 4.1 [18].
Figura 4.1: Data management per le Analytics
144.2 Transposing
Un task molto comune quando si preparano i dati per le analytics é dato
dalla trasposizione delle variabili (memorizzate in colonne) in osservazioni
(memorizzate in righe). Di solito, questo passaggio puó richiedere molto
tempo sia per la necessitá di dover utilizzare numerose linee di codice per
risolvere il problema, sia per l’elevato tempo di esecuzione necessario per
ottenere il risultato. Un data scientist, tuttavia, ha la necessitá di vedere
i risultati dell’operazione prima di iniziare l’analisi. Anche in questo caso
SAS dimostra tutta la sua enorme potenza, mediante l’utilizzo della PROC
TRANSPOSE, che esegue facilmente questo compito, sollevando l’utente dal
lavoro necessario.
4.3 Trasformazione dei dati statistici e mate-
matici
I data scientist e gli analisti non solo hanno la necessitá della trasposizione,
ma spesso devono anche arricchire i dati con statistiche correlate ai dati
numerici esistenti all’interno della tabella stessa. SAS, ancora una volta,
rende questo arricchimento estremamente facile tramite procedure, quali ad
esempio la procedura MEANS, la quale fornisce gli strumenti per il riepilogo
dei dati per calcolare statistiche descrittive per variabili che interessano le
osservazioni. Ad esempio:
• calcola statistiche descrittive basate sui momenti;
• stima quantili che includono la media;
• calcola limiti di confidenza per la media;
• identifica valori estremi;
1
• esegue t-test.
Uno dei problemi che spesso si verifica é la mancanza di alcuni dati, do-
vuta alle cause piú svariate. Ad esempio durante l’acquisizione di dati da
sensori esterni puó esservi stata un’interruzione di collegamento o di tensione
1
Il test t (o, dall’inglese, t-test) é un test statistico di tipo parametrico con lo scopo di
verificare se il valore medio di una distribuzione si discosta significativamente da un certo
valore di riferimento. Differisce dal test z per il fatto che la varianza (σ 2 ) é sconosciuta.
[9]
15che ha impedito la lettura dei dati anche se solo per pochi istanti. Solita-
mente in questi casi si usa la tecnica dell’imputazione: i valori mancanti di
una particolare colonna sono sostituiti da valori derivati da tutto il resto dei
valori esistenti in quella colonna. Un semplice esempio di imputazione é di
calcolare un singolo valore statistico come ad esempio la media dei valori
esistenti e rimpiazzare tutti i valori mancanti di quella colonna con quel sin-
golo valore. I valori omessi, infatti, sono un problema nelle analisi statistiche
dei numeri: la maggior parte delle procedure statistiche di SAS esclude le
osservazioni con qualche valore variabile mancante dall’analisi. Queste osser-
vazioni sono chiamate ”casi incompleti”. Mentre l’uso nel caso in cui si hanno
a disposizione i dati completi é semplice, nei casi incompleti si perde, invece,
dell’informazione. Le imputazioni non tendono a stimare ogni valore omesso
attraverso valori simulati, ma piuttosto a rappresentare un campione casuale
del campione omesso. Alcune procedure SAS usano tutti i casi disponibili in
un’analisi, per esempio la PROC CORR stima una media variabile usando
tutti i casi non omessi per quella variabile, ignorando i possibili valori omessi
in altre variabili. La PROC CORR stima anche una correlazione usando
tutti i casi di valori non omessi per quel paio di variabili. La PROC MI,
presente nel modulo SAS/STAT, invece, permette ai programmatori di effet-
tuare imputazioni prima di effettuare ulteriori analisi. Un’ulteriore metodo
offerto da SAS é la procedura IMPUTE, che permette al programmatore di
imputare valori al volo mentre si sta eseguendo quella specifica procedura.
SAS fornisce anche i mezzi per aiutare ad individuare se vi sono dati omessi
mediante un task costruito all’interno di SAS Studio in ”Task and Utilities”.
