Un tool per il tracing di codice Java basato su Aspect Oriented Programming
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Scuola Politecnica e delle Scienze di Base Corso di Laurea in Ingegneria Informatica Elaborato finale in Programmazione II Un tool per il tracing di codice Java basato su Aspect Oriented Programming Anno Accademico 2016/2017 Candidato: Saverio Milo matr. N46002459
Tesi triennale
Indice
Introduzione 3
1 Paronamica degli argomenti trattati 5
1.1 Logging . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.2 Rule-based Logging . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.3 AOP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.4 AspectJ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.5 Sommario . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2 Descrizione della tecnica implementata 12
3 Scenari d'uso 16
3.1 Descrizione programma test . . . . . . . . . . . . . . . . . . . . . 16
3.2 Esecuzione Nominale . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.3 Interruzione Servizio (SER) . . . . . . . . . . . . . . . . . . . . . 18
3.4 CMP e gestione eccezioni . . . . . . . . . . . . . . . . . . . . . . 20
3.4.1 Caso 1: gestione all'interno del metodo . . . . . . . . . . 20
3.4.2 Caso 2: gestione nel caso in cui l'eccezione venga rilanciata 20
4 Conclusioni 22
Milo SaverioTesi triennale
Introduzione
Durante l'attività di sviluppo di un prodotto software, aspetto cruciale da te-
nere in considerare è la sua a
dabilità, difatti esistono servizi i quali devono
essere disponibili continuativamente, come programmi utilizzati ad esempio :
per la gestione di transizioni
nanziare, monitoraggio delle prestazioni di un
veicolo (stato dei freni, funzionamento delle luci etc.), veicolare il tra
co aereo.
Tale problematica è sentita sopratutto dai software legati ad attività critiche
e per tali infrastrutture il presentarsi di malfunzionamenti, possono provocare
danni all'ambiente o a persone, difatti vengono adottate dierenti tecniche per
incrementare il loro grado di a
dabilità, ricordiamo: la replicazione dello strato
hardware, rendendo così le decisioni maggiormente robuste a possibili guasti in
uno degli apparati su cui il sistema esegue, essendo la decisione presa solo se
la maggioranza delle infrastrutture è concorde; far realizzare parti del codice
che adempiono allo stesso scopo da dierenti team ed eseguirle su diversi strati
replicati, riducendo la possibilità di introdurre nel codice errori comuni. Sudette
tecniche vengono adottate per limitare il propagarsi di errori, i quali possono
evolvere in fallimenti dell'intero sistema provocati da difetti nel codice introdotti
durante le vari fasi del suo sviluppo.
Sono state realizzate dierenti tecniche atte a registrare gli eventi salienti del-
l'esecuzione di un'applicazione software, riuscendo a determinare in tempo reale
l'andamento del
usso di esecuzione per avere dati riguardanti: le risorse uti-
lizzate, i tempi d'esecuzione di speci
ci eventi, informazioni relative alla reale
messa in opera del software; tali metodologie hanno successo quando il rapporto
generato è accurato, permettendo la rilevazione dei problemi di cui il software
è a itto.
Una delle principali tecniche adottate è generare eventi di log. Sono informa-
zioni raccolte in precisi punti del codice atte a descriverne il suo andamento,
succesivamente salvate in una struttura logica di tipo
le, oppure inviate su rete
per poter poi essere analizzate.
I risultati riscontrati da un approc- f
cio al logging non ben strutturato
portano ad avere informazioni non
sempre accurate, difatti i fallimen-
ti catturati dalle attività di log-
ging sono solo una parte di quelli
che avvengono e non sempre quel-
li registrati sono veritieri, derivan-
ti dalla rilevazione di errori che in
realtà, sono gestiti o comunque non
discriminano un fallimento, riscon-
Figura 1: Propagazione errori
trando risultati non soddisfacenti,
sopratutto per prodotti in cui la rilevazione dei fault debba essere un'attività
primaria.
Milo SaverioTesi triennale
A
nché l'attività di rilevazione dei fallimenti possa essere e
ciente, non può
essere rimandata durante la stesura del codice e le istruzioni che riguardano la
cattura delle informazioni per il logging, devono essere separate dal resto del
codice dell'applicativo essendo dei servizi che il softwate non implementa ma ne
usufruisce.
Un metodologia che migliora l'attività di tracing, risolvendo il primo problema
citato sopra, è adottato dal rule-based logging, fornendo una tecnica di cattu-
ra delle informazioni maggiormente a
dabile e precisa. Di suddetto approccio
ne esiste una versione scritta in C, utilizzata dal framework LogBus, il quale
la sfrutta per la rilevazione dei fallimenti. Il framework discrimina diverse ti-
pologie di errori che portano il software a comportarsi in modo non previsto,
introducendo opportune chiamate di funzione atte alla registrazione di eventi.
LogBus non separa i diversi aspetti del codice, difatti l'immissione delle chia-
mate alla scrittura degli eventi di log nei vari
le che verranno eseguiti, avviene
tramite un opportuno code parser a cui una volta datogli in pasto: il sorgente
di cui si vogliono analizzare i fallimenti; le entità che fanno parte del sistema e
dove si trova la loro de
nizione, riesce ad inserire automaticamente le opportune
chiamate di funzione che occorrono per la registrazione degli eventi di logging,
rendendo il codice meno comprensibile e aumentando lo sforzo per una sua fu-
tura modi
ca.
