3D Face Recognition Sistemi Biometrici: Gabriele Sabatino
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Sistemi Biometrici:
3D Face Recognition
Gabriele Sabatino
Email: gsabatino@unisa.it
www.dmi.unisa.it/people/nappi/
www.dmi.unisa.it/people/sabatino/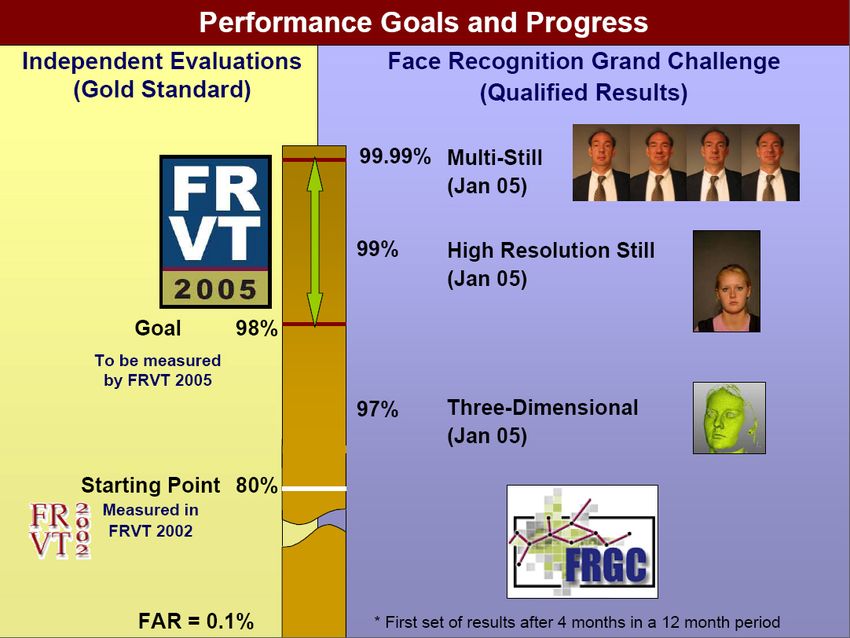
Introduzione
z Le problematiche tipiche del riconoscimento facciale a due dimensioni
z 3D Face Recognition
z Alcuni concetti di computer grafica 3D
z Il processo di riconoscimento facciale 3D:
{ Acquisizione
{ Pre-processing
{ Estrazione delle features
{ Classificazione e Verifica
z I sistemi multimodali 2D+3D
z Face Recognition Grand Challenge
3D FACE RECOGNITION z Il riconoscimento facciale a tre dimensioni (3D Face Recognition) è la modalità di riconoscimento facciale nel quale è utilizzata la geometria tridimensionale del volto umano. z Il vantaggio nell’uso del tridimensionale è l’avere una rappresentazione precisa della superficie geometrica del volto, non una rappresentazione “di come la luce viene riflessa sulla superficie del volto”. z La maggior limitazione negli algoritmi di riconoscimento facciale a tre dimensioni è nella fase d’acquisizione. z Correntemente, il 3D Face Recognition è ancora un campo di ricerca “aperto”, sebbene alcuni prodotti basati sul riconoscimento 3D del volto siano già in commercio.
Riconoscimento Facciale:
Problematiche tipiche
1. Condizioni di luminosità
Importanza
2. Posa (orientamento della testa)
3. Espressioni facciali
4. Occlusioni (auto-occlusioni)
5. Età
Gli algoritmi di riconoscimento
facciale 2D presentano
problemi per le variazioni di:
{ Illuminazione
{ Posa
{ Espressione facciale
Face Recognition Vendor Test
z Al fine di evidenziare i limiti delle tecniche esistenti e
aumentarne le prestazioni, con cadenza biennale o
triennale viene indetto il FRVT, in cui tutti i sistemi di
riconoscimento del volto vengono testati congiuntamente
al fine di stabilire quali di essi è il migliore e quali sono i
risultati raggiunti dalla ricerca.
z Il FRVT ha dimostrato
“empiricamente” che le
prestazioni degli algoritmi
2D si abbassano in
presenza di variazioni di
luminosità e posa.
Face Recognition Vendor Test:
Testing con le variazioni di luminosità
z FRVT 2002 ha dimostrato che le performance degli algoritmi 2D
vengono drasticamente ridotte se si usano immagini dello stesso
soggetto prese con illuminazioni molto diverse tra loro
{ (immagini indoor & outdoor scattate nello stesso giorno).