Questa finestra permette all’utente anche di caratterizzare automaticamen-
te i dati, tramite l’uso del task Characterize Data. E’ questa un’operazione
estremamente importante da parte del programmatore per cercare di familia-
rizzare con i dati prima del loro utilizzo per le analisi statistiche. Infine, per
quanto riguarda la parte propedeutica di preparazione dei dati per l’analisi,
SAS STUDIO, tramite il task ”List Table Attribute”, permette all’utente
di visualizzare una serie di informazioni per certi versi simili a quelle di un
dizionario dati.
16Capitolo 5
Analisi con il Software SAS
Il passo successivo é l’analisi statistica dei dati che prevede una conoscenza
piú approfondita dei dati sui quali si sta per lavorare. Ad esempio occorre
conoscere quante variabili sono di natura di tipo carattere piuttosto che nu-
merico e gli attributi correlati alle variabili quali la lunghezza, il numero di
valori omessi, il numero di valori unici per ogni colonna. Eseguire le analytics
é talvolta la parte piú facile di tutto il progetto poiché definire il problema
correttamente ed ottenere i dati necessari nella giusta forma tipicamente
prende fino all’80% dell’intero lavoro di un progetto [18]. L’analisi statistica
comprende il data mining, l’ottimizzazione e/o il forecasting. Ad alto livel-
lo queste tre aree di analisi forniscono informazioni descrittive, predittive e
prescrittive per aiutarci a prendere migliori decisioni basate su informazioni
guidate dai dati. SAS dispone di soluzioni molto potenti nel campo della
Analytics:
• SAS Enterprise Miner (data miner),
• SAS Factory Miner (predictive),
• SAS Forecast Server (forecasting).
5.1 Analisi descrittiva
L’analisi descrittiva (o statistica) utilizza l’aggregazione dei dati ed il data
mining per guardare nel passato e rispondere alla domanda: ”What has hap-
pened? ” (Cosa é successo?), cioé ”descrive” il passato riassumemendo dati
grezzi per renderli interpretabili dall’utente. Le analisi descrittive sono utili
perché permettono di imparare dal comportamento passato e di capire come
questo possa influenzare il futuro. La maggioranza delle analisi statistiche
17cade, ancora, in questa categoria: somma, medie, percentuali, ecc.. SAS BA-
SE fornisce alcune procedure, anche molto avanzate, orientate alla gestione
dell’analisi descrittiva: la giá vista CORR, FREQ e UNIVARIATE.
5.2 Analisi predittiva
L’analisi predittiva utilizza, invece, modelli statistici e tecniche di previsione
per capire il futuro e rispondere alla domanda: ”What could happen? ” (Cosa
potrebbe succedere?): queste analisi statistiche servono per dare previsioni
sul futuro e forniscono alle organizzazioni informazioni utili basate sui dati
esistenti. Queste statistiche cercano di prendere i dati che sono a disposizione
e di riempire i dati mancanti con le ipotesi migliori. Esse combinano i dati
storici raccolti da differenti sistemi informativi aziendali (ERP, CRM, HR e
POS) per identificare pattern dei dati a partire dai quali applicare modelli
statistici e algoritmi per catturare le relazioni fra i diversi dataset. L’analisi
statistica predittiva puó essere utilizzata ad esempio in un’organizzazione a
partire dalla previsione del comportamento dei clienti e dei modelli di acqui-
sto all’identificazione delle tendenze delle attivitá di vendita, aiutando anche
a prevedere la domanda di acquisti per la catena di fornitura. Un’applica-
zione comune che la maggior parte delle persone conosce é l’uso dell’analisi
predittiva per produrre un punteggio di credito. Questi punteggi sono usa-
ti successivamente dai servizi finanziari per determinare la probabilitá che i
clienti effettuino i pagamenti futuri in tempo. Lo strumento SAS/STAT for-
nisce piú di 90 procedure per eseguire analisi statistiche e viene costantemente
aggiornato con nuovi metodi e tecniche. Alcune delle analisi che SAS/STAT
fornisce sono, ad esempio, varianza, analisi di cluster, imputazioni multiple,
analisi non parametrica, analisi psicometrica, regressione.