L'AOP è un approccio realizzato per separare i diversi interessi all'interno di un
codice, problematica che a igge approcci alla programmazione in cui il software
viene rappresentato come un insieme di funzionalità (procedurale) o composizio-
ne di entità (oggetti), con l'utilizzo degli aspetti invece, si riesce a determinare
porzioni del
usso di esecuzione e aggiungere funzionalità in modo trasparente
al codice che realizza la nostra business logic. L'approccio legato agli aspetti
purtroppo, non è maturato come quello ad oggetti, per tale ragione viene af-
ancato all'OOP, cosicché sia possibile utilizzare le peculiarità migliori dei due
per la stesura della piattaforma software.
Scopo di quest'elaborato è quello di testare la possibilità di realizzare un tool
per la rilevazione dei fallimenti in Java, il quale possa essere utilizzato indie-
rentemente dal prodotto che si vuole andare a produrre e abbia la capacità di
separare la rilevazione dei eventi di logging dalla business logic.
L'elaborato sarà organizzato in tre sezioni: una prima, in cui verrà discusso del
logging e degli approcci sviluppati successivamente in tale elaborato; verranno
poi forniti i dettagli con i quali si è realizzato il tool ed in
ne un insieme di
esempi pratici, per testare le capacità dello strumento realizzato.
Milo SaverioTesi triennale
1 Paronamica degli argomenti trattati
1.1 Logging
Il logging é una delle tecniche maggiormente diuse per la raccolta di informa-
zioni durante l'esecuzione delle varie funzionalità di un sistema, utilizzata anche
per la rilevazione dei fallimenti. In quest'ultimo caso sudetta metodologia viene
impiegata per scoprire dinamicamente i fault introdotti durante la fase di pro-
duzione che successivamente evolvono in fallimenti, rendendo l'attività di debug
più immediata rispetto ad analizzare staticamente il codice per determinare di-
fetti in esso. Difatti essendo un'attività esegutita quando il software non è in
esecuzione, molti dei fault non vengono rilevati, poiché alcuni sono scatenati
soltanto con l'interazione di più attività che il software ore o in determinati
situazioni di carico del sistema. La tecnica essenzialmente si basa sulla produ-
zione di log entry, informazioni che descrivono un evento che è avvenuto durante
il funzionamento del software, successivamente i dati vengono salvati in un
le
di testo ed analizzando quest'ultimo si dovrebbe identi
care quale parte del co-
dice abbia scatenato il fallimento.
L'approccio al logging non è un attività ben de
nita, non esistono metodolo-
gie speci
che a supporto di tale attività, per suddetto motivo le informazioni
rilevate dal log potrebbero essere inaccurate e imprecise. Un difetto potrebbe
provocare la scrittura di più eventi nel
le, includendo a priori un'operazione
di
ltraggio delle informazioni registrate prima del loro reale utilizzo, a
nché
sia possibile discriminare la causa del fallimento del sistema software. Esistono
alcuni framework a supporto di tali attività tra cui log4x di Apache che cercano
di uniformare la creazione degli eventi di log, supportando inoltre le operazioni
di
ltraggio dei dati.
I framework forniscono solo delle API utili alla gestione degli eventi. Il posi-
zionamento dei punti in cui viene eettuato il logging viene lasciato nelle mani
degli sviluppatori rimandando l'attività di gestione dei fallimenti alla fase di
codi
ca, quindi il modo in cui questi punti vengono attivati mutua da team a
team di sviluppatori anche se principalmente i pattern per la cattura di eventi
sono tre:
• try{} catch(){write_log}
la funzione di logging è avviata alla cattura di un'eccezione;
• if(cond) write_log
di solito if contiene singole condizioni logiche legate insieme da operatori
logici che non vengono modi
cati se il codice esegue correttamente;
• else write_log
la scrittura su log avviene nel ramo else di un costrutto if;
Milo SaverioTesi triennale
Listing 1: Esempio di cattura degli eventi di log con l'utilizzo di try catch() in
wild
y
1 @Override
2 protected Context getDefaultInitCtx() throws NamingException {
3 if (!gotDefault) {
4 // if there is an initial context factory prop in the
,→ env use it to create the default ctx
5 final String factoryClassName = myProps != null ?
,→ (String)
,→ myProps.get(Context.INITIAL_CONTEXT_FACTORY) :
,→ null;
6 if(factoryClassName == null ||
,→ InitialContextFactory.class.getName()
,→ .equals(factoryClassName)) {
7 defaultInitCtx = new
,→ DefaultInitialContext(myProps);
8 } else {
9 final ClassLoader classLoader =
,→ WildFlySecurityManager.