Alcuni esempi di immagini FRVT
Indoor & Outdoor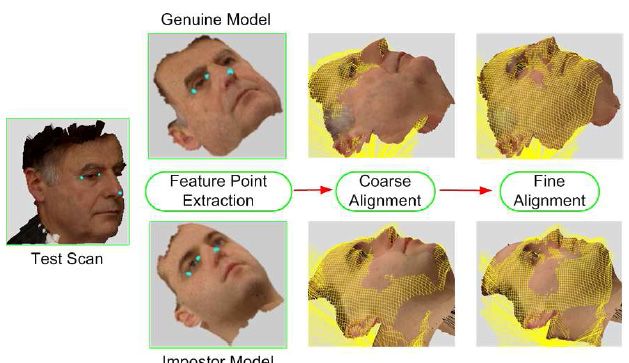
Face Recognition Vendor Test:
Testing con le variazioni di posa
z FRVT 2000 e FRVT 2002 ha dimostrato che un altro dei task più difficili per
i sistemi di riconoscimento facciale basati su due dimensioni è riconoscere
quei volti che non sono rappresentati in posa frontale.
z La maggior parte dei sistemi di riconoscimento facciale 2D hanno elevate
prestazioni quando l’immagine è frontale.
z Se la posa del volto cambia (sia orizzontalmente che verticalmente) le
performance decrescono.
posa frontale
posa up/down
posa left/right
Un caso reale: il “lupo” Liboni
z Esiste un algoritmo di face recognition capace di verificare che le due
immagini appartengono alla stessa persona?
z La causa dei limiti dei sistemi bidimensionali di riconoscimento facciale
proviene dalla tipologia di dati utilizzati per verificare la somiglianza tra due
volti:
{ Immagini fotografiche, videotape, sequenza di immagini di un sistema di
videosorveglianza.
z I sistemi di riconoscimento facciale 2D lavorano su una rappresentazione
bidimensionale di una scena tridimensionale.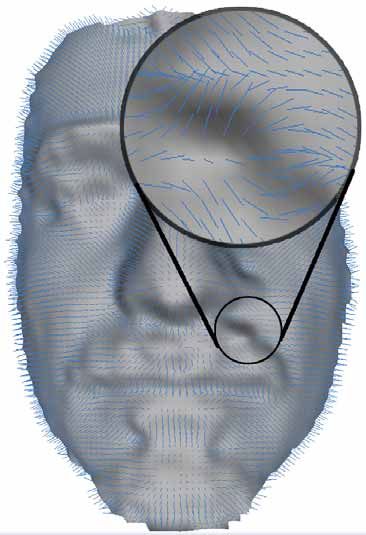
Percezione: illusioni
Percezione: illusioni
Percezione: illusioni
3D Face Recognition
z Le promesse del 3D face recognition sono:
{ Alta precisione di riconoscimento necessaria per applicazioni High-Security
{ I problemi di posa ed illuminazione posso essere risolti
{ Migliore localizzazione delle feature facciali
VANTAGGI SVANTAGGI
z La tecnologia 3D è più efficace di z Gli hardware di acquisizione 3D sono costosi
quella a due dimensioni perché è in
grado di analizzare molta informazione (il costo aumenta con la precisione di
in più, cosa che rende più preciso il acquisizione)
riconoscimento z Alcuni sistemi di acquisizione 3D sono
z Un sistema di riconoscimento 3D è invasivi:
meno sensibile alle condizioni di
illuminazione { Tempi di acquisizione lunghi
z Il problema della posa può essere { Alcuni sistemi scanner possono essere
risolto con il riallineamento i volti. addirittura pericolosi per la retina (laser)
z Le occlusioni possono essere
facilmente trovate con un processo di z Sostituire i dispositivi 2D (macchine
segmentazione fotografiche, videocamere, ecc.) con nuove
z Si possono generare automaticamente apparecchiature 3D è un processo che
delle espressioni facciali sintetiche richiede tempo e dei costi elevatiRappresentare un volto
2D
Intensity Image: una immagine bidimensionale in cui ogni pixel rappresenta
l’intensità della luce riflessa sul quel punto. Il colore di un pixel è dato da
come la luce viene riflessa sulla superficie.