L’analisi di previsione coinvolge sempre serie storiche di dati che si sono
raccolti nel tempo. I prevalenti usi delle procedure di SAS/ETS avvengono
nei campi dell’analisi economica, nelle analisi di serie temporali, nella mo-
dellazione e nei rapporti finanziari. Sebbene queste serie siano soprattutto
utilizzate in questi campi, esse trovano anche un largo impiego nei piú di-
sparati settori. Due procedure caratteristiche della manipolazione dei dati
sono TIMEDATA ed ARIMA. La prima accumula i dati temporali rilevati
in maniera sequenziale secondo una marcatura temporale, mentre la seconda
analizza ed effettua previsioni su dati temporali equidistanziati nel tempo.
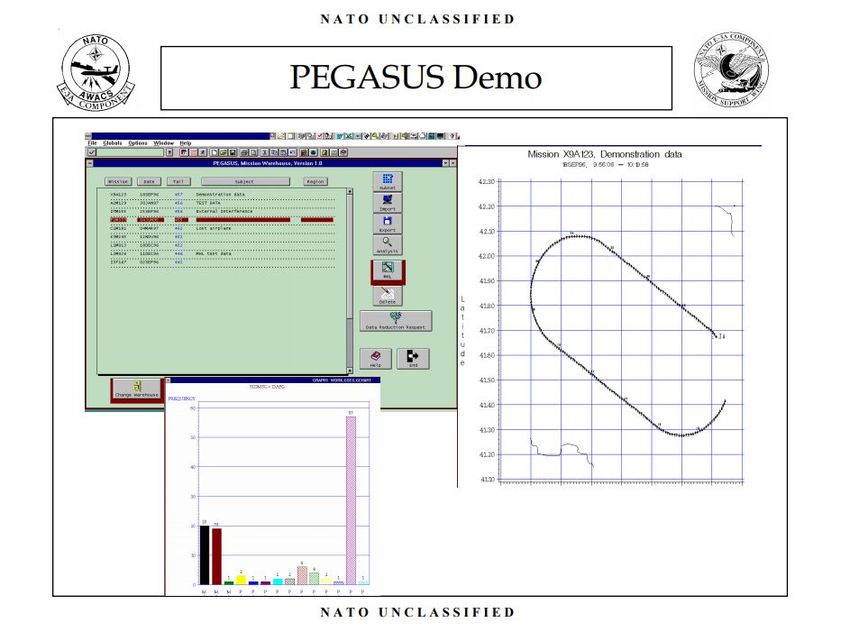
Nella figura che segue é rappresentato uno di questi impieghi non pret-
tamente tradizionale di acquisizione dati in streaming: la ricostruzione della
rotta, in un determinato intervallo di tempo, del velivolo AWACS sui cieli
dell’Europa.
18Figura 5.1: Ricostruzione rotta Awacs [17]
5.3 Analisi prescrittiva
L’analisi prescrittiva utilizza algoritmi di ottimizzazione e simulazione per
suggerire possibili risultati e risposte alla domanda ”What should we do? ”
(Cosa dovremmo fare?) e consente agli utenti di ”prescrivere” una serie
di diverse azioni possibili e guidarli verso una soluzione. In particolare le
analisi prescrittive utilizzano una combinazione di tecniche e strumenti come
regole di business, apprendimento automatico e procedure di modellazione
computazionale. Queste tecniche vengono applicate in base all’input di molti
dataset, tra cui dati storici e transazionali, acquisizione di dati in tempo reale
e Big Data.[7]
Il prodotto SAS che fornisce elementi di analisi prescrittiva é SAS Decision
Manager, che unisce l’analisi predittiva e prescrittiva per una piú accurata
ed efficace decisione. In questo prodotto sono integrate regole di business
e modelli analitici in un’unica interfaccia, gestita con la stessa logica per
l’esecuzione di tipo Batch o Real-Time.
19Capitolo 6
I report con SAS
6.1 L’attivitá di report
L’attivitá di report é certamente la modalitá piú diffusa per rendere noti i
risultati delle analisi effettuate. SAS fornisce diverse opzioni, da quelle piú
elementari a quelle estremamente sofisticate, per effettuare report, mediante
l’uso di alcune procedure di base e l’uso degli ODS (Output Display System)
che é una parte di SAS/BASE che produce output in una molteplice varietá
di differenti formati. SAS Studio fornisce task di default per effettuare grafici
basilari e generare il codice necessario per produrre questi grafici.