,→ getCurrentContextClassLoaderPrivileged();
10 try {
11 final Class factoryClass =
,→ Class.forName(factoryClassName, true,
,→ classLoader);
12 defaultInitCtx =
,→ ((javax.naming.spi.InitialContextFactory)
,→ factoryClass.newInstance())
,→ .getInitialContext(myProps);
13 } catch (NamingException e) {
14 throw e;
15 } catch (Exception e) {
16 throw
,→ NamingLogger.ROOT_LOGGER.failedToInstantiate(e,
,→ "InitialContextFactory",
,→ factoryClassName, classLoader);
17 }
18 }
19 gotDefault = true;
20 }
21 return defaultInitCtx;
22 }
questi approcci non intercettano la causa del fallimento
ntantoché non viene
sollecitata la parte del codice istruita a farlo, se fosse presente ad esempio un
loop in
nito in un blocco di istruzioni, il
usso di esecuzione stagna in un punto
preciso non permettendo la rilevazione di tale loop di esecuzione, difatti la mag-
gior parte dei fallimenti rilevati non è dovuta a difetti del software, ma fallimenti
provocati da risorse limitate che vengono utilizzate per l'esecuzione dello stesso
o comunque dall'ambiente in cui viene avviato.
Milo SaverioTesi triennale
Per suddetti motivi esistono altri metodi per il rilevamento dei fallimenti ad
esempio heartbeat message e in alcuni casi, si aiuta l'attività di monitoraggio
con il supporto hardware (watchdog).
Tutti gli approcci però lasciano libero il programmatore nel decidere dove at-
tivare le procedure di logging, quindi la qualità della rilevazione dei fallimenti
dipende dall'esperienza di quest'ultimo, se consideriamo che un prodotto è rea-
lizzato da diversi team, ognuno di loro potrebbe avere un approccio dierente.
Il rule-based logging vuole disiplinare l'attività della cattura dei fallimenti: indi-
viduare prima della stesura del codice quali sono i punti salienti dell'esecuzione,
categorizzare i vari tipi di errori che possono essere rilevati, esonerando così il
programmatore e poter rendere tale attività automatizzata.
1.2 Rule-based Logging
Questa metodologia, con l'ausilio della modellazione UML, riesce ad individuare
quali saranno le posizioni in cui dovrà essere eettuato l'inserimento dei punti
di avvio delle procedure di log già durante la progettazione. Difatti con una
rappresentazione del sistema in termini delle entità che lo costituiscono e delle
loro interazioni, è possibile discriminare quali sono le interazioni o le operazioni
che possono generare fallimenti nel software, determinando inoltre una proce-
dura ben de
nita per la rilevazione.
Lo scopo è quindi quello di creare una tecnica generalizzata, essendo l'attività
di modellazione una buona prassi per la creazione di un software e quindi in-
clusa nella maggior parte dei prodotti di qualità, estendendo la possibilità di
riusarla per progetti completamente diversi invece di dover trovare approcci ad-
hoc, molto spesso non e
caci o che comunque richiedono uno sforzo di sviluppo
elevato.
Il punto chiave di questa metodologia è quello di basarsi su un modello speci
co
per la rilevazione degli errori e l'utilizzo di regole ben de
nite, che stabiliscono:
dove eettuare l'operazione di generazione di eventi di log (quelli che devono
scatenare la procedure atte alla loro gestione) e cosa deve essere tracciato, sal-
vato (il tipo di evento che l'ha suscitato). Per la brevità dell'elaborato saranno
rilevati solo i seguenti eventi:
• Service STart(SST): evento da loggare al primo ingresso nella funzionalità,
prima ancora dell'avvio di quest'ultima, mette in evidenza che quel servizio
è stato avviato correttamente;
• Service ENd(SEN): deve essere loggato prima di ogni terminazione del
servizio valida, evidenza che il software si è comportato nel modo voluto;
Questi eventi permettono di determinare la durata prevista di un servizio: ogni
volta che una coppia di eventi SST e SEN per un servizio sono rilevati, vie-
ne salvata la durata dell'esecuzione di quel servizio ed utilizzata per calcola-
re ∆n , la durata della ennesiama esecuzione stimata a partire dalla formula
∆n = (1 − α) ∗ ∆n−1 + α ∗ ∆l dove ∆l de
nisce la durata dell'ultima esecuzione
riscontrata. Il parametro da tenere in considerazione è α perché all'aumentare
di questo si dà maggiore peso all'ultima esecuzione corretta, invece della storia
delle esecuzioni, facendo oscillare la durata prevista del servizio.
Milo SaverioTesi triennale
Gli errori de
niti dalla metodologia sono i seguenti:
• Service error (SER): I service error non permettono ad una frazione di
codice che è in esecuzione, di raggiungere un exit point (escludendo la sua
normale terminazione);
• Service complaint (CMP): noti
ca che un servizio è terminato per mezzo
di un dirty exit point, cioé un punto di terminazione dell'attività non
voluto;
• Interaction error (IER): tale tipologia di errore noti
ca che vi è stata
un'invocazione di un metodo da un'entità è il controllo non ritorna a
questa;
• Crash error (CER): un servizio è terminato inaspettatamente;
In tale elaborato verrano trattate solo le prime due tipologie di errore.