3D
Range Image: una immagine bidimensionale in cui ogni pixel rappresenta la
distanza tra la sorgente e il punto
Shaded Model: una struttura di punti e poligoni collegati tra loro in uno spazio
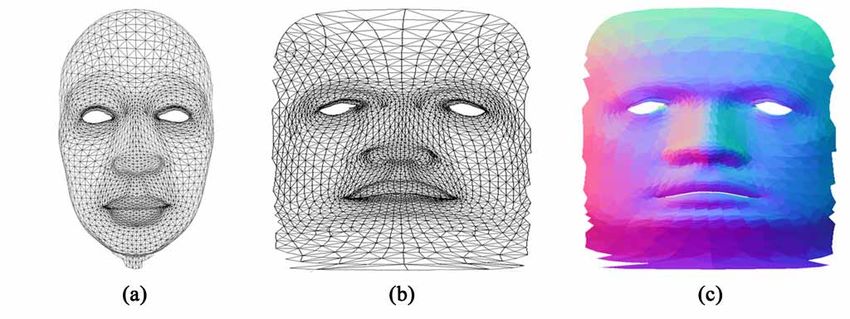
a tre dimensioniInput Data
Range image
Volto 3D Model 3D Model + Texture
Texture mapAlcuni concetti di geometria 3D
zVertici
zVettori
zSegmenti
R3
Y
zPoligoni
zNormali Z
zMesh X
zTexture Mapping
zRenderingVertici e Poligoni
z Un vertice specifica una z Un vettore specifica una
locazione di un punto direzione ed una
{ Non ha dimensione magnitudine (lunghezza)
{ È definito da una tripla di { Non ha locazione
valori (x,y,z) che ne indica { È definito da una tripla di
le coordinate valori (dx, dy, dz) che
indica la direzione del
vettore.Segmenti e Poligoni
z Un segmento è un z Un poligono è formato
percorso lineare che da una sequenza
unisce due vertici “complanare” di punti uniti
{ Può rappresentare un lato da segmenti
di un poligono. { Il triangolo è il tipo
comunemente utilizzato.Mesh Poligonale
z Una mesh poligonale è un insieme di poligoni con alcune
proprietà. Alcune di queste proprietà sono:
{ Ogni lato appartiene almeno ad una poligono
{ Ogni vertice ha almeno due lati
NO!
NO!Normali
z Una normale di un poligono
è un vettore perpendicolare ad
un piano o un poligono
{ È utile per capire la posa e
l’orientamento di un poligono
z La normale di un vertice è la
risultante della somma delle
normali dei poligoni a cui il
vertice appartiene
{ È utile per capire la posa e
l’orientamento di un verticeTexture Mapping
Una texture (o tessitura)
aggiunge dettaglio alla
superficie di un oggetto 3D
Geometry Texture Texture Map
Come decidiamo dove
posizionare ogni pixel della
tessitura sulla superficie 3D?Colori e Texture Map
z È possibile assegnare un colore Un altro modo per assegnare i colori
ad un poligono. In questo caso il ad una mesh è “mappare”
poligono ha un singolo colore, un’immagine 2D lungo la
uniforme, lungo la sua superficie. superficie della mesh.
z È possibile assegnare un colore z Texture: Questo termine indica le
ad un vertice, in questo caso il mappe (immagini bitmap o shader
colore del poligono è la procedurali) che vengono
combinazione dei colori dei suoi applicate sulle superfici dei
vertici . poligoni degli oggetti 3D.
z Questa combinazione può essere z Texture Mapping: Consiste nella
di diversi tipi: procedura utilizzata la posizione e
{ Flat: il colore del poligono è uno l’orientamento preciso di una
ed è la somma dei colori dei tessitura sulla superficie
vertici dell’oggetto 3D. Queste immagini
{ Smooth: il colore del poligono in fase di rendering costituiranno il
non è uniforme (unico) ma cambia colore, la luminosità, la riflessione,
all’avvicinarsi dei suoi vertici. ecc. delle superfici 3D.Planar Mapping / Cylindrical Mapping
z La mappatura di tipo planare consiste z La metodologia di proiezione è basata
in una sorta di proiezione piana (da cui sulla forma del cilindro che avvolge
il nome) dell’immagine bitmap sulla completamente il modello 3D.
superficie del modello 3D.
z È efficace per quei modelli 3D che
z È usata per quelle tipologie di oggetti possono essere completamente inclusi
che sono relativamente piatti o che all’interno della forma del cilindro.
risultano completamente visibili
attraverso un angolo qualsiasi della
cameraBox Mapping / Spherical Mapping
Valgono le stesse considerazioni del Cylindrical Mapping ma con
forme geometriche diverse.Rendering z Rendering (presentazione fotorealistica) è il processo di generazione di un'immagine bidimensionale a partire da una descrizione (mesh) degli oggetti tridimensionali. z Il rendering di un modello 3D genera un’immagine bidimesionale (frame) che rappresenta il modello da un preciso punto di vista.