Figura 6.1: SAS Visual Analytics
20Per default gli output in SAS Studio producono risultati nei seguenti
formati: HTML5, PDF ed RTF. L’utente puó cambiare gli stili di default o i
risultati di output nelle finestre di preferenza di SAS Studio. Uno dei Report
piú elementari che ogni sistema puó generare é una tabella che stampa le
colonne e le righe a partire da una tabella di dati. SAS Studio fornisce
all’utente un task elementare chiamato ”List Data” che stampa questo tipo
di report. Accanto a queste possibilitá vi sono quelle offerte da SAS Visual
Analytics, come si puó vedere in figura 6.1.
6.2 Procedure basilari per il report
Come giá accennato, SAS é dotato di procedure progettate anche per stampa-
re report: ad esempio le procedure base per i grafici ed i plottaggi producono
risultati elementari usando il set di caratteri ASCII, persino su sistemi che
non supportano la grafica. Le procedure fornite con SAS BASE sono:
• PRINT: stampa le colonne e le righe di una data set SAS in forma-
to tabellare di base, utilizzando tutte o soltanto alcune delle variabili,
a seconda di come viene richiesto dall’utente. É possibile creare una
varietá di report che vanno da un semplice elenco a un report altamen-
te personalizzato che raggruppa i dati e calcola totali e subtotali per
variabili numeriche.
• TABULATE: simile alla PRINT, ma consente report piú articolati:
crea una varietá di tabelle che vanno da quelle piú semplici a quelle piú
complesse e personalizzate che possono includere statistiche descrittive
per alcuni o per tutti i dati usati nel report.
• REPORT: combina le funzioni delle procedure PRINT, MEANS e
TABULATE con le funzionalitá del DATA step in un unico strumento
in grado di produrre una varietá di report. Questa procedura puó, ad
esempio, produrre report riepilogativi in cui ogni riga puó rappresen-
tare un riassunto o un’aggregazione di piú osservazioni. É possibile
utilizzare PROC REPORT in diversi modi, in un ambiente senza fine-
stre, con l’opzione NOWINDOWS in modalitá di linea batch oppure in
ambiente a finestre, con o senza la possibilitá interattiva del prompt.
6.3 Possibilitá avanzate per i report
Nelle versioni precedenti di SAS, per quanto la parte grafica avesse la sua
rilevanza, la creazione di grafici con procedure statistiche richiedeva in genere
21ulteriori passaggi di programmazione, quali la creazione di file di output
con i valori da tracciare, la modifica di questi file con una PROC STEP e
l’utilizzo di procedure SAS/GRAPH tradizionali per produrre i grafici. Oggi
questa necessitá di ulteriore programmazione per ottenere i grafici é ridotta
dal modulo ODS GRAPHICS, estensione di ODS che vedremo nel seguito. Il
sistema di output rende possibile all’utente la personalizzazione dei contenuti
dell’output stesso scegliendo in che modo l’output debba essere formattato
per la presentazione. In SAS, un PROC o un DATA step forniscono i dati
grezzi ed il nome della tabella che contiene le istruzioni di formattazione.
L’output classico di SAS é progettato per una tradizionale stampante a linee
e questo tipo di output presenta delle limitazioni notevoli che impediscono
di ottenere il massimo valore dai risultati.
6.3.1 Output Delivery System (ODS)
Output Delivery System (ODS) é progettato per superare i limiti dell’output
SAS tradizionale. Esso fornisce un metodo per distribuire l’output in una
grande varietá di formati e rende l’output formattato facilmente accessibi-
le. L’ODS fornisce dei templates o degli stili di templates che indirizzano
la struttura dell’output sia per i DATA step sia per le PROC ed i program-
matori possono utilizzare questi template cosı́ come sono oppure personaliz-
zarli e/o crearne di nuovi per il loro uso/riuso. Questo meccanismo é molto
potente perché quando vengono aggiunti nuovi formati ODS da SAS o dal-
l’utente essi diventano utilizzabili anche da tutti i preesistenti report. ODS
salvaguarda quindi il tempo e lo sforzo impiegati dall’utente in quanto per-
mette di produrre lo stesso report in multipli formati durante l’esecuzione
del codice. In questo modo é possibile produrre una versione ”Web Based”
o ”HTML Based” di un report, mentre allo stesso tempo puó essere scritta
una versione PDF che puó essere memorizzata in un archivio e addirittura,
contemporaneamente, una versione in formato Power Point.