Gli eventi citati sopra, uniti ad un approccio regolato da timeout, permettono la
rilevazione del SER. Un SER error viene generato solo quando non è riscontrato
l'evento SEN associato ad esso dopo un tempo pari ns ∗ ∆n (dove ns è un valore
maggiore di 1), da quando si è registrato un SST, segnalando che il servizio
non riesce a terminare. Un CMP error viene registrato ogni qual volta un
metodo rilancia l'eccezione ad un altro o in caso di una runtime exception,
poiché il
usso di esecuzione termina prima del punto di ritorno che stabilisce
la corretta esecuzione del metodo, nel caso in cui la gestione dell'eccezione di
questo avvenga all'interno dello stesso, viene considerato un'esecuzione corretta
del codice e per tale ragione non viene generato un errore di tipo CMP. La
rilevazione di tale evento comporta l'esclusione del SEN.
La realizzazione della metodologia indicata sopra verrà implementata sfruttando
il paradigma legato agli aspetti, utilizzato per separare la logica del prodotto
da realizzare, dai servizi di cui usufruisce.
Milo SaverioTesi triennale
1.3 AOP
L'approccio allo sviluppo software più utilizzato ad oggi è quello legato alla pro-
grammazione ad oggetti, ormai aermatosi anche nell'ambito industriale.
Questo paradigma di programmazione è comunque non perfetto ed aetto da
diversi problemi, uno tra questi legato alla realizzazione di servizi orizzontali
(servizi che occorrono all'applicativo per funzionare, ma non fanno parte del
suo reale scopo di realizzazione), utili allo sviluppo della piattaforma software,
tra cui ricordiamo: la persistenza delle informazioni prodotte, la sicurezza ed
anche le attività di logging.
Nel caso di quest'ultime, la parte di codice adibita a generare informazioni ri-
guardanti l'esecuzione di operazioni dell'entità è unita alla business logic della
stessa, andando a non rispettare uno dei principi della stesura di un buon codice,
la modularità. Questa prassi si ripresenta anche per gli altri servizi orizzontali,
provocando un degrado della qualità del codice, oltre ad una replicazione di esso
che potrebbe essere evitata, riducendo così la complessità e il tempo per il suo
sviluppo.
La programmazione legata agli aspetti è stata ideata per la separazione dei di-
versi concern all'interno di un codice introducendo appunto gli aspetti.
Secondo l'OOP la realizzazione di un software avviene componendo gli ogget-
ti, ognuno adibito ad esprimere le entità che sono essenziali alla creazione del
prodotto. Nel caso di attività comuni, vengono utilizzate le funzionalità di og-
getti che orono supporto a queste, usufruendo anche di più istanze dello stesso
oppure riscrivendo parti del codice ogni qual volta occorrono (l'approccio mag-
giormente utilizzato), gli aspetti invece riescono ad intercettare la richiesta di
servizi comuni e li servono evitando la riutilizzazione di risorse o la duplicazione
di codice, così viene evitato l'introduzione di istruzioni non inerenti alla logica
applicativa. La programmazione legata agli aspetti non è da intendersi un pa-
radigma esterno a quello della programmazione ad oggetti, invece le deve essere
da supporto per migliorare la qualità del software realizzato, difatti con il solo
utilizzo dell'AOP non è possibile realizzare un software funzionale.
Il framework utilizzato è AspectJ, che estende la sintassi del linguaggio Java,
rendendolo compatibile con il paradigma orientato agli aspetti.
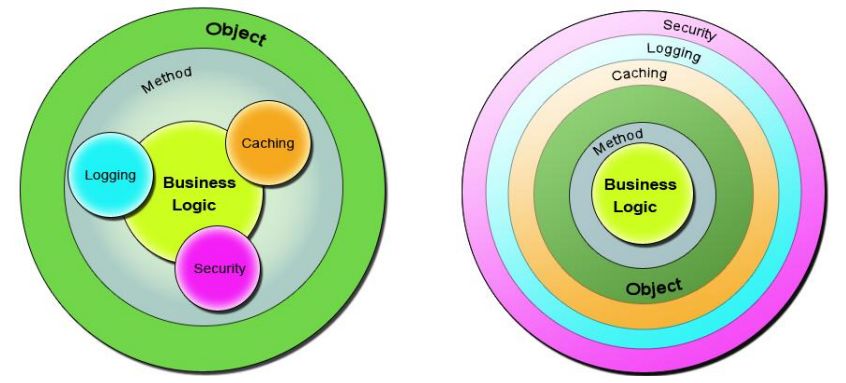
Figura 2: Dierenza tra approccio ad oggetti ed ad aspetti. Immagine tratta da:
http://kospiotr.github.io/wiki/spring-aop-presentation/
Milo SaverioTesi triennale
1.4 AspectJ
Questo framework, disponibile al download sul sito di Eclipse, basa tutto il suo
funzionamento su precisi punti chiave:
• Aspect
• Join Point
• Pointcut
• Advice
Gli Aspect permettono di de
nire dei tipi di cross-cutting, dando così la ca-
pacità allo strato software di catturare le richieste per l'utilizzo di un servizio
voluto da più oggetti, gli Aspect verranno sfruttati per de
nire un aspetto che
intercetti, punti del codice di cui si vuole fare logging.