Rappresentazione discreta 2D
z Un’immagine bidimensionale e un modello
poligonale sono rappresentazioni discrete
di una scena reale.
z Per esempio, la discretizzazione di una
immagine 2D dipende dal numero di pixel
utilizzati.
IIpixel
pixelininuna
una
immagine
immaginesono sono
spazialmente
spazialmente
equodistribuiti
equodistribuiti
E’
E’possibile
possibileleggere
leggere
l’informazione all’interno
l’informazione all’interno
dell’immagine
dell’immagineininmodo
modo
sequenziale semplicemente
sequenziale semplicemente
indicando
indicandolelecoordinate
coordinate(x,y)
(x,y)
dei
deipixel.
pixel.Rappresentazione discreta 3D
z Un modello poligonale o una range image è una rappresentazione
discreta di una scena reale.
z La discretizzazione dipende dal numero di punti (o poligoni)
utilizzati.
IIpoligoni
poligoniininun
un
modello
modello3D3Dnon
nonsono
sono
spazialmente
spazialmente
equodistribuiti
equodistribuiti
Non
Nonèèpossibile
possibileleggere
leggere
l’informazione all’interno
l’informazione all’interno
dell’modello
dell’modello3D3Dininmodo
modo
sequenziale.
sequenziale.Mesh Poligonale:
rappresentazione semplice
typedef struct
{
float x,y,z;
} vertice; // VERTICE
vertice ArrayVertici[n]; // array dei vertici
typedef struct
{
int v1,v2,v3;
} triangolo; // TRIANGOLO
triangolo ArrayTriangoli[m]; // array dei triangoli
v1 v2 v3 v4 v5 … Array dei vertici
t1 t2 t3 t4 t5 … Array dei triangoliMesh poligonale:
Rappresentazione con le adiacenze
typedef struct
{
float x,y,z;
} vertice; // VERTICE
vertice ArrayVertici[n]; // array dei vertici
typedef struct {
int v1,v2,v3;
int adj1, adj2, adj3;
} triangolo; // TRIANGOLO
triangolo ArrayTriangoli[m]; // array dei triangoli
v1 v2 v3 v4 v5 … Array dei vertici
t1 t2 t3 t4 t5 … Array dei triangoli
AdiacenzeConvertire una range image in una mesh
z Una Range Image è una immagine bidimensionale che contiene
informazioni tridimensionali.
z Ogni pixel rappresenta un punto dello spazio il cui colore
rappresenta la profondità del punto dalla sorgente (scanner). Lo
spazio colore può essere a toni di grigio o RGB (Red, Green, Blue)
Y
Z
XConvertire una range image in una mesh
z La generazione della mesh 3D avviene in due fasi:
1. Generazione della nuvola di vertici (x,y,z) dove le coordinate
x e y sono equidistanti mentre la z varia a seconda del colore
del pixel (z rappresenta la profondità)
2. Algoritmo di triangolarizzazione della nuvola dei punti (una
mesh di triangoli adiacenti)
Pixels X
Y
Y
X
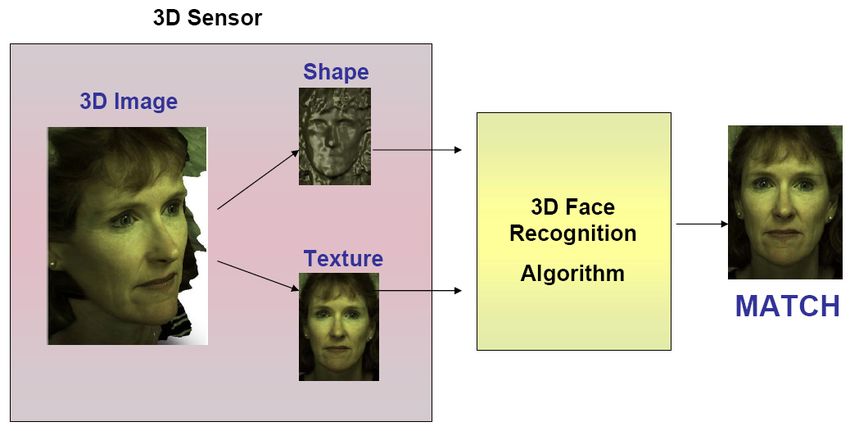
ZArchitettura di un sistema di riconoscimento facciale 3D
Il processo di riconoscimento a tre
dimensioni
Acquisizione Pre-processing Estrazione Feature Classificazione
Design a
Normalize Extract the
Capture face classifier, train
images/models features from
images/models it with dataset,
into the same normalized face
and test its
position images/models
validity1a FASE: Acquisizione
Camere stereoscopiche Acquisiscono un volto per mezzo di una coppia di camere stereoscopiche. La superficie 3D risultante viene generata a partire dalla coppia di immagini. z Sono sensibili alle variazioni d’illuminazione. z Costo Hardware: basso. z Qualità d’acquisizione: media. z Tempo d’acquisizione: Real-Time.