6.3.2 SAS/GRAPH
SAS/GRAPH permette di produrre moltissimi grafici e plottaggi utilizzando
le cinque procedure grafiche di ODS che vengono spesso definite come le
procedure ODS Statistical Graphics. Esse sono:
• SGPLOT: crea plottaggi a singola cella con una varietá di tipo di
caratteri di plottaggio e sovrapposizione;
• SGPANEL: crea pannelli di classificazione per uno o piú variabili di
classificazione;
22• SGSCATTER: crea pannelli di plottaggi di dati disseminati con adat-
tamenti;
• SGRENDER: produce grafici da template che sono scritti in GTL
(Graph Template Language) oppure da file SGE (SAS ODS Graphics
Editor);
• SGDESIGN: crea grafici di output a partire da file creati con l’appli-
cazione ODS Graphic Designer. [13]
In definitiva, le procedure ODS Graphics sono molto potenti in quanto
consentono di creare grafici statistici molto complessi che utilizzano i principi
della grafica effettiva per comunicare accuratamente i risultati delle analisi ai
clienti. La minima codifica richiesta rende possibile all’utente di focalizzarsi
sull’analisi statistica piuttosto che sull’apparenza visiva del grafico. Esiste,
infine, la possibilitá di sviluppare e salvare proprie parti di codice per la
grafica, tramite le opzioni Task e Snippet di SAS Studio, che possono essere
richiamate all’occorrenza.
23Capitolo 7
Altri linguaggi di
programmazione di SAS BASE
Allorquando i Big Data vengono processati laddove sono memorizzati, i dati
stessi non necessitano di essere spostati o copiati all’interno della rete. Nel
linguaggio DS2, che é un altro linguaggio proprietario di programmazione
di SAS incluso nel SAS BASE, é fondamentale conoscere dove i dati sono
memorizzati. Questo é specialmente vero nei casi in cui la logica SAS Data
Step puó essere trasformata in DS2 in modo da permettere a quella logica di
girare in ambienti dove DS2 é supportato mentre il SAS Data Step non lo é.
Gli ambienti di elaborazione che sono piú importanti in merito al supporto
di DS2 nell’ambito dei Big Data Analytics sono SAS Viya, CAS (Cloud
Analytics Server), SAS Embedded Process ed il motore SAS ESP (Event
Stream Processing). Inoltre, simile al DS2, il linguaggio Federated SQL (o
FedSQL) é stato aggiunto al SAS BASE e gioca un ruolo nell’elaborazione
dei Big Data e dei Big Data Analytics.
7.1 Il linguaggio di programmazione DS2
DS2 é un linguaggio procedurale che ha variabili, ambito, metodi, packages,
istruzioni di flusso di controllo, istruzioni di tabelle di I/O e persino istruzio-
ni di programmazione parallela. I metodi ed i packages consentono al DS2
la modularitá e l’incapsulamento dei dati. DS2 inoltre rende possibile l’in-
serimento di istruzioni SQL direttamente nel set di istruzioni, unendo cosı́
le possibilitá di due linguaggi di manipolazione dei dati molto potenti. DS2
supporta molteplici tipi di dati, oltre al semplice ”char” e ”numeric” del SAS
BASE [8] e si interfaccia con differenti formati di dati sorgente, come ad
esempio:
24• DB2 sia Unix che Windows;
• HADOOP;
• MySQL;
• Database Compatibili-ODBC (quali Microsoft SQL Server);
• Oracle;
• SAP.
Oltre, ovviamente, a file in formato SAS.