I Join Point sono punti ben de
niti nell'esecuzione del programma, quali pos-
sono essere: la chiamata di un metodo, la sua esecuzione, la chiamata di un
costruttore etc.; permettendo di de
nire quali porzioni di codice, della business
logic, devono attivare l'esecuzione di codice orizzontale.
I Pointcut sono quella parte dell'infrastruttura che permettono la de
nizione
dei Join Point da catturare. Viene fornito anche un oggetto, thisJoinPoint il
quale unito all'utilizzo del pattern re
ection, dà la possibilità di avere infor-
mazioni riguardanti: il Join Point catturato, identi
cativo dell'oggetto, nome
della classe, metodo che ha generato l'esecuzione del Pointcut e molte altri dati
relativi al Join Point che è stato eseguito.
Gli Advice sono dei comportamenti aggiuntivi che si vogliono collocare nel nor-
male
usso di esecuzione dell'applicativo, in modo trasparente a quest'ultimo
senza appesantirlo o renderlo confuso, ne esistono di tre tipologie:
• before , prima dell'esecuzione del Join Point;
• , dopo l'esecuzione del Join Point;
after
• around , vengono eseguite al posto del Join Point;
after permette di determinare punti del codice più speci
ci da catturare, come
ad esempio: dopo il lancio di un eccezione, a
ancandoli la clausola throwing()
o appena dopo la terminazione di un metodo con returning().
Around è la clausola più potente, riesce a "wrappare" il Join Point che l'ha
scatenata, dando la possibilità di eseguire operazioni sia prima che dopo
quest'ultimo, oltre che a dierenza delle altre Advice, permette di avere un
parametro di ritorno nella sua dichiarazione e di poter modi
care il valore
dei parametri di un metodo, tramite le variabili passate come argomento al
metodo proceed(..), che riavvia l'esecuzione del
usso di istruzioni intercettato.
Milo SaverioTesi triennale
Un listato di codice che mostra un utilizzo di tali strumenti viene riportato qui
sotto:
1 aspect myAspect //definizione di una Aspect
2 {
3 pointcut myPointcut(): execution(public static void
,→ main(..)); //definizione di un pointcut
4 before(): myPointcut() //definizione di una Advice
5 {
6 System.out.println("Eseguo prima del main"); //codice da
,→ eseguire per quella particolare Advice
7 }
8 }
in questo esempio si viene a creare una Aspect, che prima di ogni esecuzione
di un metodo la cui
rma corrisponde a quella indicata come parametro di
execution, viene eseguita una stampa a video. Si può notare che la de
nizione
di quest'ultima è molto simile a quella di una classe, anche se prima di poter
eseguire questo codice si ha bisogno di un compilatore speci
co. Per Java vi è la
presenza di un altro framework che dà la possibilità di estendere il linguaggio con
il paradigma dell'AOP, Spring, il quale ha meno capacità espressive di AspectJ
nella de
nizione dei Pointcut, ma può essere eseguito senza ausilio di compilatori
non Java.
1.5 Sommario
In conclusione il software realizzato vuole essere di supporto alla rilevazione dei
fallimenti, evitando ai programmatori l'onere di introdurre nel codice istruzioni
dedicate alla rilevazione, con utilizzo del rule-based logging, separando inoltre
la business logic del prodotto da voler realizzare dalla logica del framework per
la rilevazione dei fallimenti, utilizzando la programmazione legata agli aspetti
implementata con l'ausilio del framework AspectJ nel linguaggio Java.
Milo SaverioTesi triennale
2 Descrizione della tecnica implementata
A
nché sia possibile utilizzare il framework prodotto, bisogna con
gurare
l'ambiente Eclipse come indicato:
• Avviare l'IDE, recarsi nella sezione help, Install new software;
• Aggiungere una nuova repository dove si andrà a scaricare il necessario;
cliccando sul tasto add, si aprirà una nuova
nestra, nel campo nome
inserire un nome che si ritiene idoneo, nel campo URL il seguente indirizzo:
http://download.eclipse.org/tools/ajdt/47/dev/update;
• Attendere a
nché compaiano i pacchetti che è possibile installare, bisogna
selezionarli tutti dopodiché cliccare su avanti;
• Accettare le condizioni ed attendere l'installazione;
• Per veri
care che l'operazione sia andata a buon
ne, selezionare New
project, Other e controllare se è presente una sezione denominata AspectJ;
• Nel progetto includere il package contenete il codice attuo al tracing e
precedere ad ogni metodo la annotation @Log,a
nché ne venga fatta una
tracciatura;
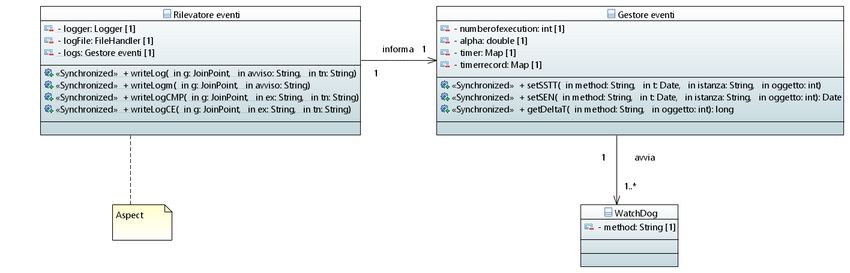
Figura 3: Class diagram delle principali classi che realizzano il framework
Il package che va incluso per eettuare la tracciatura, è stato realizzato in
linguaggio Java, con l'ausilio di AspectJ e delle annotation. Nell'infrastruttura
è presente una aspect che viene attivata per ogni funzionalità di cui si vuole
eettuare il logging essendo questa preceduta da @Log, dando la possibilità
di testare solo le funzionalità di cui si è realmente interessati, rendendo la
generazione del log consona all'esecuzione del codice che ci interessa tracciare,
altrimenti si verebbe a generare un
le di log con molte entry rendendolo di
di
cile lettura. Le annotation inoltre sono state introdotte per un successiva
gestione delle varie operazioni di rilevamento da parte di un container.