Camere stereoscopiche
Nasce dallo studio effettuato dai ricercatori che si occupano di
Computer Vision per simulare il modo in cui il cervello umano
percepisce “visivamente” un oggetto tridimensionale.
Algoritmo:
1. Trovare le feaures in una delle due immagini
2. Cercare le stesse features nell’altra immagine
3. Calcolare la corrispondenza tra la coppia di features per trovare la
coordinata z.
left image
Oggetto reale Modello 3D
Y
X
Z
right imageScanner a luce strutturata Gli scanner a luce strutturata tipicamente proiettano un pattern luminoso sul volto. La sorgente luminosa è solitamente una luce alogena ordinaria, quindi non causa problemi alla retina degli occhi. z Sensibili a variazioni d’illuminazione estreme. z Costo Hardware: Medio-Elevato z Qualità d’Acquisizione: Media- Elevato z Tempo d’acquisizione: 3-8 secondi.
Scanner a luce strutturata
Il patter luminoso è distorto a causa della superficie del volto.
Differenti pattern luminosi possono essere utilizzati (griglie, linee,
cerchi, sinusoidi, ecc.).
Gli scanner a luce strutturata catturano una superficie completa da un
particolare punto di vista. I dati proveniente da punti di vista multipli
possono essere combinati per creare un modello 3D completo della
testa.
Scanner
(x,y)
CameraInspeck: 3D Capturor
Passi per la generazione di un modello 3D con il 3D Capturor:
z Acquisizione: foto 2D (per texture) e fringe image (per modello 3D)
z Preprocess: pre-range image (a toni di grigio)
z Process: range image (a colori)
z Postprocess: 3D model e texture
Foto 2D Fringe ImageInspeck: 3D Capturor Preprocessed Image Processed Image 3D model 3D model con texture
Scanner laser Gli scanner laser proiettano un singolo fascio laser sul volto. L’algoritmo di generazione del modello 3D è simile a quello utilizzato dagli scanner a luce strutturata. La sorgente laser è invasiva e pericolosa alla retina degli occhi. z Non sono sensibili alle variazioni d’illuminazione. z Costo Hardware: Medio-Elevato z Qualità d’Acquisizione: Elevato z Tempo d’acquisizione: 6-30 secondi.
Morphable Models
Algoritmo
z Un sistema di acquisizione 1. Acquisire due o tre immagini fotografiche
atipico è quello basato su una del volto (frontale, laterale, diagonale)
tecnica tradizionale di computer 2. Modificare la forma ed i colori di un modello
grafica, il morphing.
generico di volto (morphable model) in
accordo al contenuto delle immagini.
z Il morphing è una tecnica di 3. Generare la texture combinando le due o tre
computer grafica in cui un immagini.
modello 3D di partenza viene
modificato e adattato in un altro
modello 3D finale.
z I morphable model sono
rappresentazioni dinamiche
della superficie del volto. Oltre
alle informazioni sulla geometria
contengono informazioni sulla
struttura dinamica (ad esempio
muscolatura facciale)Un altro esempio atipico: Morphing da una singola immagine.
Sistemi d’acquisizione basati su
morphable model
I sistemi basati su morphable model
utilizzano le immagini fotografiche
per generare modelli del volto
tridimensionali.