Il DS2 viene tipicamente usato in applicazioni che devono fornire le se-
guenti azioni:
• Precisione aggiuntiva ottenuta dall’uso di nuovi tipi di dati (ricordiamo,
come giá detto in precedenza che, rispetto a SAS BASE, supporta
numerosi altri tipi);
• Elaborazione di thread per il calcolo intensivo richiesto da programmi
SAS intensamente computazionali. Potrebbe essere vantaggioso creare
un programma di thread in modo che i dati vengano distribuiti su piú
processi per diventare piú efficienti;
• Utilizzo di metodi e packages per la facile implementazione di moduli
di codice riutilizzabile (in DS2, tutto il codice deve risiedere all’interno
di un metodo): é possibile scrivere metodi personalizzati che possono
essere archiviati per uso futuro e che riducono la necessitá di ricreare
il codice ogni volta;
• Embedded PROC FedSQL e potenza del DATA step: in SAS é anche
possibile incorporare le query FedSQL nell’istruzione SET all’interno
di DS2. Quando una query viene utilizzata nell’istruzione SET, le righe
risultanti diventano l’input per il codice DS2 rimanente;
• Il codice puó essere eseguito all’interno di database estremamente pa-
ralleli come Teradata, Hadoop e Greenplum.
Inoltre DS2 puó essere utilizzato all’interno del motore SAS ESP che sposta
le analisi statistiche fuori dal sistema o all’interno di unitá che compongono
IoT.
La tabella seguente, in figura 7.1, riporta le differenze piú importanti tra DS2
e DATA step [14].
25Figura 7.1: Differenza tra DS2 e DATA Step
7.2 Il linguaggio di programmazione Federa-
te SQL (FedSQL)
Il linguaggio di programmazione SAS FedSQL é un’implementazione proprie-
taria di ANSI SQL 1999 Core Standard. FedSQL fornisce un modo scalabile,
organizzato a thread e ad alte prestazioni per accedere, gestire e condivi-
dere dati relazionali di molteplici sorgenti. Laddove possibile, le query di
FedSQL sono ottimizzate con algoritmi multi-thread per risolvere operazioni
su larga scala. Nelle applicazioni, FedSQL fornisce una sintassi SQL comu-
ne per tutte le sorgenti di dati. FedSQL puó dunque definirsi un dialetto
SQL indipendente dal fornitore che accede ai dati da diverse sorgenti senza
dover sottomettere query nei dialetti SQL specifici per quella sorgente di da-
ti. Inoltre una singola query FedSQL puó ottenere dati da diverse sorgenti
e ritornare come risultato una singola tabella. I benefici dell’utilizzo della
procedura FedSQL si evidenziano particolarmente nelle seguendi situazioni:
• occorre utilizzare piú tipi di dati;
• é necessaria una maggiore precisione;
• si elaborano dati provenienti da sorgenti di dati esterni.
26Capitolo 8
Architettura
Se si lavora con pochi dati che si adattano alle potenzialitá di un PC, la
capacitá di elaborazione é influenzata da fattori quali la velocitá del proces-
sore/i, la quantitá di memoria e lo spazio su disco, ma, con le caratteristiche
hardware di oggi, non é difficile assicurare prestazioni adeguate. Con i Big
Data, invece, é di vitale importanza avere il proprio ambiente di sviluppo per
l’elaborazione statistica adeguatamente ed opportunamente configurato ed i
risultati finali ottenuti dalle analisi devono essere consegnati in tempo utile
per rendere l’organizzazione capace di continuare a crescere ed a migliorarsi.