Milo SaverioTesi triennale
Il software durante la sua esecuzione, non appena giunge ad un punto di interesse
per il logging, il suo
usso di esecuzione viene indirizzato alla sezione di codice
che si occupa del tracing e rilevamento errori, principalmente le diverse sezioni
in cui l'esecuzione può essere spostata sono composte: da una sezione atta alla
scrittura delle informazioni sul
le di log ed un'altra invece esegue le attività
utili per la rilevazione di errori.
Tutte le entry hanno questa sezione di informazioni di utilità in comune:
timestamp - [tipo del messaggio] - tipo di evento loggato
i seguenti Pointcut, de
niscono quali metodi il framework riesce a gestire:
pointcut main(): execution(public static void main(..));
pointcut run() : execution(public void run(..));
pointcut allMethod():execution(* *(..));
• main, cattura l'esecuzione del punto di lancio dell'intero software, gli even-
ti di SST e di SEN per tale metodo vengono solo tracciati, senza tener
conto dei parametri per la rilevazione dei SER, essendo eseguito una sola
volta;
• run, i thread vengono gestiti dierentemente dagli altri metodi, le
informazioni che occorrono per la loro tracciatura sono diverse;
• allMethod, qualsiasi altro metodo avviato viene gestito da questo Pointcut;
Le informazioni relative ai metodi eseguiti che occorrono al framework per rile-
vare le varie tipologie d'errore, vengono salvate in due HashMap: una di queste
(timerrecord nel class diagram) occorre per conoscere i riferimenti temporali dei
vari metodi e parametri relativi al funzionamento del framework, difatti è stato
realizzato un oggetto RecordTime in cui vengono memorizzati le informazioni
relative: al tempo di inizio del metodo, la sua durata stimata, quante volte è
stato eseguito; invece l'altra Map (timer) contiene i TimerTask utilizzati per
la rilevazione dei SER, questi iniziano ad essere eseguiti solo dopo un numero
adeguato di SST e SEN, difatti questi eventi scatenano il salvataggio di in-
formazioni nella prima HashMap riguardanti il metodo eseguito, quando i dati
raccolti sono su
cienti a determinare il tempo di esecuzione del servizio, viene
istanziato un TimerTask e salvato nella seconda Map, esso in realtà è un nuo-
vo thread a cui è associato un timer, che viene eseguito solo dopo che è stato
trascorso un tempo pari ns ∗ ∆n e noti
ca l'avvenimento del SER, altrimen-
ti all'arrivo del SEN il TimerTask viene eliminato e questa esecuzione viene
considerata corretta.
Identi
cativo metodo in esecuzione RecordTime
SSTt durata istanza(ms) numero di esecuzioni terminate
AspectJT.run()0Thread-1 31/07/2017 11:59:49.503 220 2
ClasseEsempio.m1(..)648303415Thread-5 31/07/2017 11:59:50.046 107 6
Tabella 1: Esempio hashtable timerrecord
Milo SaverioTesi triennale
before(): allMethod() && @annotation(provaAspectJ.Log) &&
,→ !main() && !run()
{
Loggable.writeLog(thisJoinPoint,
,→ "SST",Thread.currentThread().getName());
}
Rileva l'evento SST di tutti i metodi diversi da main e run, viene lanciata la
funzionalità di writeLog, la quale avvia la memorizzazione delle informazioni re-
lative al Pointcut, che vengono fornite dall'oggetto thisJoinPoint, un esempio
di evento registrato ha la seguente forma:
metodo che ha generato l'evento, ID dell'oggetto, nome del
,→ thread che lo ha eseguito
I thread a dierenza di un normale metodo gli viene assegnato ID oggetto 0,
perché per ogni thread viene creato un oggetto diverso quindi un ID dierente,
procurando una entry diversa nel
le di log, quando in realtà viene avviato un
thread che ha lo stesso comportamento di quello precedente.
after() : allMethod() && @annotation(provaAspectJ.Log) &&
,→ !main() && !run() &&
,→ if(!nex.contains(thisJoinPoint.getSignature()
,→ .toShortString()+thisJoinPoint
,→ .getThis().toString()+Thread.currentThread().getName()))
{
Loggable.writeLog(thisJoinPoint,
,→ "SEN",Thread.currentThread().getName());
}
Frazione del codice per la rilevazione dei SEN, non viene avviata se nella strut-
tura dati nex è presente una funzionalità che ha generato un errore di tipo
CMP, altrimenti verrebbe generato un evento che segnala la corretta termina-
zione del metodo compromettendo il signi
cato della traccia, essendo lanciato
in luogo ad una terminazione non ordinaria della funzionalità.
metodo che ha generato l'evento, ID dell'oggetto, nome del
,→ thread che lo ha eseguito, durata dell'esecuzione
Alla entry relativa ad un SEN viene inclusa anche la durata dell'esecuzione di
quella istanza, usata per discriminare casi di falsi positivi oppure generazioni di
errori causate da una durata maggiore dell'esecuzione della funzionalità ma che
in realtà non é fallita.