I morphable model danno il vantaggio
aggiuntivo di rappresentare anche
una struttura dinamica della
superficie del volto:
{ Generazione sintetica di
espressioni facciali:
z Sono sensibili alle variazioni
d’illuminazione.
z Costo Hardware: Basso
z Qualità d’Acquisizione: Medio
z Tempo d’acquisizione: > 1 Minuto.2a FASE: Pre-processing
z I sistemi di scanning tridimensionale sono sensibili ad
errori di acquisizione:
{ Noise removal: spikes (filters), clutter (manually), noise
(median filter)
{ Holes filling (Gaussian smoothing, linear interpolation,
symmetrical interpolation)Semplificazione (sub-sampling) z Le mesh poligonali, se molto accurate, possano essere computazionalmente troppo onerose da gestire. z E quindi importante poterle semplificare, se necessario. z Di solito si applica algoritmo incrementale che rimuove un vertice alla volta e ripara il buco lasciato. z Idealmente vogliamo rimuovere il maggior numero possibile di vertici per cui la risultante maglia semplificata sia una buona approssimazione della mesh originale.
Smoothing
z Lo smoothing è l’operazione di
levigare gli angoli tra i poligoni
in modo da creare una
superficie più liscia.
z Algoritmo generale:
{ Calcolare la curvatura locale α
tra un insieme di vertici vicini.
{ Se α contiene un punto p di
massimo o di minimo più
grande di un threshold t
“smussare” la superficie
sostituendo p con il valore
medio dei punti adiacenti.Allineamento
ALLINEAMENTO CON I PUNTI DI
REPERE
1) Localizzare un numero finito di
punti caratteristici di un volto
(angolo degli occhi, punta del
naso, centro della bocca, ecc.)
2) Allineare (rotazione,
traslazione, scala) i volti
riducendo la distanza tra punti
corrispondenti al minimo.
I punti possono essere
localizzati sulle immagini 2D
oppure direttamente sul
modello 3D acquisito.Iterative Closest Point (ICP)
L’algoritmo ICP (Iterative Closest Point) è
basato sul calcolo del “volume
differenza” tra due superfici 3D.
Algoritmo
Prese due superfici 3D:
1. Trovare una corrispondenza tra le due
superfici (mapping di punti, superfici,
linee, curve)
2. Calcolare la distanza tra le due
superfici con il metodo dei minimi
quadrati
3. Calcolare la trasformazione che
minimizza questa distanza
4. Effettuare la trasformazione e reiterare
la procedura finché la distanza non sia
minore di un threshold.Iterative Closest Point (ICP)
VANTAGGI:
- è un metodo molto preciso
SVANTAGGI:
- non converge sempre verso la
soluzione migliore
- è lento (>1 minuto)3a FASE: Estrazione delle features
Enhanced Gaussian Image
z Alcune metodologie di
estrazione ed analisi delle
features tridimensionali sono
indipendenti dall’orientamento. Sparse Line
{ Non è richiesto alcun
allineamento.
z Tradizionalmente, gli algoritmi ICP
di riconoscimento facciale 3D
operano sull’analisi della
curvatura locale e globale del
modello del volto.
{ Proprietà intrinseca nella
rappresentazione
PCA
tridimensionale del volto.
Shape Index
Mean
GaussianAnalisi della curvatura
(a) Crest lines (b) local curvature (c) local features
z È possibile estrarre l’informazione riguardo alla forma di un volto 3D
analizzando la curvatura locale della superficie.
z Esempi:
{ Crest Lines: si selezionano le zone a maggior curvatura
{ Local Curvature: si rappresenta la curvatura locale con un colore
{ Local Features: si segmenta il volto in zone di interesse3D FACE RECOGNITION WITH NORMAL MAPS a) Acquisizione e generazione del volto. b) Proiezione della geometria da uno spazio 3D ad uno spazio 2D. c) Generazione della normal map.
3D FACE RECOGNITION WITH NORMAL MAPS
z Le componenti delle normali
(versori) vengono campionate
con una tripla RGB
(Red/Green/Blue).
z La lunghezza del versore è
(nx ny nz)
rappresentata con l’intensità (r, g, b)
del colore (se nx è un versore
molto lungo allora il pixel avrà Y
un’intensità di rosso molto
alta)
Z
ny nz
X
nx3D FACE RECOGNITION WITH NORMAL MAPS z L’informazione sulla curvatura di una modello è rappresentata dall’insieme delle normali della superficie. z La lettura di un’immagine 2D è notevolmente più veloce della lettura di un modello 3D. z La curvatura di una modello è rappresentata dall’insieme delle normali della superficie. z Utilizzando le normal map otteniamo una rappresentazione bidimensionale di informazione tridimensionale.