8.1 Le piattaforme per SAS in-database ed
in-memory
Quado si parla di Big Data a livello aziendale, l’ambiente di elaborazione
dovrebbe essere almeno un server o una rete (”Grid”) SAS per avere l’hard-
ware di potenza necessaria per poter eseguire le analisi statistiche in tempi
accettabili. La mole di dati da trattare é cresciuta cosı́ tanto nel tempo che
persino i server e le Grid di SAS non sono capaci di poter gestire il volume,
la capacitá e la varietá dei Big Data. Come risultato, SAS ha continuato ad
innovare e a rispondere alle necessitá della clientela sviluppando nuove tecni-
che e soluzioni che coinvolgono le capacitá di elaborazione ”in-database” ed
”in-memory”. Ad esempio, quando si utilizza l’elaborazione convenzionale
per accedere ai dati all’interno di una sorgente dati, SAS chiede al motore
SAS/ACCESS tutte le righe della tabella in esame. Il motore SAS/ACCESS
genera allora un’istruzione SQL ”SELECT *” che viene passata all’origine
dei dati. L’istruzione SELECT recupera tutte le righe nella tabella e il moto-
re SAS/ACCESS le restituisce a SAS. A mano a mano che il numero di righe
nella tabella si incrementa nel tempo, tuttavia, la latenza della rete aumenta,
27poiché cresce la quantitá di dati trasmessi sulla rete stessa. L’elaborazione
di SAS in-database, invece, integra soluzioni SAS, processi analitici SAS e
fornitori di dati di terze parti. Utilizzando l’elaborazione SAS in-database,
é possibile eseguire modelli a punteggio (scoring models), alcune procedure
SAS, programmi thread DS2 e query SQL formattate all’interno dell’origine
dati. La modalitá in-database quindi sposta l’elaborazione di SAS in un si-
stema di memorizzazione di dati tale che i dati non devono essere copiati nel
server SAS, ma permette ai sistemi di elaborazione sottostanti di eseguire
direttamente le analisi. Allo stesso modo la tecnologia in-memory riduce gli
spostamenti dei dati da disco a disco nella rete e permette a SAS di caricare
i dati in un motore di analisi statistiche in-memory, effettuando le analisi sui
dati usando tutte le CPU e le cache di memoria, separate e indipendenti,
come se esse fossero una singola grande area condivisa.[18]
8.2 Architettura orientata ai servizi e micro-
servizi
Durante gli anni ’90, SAS rilasció sul mercato la seconda versione della piat-
taforma, basata su metadati e progettata per supportare l’intero ciclo di vita
delle analisi statistiche end-to-end. Essa includeva la gestione dei dati, la pre-
parazione di analisi statistiche, lo sviluppo e la consegna delle osservazioni
dei dati analitici alla produzione. Poiché era progettata per essere conforme
alla Service Oriented Architecture (SOA - architettura orientata ai servizi),
aveva una struttura monolitica. Questo comportava, tuttavia, che se una
parte della SOA dell’ambiente SAS necessitava di essere aggiornata o modifi-
cata, allora l’intero sistema doveva essere messo off-line per un certo tempo.
Per poter ovviare a questo inconveniente, recentemente sono state introdotte
nuove piattaforme basate su microservizi, tra cui molte sono piattaforme Big
Data, comprese le piattaforme Cloud. I microservizi hanno un differente ap-
proccio rispetto alla SOA in quanto forniscono specifiche funzionalitá piccole
come ambito, ma che, raggruppate insieme, forniscono una piattaforma di
funzionalitá a livello aziendale. I microservizi permettono ai sistemi di con-
tinuare a funzionare senza la necessitá di interruzione quando vi sono degli
aggiornamenti perché essi sono indipendenti l’uno dall’altro e perció possono
essere fermati o attivati senza impattare sull’intero sistema. Pertanto i mi-
croservizi forniscono un ambiente con maggiore resilienza. Questo consente
al sistema di essere ripristinato piú velocemente in caso di guasti poiché per-
mette di poter eseguire piú di un’istanza di un particolare servizio cosı́ che il
sistema funziona ancora se una di queste istanze interrompe l’esecuzione per
28un qualsivoglia motivo. La figura 8.1 rappresenta l’architettura di SAS Viya
che implementa i microservizi.[18]
Figura 8.1: Architettura Viya
La SOA ed i microservizi condividono caratteristiche comuni, quali ad
esempio permettere a diversi team di sviluppare differenti funzionalitá. Con
la SOA tutti gli sviluppatori devono necessariamente capire il meccanismo
di comunicazione comune condiviso nella piattaforma, mentre con i micro-
servizi, non c’é un meccanismo comune di comunicazione perché i servizi
stessi interagiscono l’uno con l’altro tramite le API. Nella SOA tutti i servizi
condividono un sistema di memorizzazione di dati comune, mentre nei mi-
scroservizi ogni servizio puó contenere la sua memoria indipendente di dati.