Milo SaverioTesi triennale
after() throwing(Exception e) : allMethod() &&
,→ @annotation(provaAspectJ.Log)
{
nex.add(thisJoinPoint.getSignature().
,→ toShortString()+thisJoinPoint
,→ .getThis().toString());
Loggable.writeLogCMP(thisJoinPoint,e.toString(),
,→ Thread.currentThread().getName());
}
Gli eventi che generano CMP vengono salvati nella struttura nex per evitare
l'avvio di un evento SEN .
metodo che ha lanciato l'eccezione, l'eccezione lanciata
La piattaforma ha anche la capacità di rilevare la cattura e la gestione di una
eccezione all'interno di un metodo della business logic:
before(): he()
{
String e=CatchClauseSignature.class.cast
,→ (thisJoinPoint.getSignature()).toLongString();
Loggable.writeLogCE(thisJoinPoint,e,Thread.
,→ currentThread().getName());
}
metodo che ha lanciato l'eccezione, l'eccezione catturata
un futuro utilizzo, potrebbe essere quello di invalidare il tempo di esecuzio-
ne dell'istanza di quel metodo oppure, iniziare a tener traccia di quest'ultimo
considerando la gestione dell'eccezione.
Milo SaverioTesi triennale
3 Scenari d'uso
Per testare il funzionamento del framework sviluppato, verrà utilizzato un esem-
pio di riferimento scritto in Java, in cui verranno introdotti dei fault in posizio-
ni speci
che del
usso di esecuzione, a
nché si possa determinare l'a
dabilità
dello strumento.
3.1 Descrizione programma test
Nell'esempio utilizzato vengono avviate le seguenti attività : il main esegue
10 thread del tipo AspectjT che a loro volta richiamano di un oggetto c1, il
metodo m1. Lo stesso thread ne crea altri 10 del tipo AspectjT1 che eseguono
il metodo m1 dell'oggetto c2, i due oggetti sono istanziati nel main e passati ai
thread tramite costruttori.
La scelta di creare due istanze della stessa classe, serve a dimostrare che il
framework riesce ad identi
care l'esecuzione dello stesso metodo da parte di
oggetti diversi, invece quella di generare più
ussi di esecuzione mette in luce
la sua capacità di operare anche in ambiente multithreading. Questa facoltà di
discernere due diverse istanze dello stesso oggetto o diversi
ussi di esecuzione,
rende più chiara quale parte del software ha subito un fallimento, difatti se si
avesse solo il nome del thread, si riuscirebbe a capire quale
usso si è interrotto
ma non per colpa di quale oggetto ciò è avvenuto, nel caso contrario invece
avere solo l'ID dell'oggetto fa comprendere quale istanza di questo ha causato
un
usso di esecuzione non voluto, ma non quale sia il
usso, nel caso in cui ne
siano presenti altri che vengano eseguiti concorrentemente, per tale ragione le
informazioni vengono salvate entrambe.
3.2 Esecuzione Nominale
Viene mostrato in prima istanza dei gra
ci che descrivono la normale esecuzione
del codice in cui successivamente introdurremo dei fault, utili per confrontarli
poi con quelli che provengono da una esecuzione non corretta, sulle ordinate
è rappresentato il tempo di esecuzione per quel metodo salvato sul log, invece
sulle ascisse il numero dell'esecuzione in ordine di inizio attività:
Milo SaverioTesi triennale
metodo: AspectJT.run() (ms)
200
100
0
1 2 3 4 5 6 7 8 9 10
ID esecuzione
metodo: c1.m1 (ms)
200
100
0
1 2 3 4 5 6 7 8 9 10
ID esecuzione
metodo: AspectJT1.run() (ms)
200
100
0
1 2 3 4 5 6 7 8 9 10
ID esecuzione
metodo: c2.m1 (ms)
200
100
0
1 2 3 4 5 6 7 8 9 10
ID esecuzione
Milo SaverioTesi triennale
3.3 Interruzione Servizio (SER)
Verrano introdotti fault per simulare delle situazioni di fallimento, mettendo in
evidenza le reali capacità del framework.
Provocheremo prima un errore di tipo SER. Verrà allungata l'esecuzione dei
vari servizi con l'introduzione di chiamate al metodo sleep in punti precisi del
codice, ciò serve a simulare il blocco di un'attività software per un malfunzio-
namento anche se in realtà non accadrà.