3D FACE RECOGNITION WITH NORMAL MAPS z La difference map è l’immagine differenza tra due normal map. z Ogni pixel della difference map rappresenta la distanza angolare tra due normal map.
3D FACE RECOGNITION CON LE INVARIANTI GEOMETRICHE z La forma canonica serve per ottenere una rappresentazione isometrica (tutti i punti sono alla stessa distanza) DEF: una geodetica su una superficie è una linea che realizza, fra due punti, il tragitto (sulla superficie) più breve. z Questa rappresentazione è meno sensibile alle variazioni espressive perché “la geodedica tra due punti su di una superficie rimane invariata se cambiamo la curvatura della superficie stessa”
3D FACE RECOGNITION CON LE INVARIANTI GEOMETRICHE
I. Acquisizione della superficie facciale con la texture
II. Preprocessing della mesh 3D
III. Calcolo delle distanze geodetiche
IV. Trasformazione della mesh 3D nella forma canonica
V. Riconoscimento per mezzo del confronto tra i gradienti della superficie in
forma canonicaICP come algoritmo di riconoscimento facciale
4a FASE: Classificazione e Verifica
z Le metodologie di classificazione hanno l’obiettivo di memorizzare,
organizzare ed indicizzare i modelli 3D in un database.
z Le metodologie sono le stesse applicate al 2D face recognition ma
adattate al caso 3D (PCA, non-linear PCA, Fisher mapping, ecc)
z La verifica di identità si ottiene misurando la distanza (euclidea, di
Manhattan, di Chebychev, ecc.) tra coppie di features facciali e
fissando un threshold.
z Sia r1 e r2 due record da confrontare, sia d la distanza e t il valore di
threshold allora:
{ Se d > t allora r1 e r2 non appartengono allo stesso individuo (riconoscimento
FALLITO)
{ Se d < t allora r1 e r2 appartengono allo stesso individuo (riconoscimento
CORRETTO)Sistemi multimodali: volto 2D+3D
z In questa metodologia di riconoscimento vengono incluse tutte
quelle tecniche che usano contemporaneamente dati 2D (immagini
fotografiche) e dati 3D (superficie facciale)
z In genere, le immagini fotografiche 2D vengono trasformate in una
texture che poi viene applicata direttamente sulla superficie 3D
z È stato dimostrato che l’uso contemporaneo di dati 2D e 3D migliora
le capacità di riconoscimento
3D 3D+2D Texture2D+3D: Risultati sperimentali
FACE RECOGNITION %
2D+3D: 91.6%
Solo 3D: 83.7%
Solo 2D: 78.9%
Soggetti riconosciuti
con i dati 3D Insieme degli
individui
Soggetti riconosciuti
con i dati 2D
2D + 3D = 2D U 3DFacegen Modeller z Facegen Modeller è uno strumento commerciale in grado di generare il modello 3D del volto di un individuo contenente una struttura sottostante capace di simulare la “dinamicità” del volto. z L’algoritmo è basato sul l’adattamento di un modello “generico” (morphable-model) alla forma e colore del modello finale del soggetto da acquisire. z L’adattamento del morphable model al modello finale è guidato da un insieme features facciali estratte direttamente dalle foto
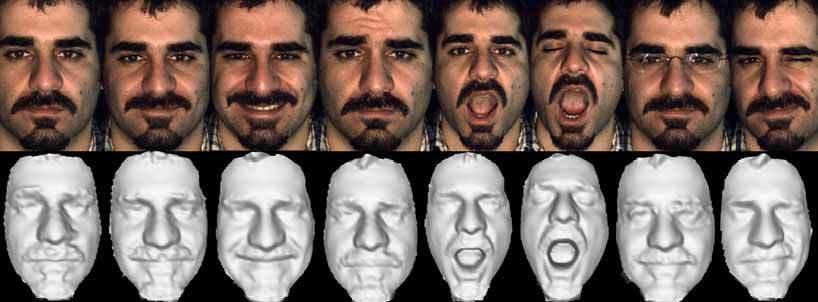
Facegen Modeller: Generare le espressioni facciali z I morphable-models sono uno strumento molto potente e permettono di generare delle espressioni facciali sintetiche z Le espressioni facciali sintetiche possono essere utilizzate per “prevenire” le espressioni facciali reali che un individuo può avere durante il processo di acquisizione
Facegen Modeller: Variare l’età
20 anni 40 anni 60 anni
• Utilizzando il morphable-model è anche possibile
ipotizzare il rilassamento della pelle dovuto all’etàFace Recognition Grand Challenge
z Il Face Recognition Grand Challenge
(FRGC) è stato pensato per ottenere
un incremento nelle performance degli
algoritmi di riconoscimento 2D e 3D.
z È una “sfida” tra gli algoritmi presentati
da diversi gruppi di ricercatori
z Per facilitare lo sviluppo di nuovi
algoritmi, è stato fornito ai ricercatori
{ un insieme di dati consistente di oltre
50.000 records divisi in due partizioni:
Training Set e Validation Set.