Un servizio all’interno dell’ambiente SOA puó contenere microservizi, men-
tre un microservizio non puó contenere un servizio SOA. Indipendentemente
dal tipo di architettura scelto, in questo caso, gli sviluppatori devono preoc-
cuparsi della complessitá di quella particolare architettura e del lavorare in
ambienti distribuiti.
8.3 Server e Grid SAS
La piattaforma SAS puó essere eseguita su un singolo server basato su Mul-
tiProcessore Simmetrico (SMP), ovvero i programmi vengono eseguiti uti-
lizzando piú CPU che condividono sistema operativo e memoria. In questo
caso, si parla di ambiente di condivisione totale. La piattaforma SAS é stata
progettata per ottenere il meglio nell’ambiente multiprocessore con differenti
29opzioni di configurazione ed inoltre, negli anni, alcune procedure SAS sono
state riscritte per ottenere il pieno vantaggio dei sistemi multi-core e multi-
thread associati con i progressi fatti con le CPU. I programmatori SAS non
devono imparare nuove sintassi per queste procedure, sebbene essi potrebbero
avere necessitá di aggiungere nuove opzioni ai programmi esistenti, in quanto
i programmi continuano a girare anche sulle nuove macchine senza necessitá
di modifiche. Sarebbe, tuttavia, opportuno settare le nuove opzioni della con-
figurazione per massimizzare i vantaggi e l’incremento delle prestazioni che
la nuova configurazione comporta. Girare su un singolo server significa che
per migliorare le prestazioni o per aggiungere piú utenti all’ambiente senza
impattare i tempi di risposta correnti, sará necessario scalare il sistema ver-
so uno piú potente e ció significa aggiungere o aggiornare il server esistente
con una diversa CPU, memoria e/o sistemi di memorizzazione. Gli ambienti
basati su un unico server sono ancora molto comuni ed in alcuni casi hanno
piú validitá. Quando si parla di analisi statistica di Big Data, invece, questo
tipo di ambiente non é molto adatto a causa dello sforzo e della spesa che
comporterebbe il continuo scalamento dei sistemi per adeguarsi alla cresci-
ta delle necessitá elaborative. Questo é il motivo per cui le organizzazioni
che lavorano con Big Data ed in particolar modo con le analisi statistiche
dei Big Data, preferiscono un ambiente di tipo distribuito che é fornito uti-
lizzando un’architettura ad elevato parallelismo (MPP - Massively Parallel
Processing). Questo é anche il motivo per cui SAS ha sviluppato negli anni
2000 la nuova piattaforma chiamata SAS GRID Manager. Questo ambiente
di processo distribuito rende possibile lo ”scalamento laterale”. Con ció si
intende la possibilitá di aggiungere dinamicamente server addizionali, come
nuovi nodi all’interno della griglia SAS, senza che avvenga alcun cambio al-
l’hardware esistente. Questo é possibile usando server piú economici quali i
moderni blade. Si puó, infatti, anche partire con una griglia SAS a due no-
di e farla crescere progressivamente, per adeguarla alle accresciute necessitá
di prestazioni, semplicemente incrementando la ”dimensione” dei sistemi di
elaborazione dei dati. SAS ha risposto con diverse offerte: una di queste é la
SAS Scalable Performance Data Server (SPDS), progettata come un sistema
MPP che suddivide grandi file di dati, in piccoli sottoinsiemi e memorizza
questi sottoinsiemi in un ambiente di server distribuito. [18]
8.4 Verso Hadoop
Lo sviluppo e l’uso di SPDS da parte degli utenti anticipa la disponibilitá di
Hadoop di molti anni in quanto l’architettura di entrambi i sistemi é simile
poiché entrambi fanno uso di MPP. Questo dimostra che gli utenti SAS erano
30Puoi anche leggere

















