{ un insieme di procedure di testing in
modo da rendere comparabili i risultati
degli algoritmi di riconoscimento
faccialeFace Recognition Vendor Test
z Il progetto il Face Recognition Vendor Test (FRVT) si occupa
{ di testare lo stato dell’arte dei sistemi biometrici,
{ di capire quali sono le problematiche risolte e quelle non risolte,
{ di indirizzare i ricercatori verso soluzioni
z È un modo per analizzare lo stato dell’arte e per intuire quali potrebbero essere gli
sviluppi futuri.
z FRVT viene indetto periodicamente, a cavallo tra due FRGC, e si occupa di valutare i
progessi conseguiti nei vari challenges (FRGC) che vengono programmati.FRGC: Dataset
FRGC: Esperimenti noti
z Exp 1: HI-RES Controlled indoor still versus indoor still. Confronto tra una
immagine ad alta risoluzione e immagini singole acquisite in condizioni di luce
controllata (indoor).
z Exp 2: Indoor multi-still versus indoor multi-still. In questo esperimento la
biometria è analizzata utilizzando una sequenza di immagini ad alta risoluzione (4
immagini acquisite in condizione di luce controllata in una sequenza temporale
breve).
z Exp 3: 3D versus 3D. Confronto utilizzando i modelli 3D del volto con texture.
{ 3t, texture channel only. Confronto utilizzando solo la texture map.
{ 3s, shape channel only. Confronto utilizzando solo il modello 3D senza texture.
z Exp 4: Controlled indoor still versus uncontrolled. Confronto tra immagini 2D
acquisite in condizione di luce controllata e immagini 2D acquisite in condizione di
luce non controllata.
z Exp 5: 3D versus Controlled single still. Confronto tra modelli 3D e immagini 2D
acquisite in condizione di luce controllata.
z Exp 6: 3D versus Uncontrolled single still. Confronto tra modelli 3D e immagini 2D
acquisite in condizione di luce non controllata.FRGC: Esperimenti noti
multi 2D vs multi 2D 3D Shape+Texture
3D Texture Only
Hi-Res 2D vs 2D
3D Shape Only
Controlled
indoor still
versus
uncontrolled
Reference:
Jonathon Phillips,
FRGC Workshop,
CVPR’05 # algoritmi testatiFRGC: Esperimenti noti
FRGC: Discussione sui risultati
z Conjecture I (Bowyer’s): The shape channel of one 3D image is
more powerful for face recognition than one 2D image.
{ Criterion I-A: Performance on Experiment 3 (shape only) will be better
than experiment 3 (texture only).
z Conjecture II (Phillips’): One high resolution 2D image is more
powerful for face recognition than one 3D image.
z Conjecture IV: The most promising aspect of 3D is addressing the
case where the known images of a person are 3D biometric samples
and the samples to be recognized are uncontrolled stills.
z Conjecture V: Solution to the FRGC will cause rethinking of how
face recognition is deployed.CONCLUSIONI VANTAGGI z Il 3D Face Recognition ha il potenziale di migliorare i limiti di riconoscimento dei “tradizionali” sistemi bidimensionali z I metodi 2D, basati su immagini fotografiche, sono molto suscettibili alle variazioni di illuminazione. z Il problema dell’orientamento del volto può essere compensato con rotazioni e traslazioni della superficie facciale 3D. z Con il 3D Face Recognition le occlusioni facciali, le variazioni espressive e di età possono essere facilmente risolte. SVANTAGGI z In genere, i sistemi di acquisizione 3D sono costosi e molto lenti. z Non esiste un standard di acquisizione 3D (come per le immagini fotografiche 2D) SVILUPPI FUTURI z È facile prevedere che il boom dei sistemi di riconoscimento facciale 3D avverrà solo quando i tradizionali dispositivi foto/video verranno sostituiti da dispositivi portatili 3D in grado di acquisire e visualizzare scene in tre dimensioni
Puoi anche leggere