Negli esempi sottostanti verrà prolungata di due secondi l'esecuzione della
settima istanza del thread AspectJT.run() e di cinquecento millisecondi
l'esecuzione dell'ottava chiamata del metodo m1 dell'oggetto c2. Il valore
ns utilizzato è pari a tre, per la determinazione del tempo di timeout che il
software gestisce.
Analizzando i gra
ci sottostanti, l'esecuzione della settima istanza del thread
AspectJT.run() e del metodo m1 di c2 sono aumentate ed il framework ha
segnalato la durata anomala dei servizi, lanciando un errore di tipo SER
(situato al di sotto dei rispettivi gra
ci). La durata del thread AspectJT1
risulta anche essa maggiore, osserviamo che il nome del thread è lo stesso che
avvia il metodo m1, quindi il
usso deve attendere la
ne del metodo prima di
poter terminare.
La bontà del framework è veri
cata, essendo riuscito a rilevare tempi di
esecuzione più lunghi, per tale ragione sicuramente riuscirà a determinare
bloccaggi nel codice. Il sorgente del framework e dell'esempio vengono avviati
nella stessa JVM, per avere risultati migliori il framework dovrebbe essere
eseguito da una JVM diversa o addirittura eseguito su una macchina diversa,
infatti in un reale utilizzo, avviare i codici nello stesso ambiente diminuisce la
capacità del framework nella rilevazione dei fallimenti, perché in casi in cui ad
esempio durante la mancanza della fornitura elettrica per il sistema, ma non
nella sala dove è presente l'elaboratore su cui sta avvenendo la raccolta dati,
questo evento non verrebbe rilevato.
31/07/2017 11:59:50.903 - [INFO] - SST ClasseEsempio.m1(..)
,→ 517415723 Thread-33
31/07/2017 11:59:50.932 - [INFO] - SST WatchDog.run() 0 Timer-8
31/07/2017 11:59:50.933 - [WARNING] - SER AspectJEsameT.run()
,→ Thread-21 0
31/07/2017 11:59:50.934 - [INFO] - SEN WatchDog.run() 0 Timer-8 2
31/07/2017 11:59:51.015 - [INFO] - SEN ClasseEsempio.m1(..)
,→ 517415723 Thread-33 113
31/07/2017 11:59:51.015 - [INFO] - SEN AspectJEsameT1.run() 0
,→ Thread-33 215
31/07/2017 11:59:52.572 - [INFO] - SST ClasseEsempio.m1(..)
,→ 648303415 Thread-21
31/07/2017 11:59:52.685 - [INFO] - SEN ClasseEsempio.m1(..)
,→ 648303415 Thread-21 113
Figura 4: Esempio rilevazione SER
Milo SaverioTesi triennale
metodo: AspectJT.run() (ms)
2,000
1,500
1,000
500
0
1 2 3 4 5 6 7 8 9 10
ID esecuzione
SER AspectJT.run() Thread-23 0
metodo: c1.m1 (ms)
200
100
0
1 2 3 4 5 6 7 8 9 10
ID esecuzione
metodo: AspectJT1.run() (ms)
600
400
200
0
1 2 3 4 5 6 7 8 9 10
ID esecuzione
SER AspectJT1.run() Thread-27 0
metodo: c2.m1 (ms)
400
200
0
1 2 3 4 5 6 7 8 9 10
ID esecuzione
SER ClasseEsempio.m1(..) Thread-27 1616246432
Milo SaverioTesi triennale
3.4 CMP e gestione eccezioni
Per generare entry di tale tipo sono state create tre classi:
• CheckedException, lancia un'eccezione catturata all'interno del suo corpo;
• ThrowsCheckedException, rilancia un'eccezione all'oggetto che avvia il
metodo di questa classe;
• UncheckedException, genera una NullPointerException ;
tali classi servono a simulare la terminazione di un'attività per mezzo di exit
point non voluti, in Java a dierenza di altri linguaggi di programmazione le
eccezioni sono divise in categorie ben dierenziate tra loro, in base al tipo e al
loro modo di essere gestite, questi esempi sono esaustivi per qualsiasi generazione
di eccezione possa avvenire, tutti i metodi m1 dei vari oggetti sono eseguiti nel
main.
I comportamenti addottatti dal framework sono 2, in base a se l'eccezione è
gestita nel metodo oppure venga rilanciata.
3.4.1 Caso 1: gestione all'interno del metodo
13/07/2017 01:31:06.990 - [INFO] -
,→ SSTmainprovaAspectJ.AspectJEsame
13/07/2017 01:31:07.025 - [INFO] - SST CheckedException.m1()
,→ 1828972342 main
13/07/2017 01:31:07.029 - [INFO] - gestione eccezione
,→ provaAspectJ.CheckedException catch(java.io.IOException)
13/07/2017 01:31:07.032 - [INFO] - SEN CheckedException.m1()
,→ 1828972342 main 19
13/07/2017 01:31:07.055 - [INFO] - SENmain
All'avvio del metodo m1, viene lanciata un eccezione di tipo IOException
tramite la clausola throw, come vediamo essa è gestita ed il metodo termina
naturalmente, perché questa non determina la
ne del metodo essendo cattu-
rata, ma solo di un
usso operativo diverso.
3.4.2 Caso 2: gestione nel caso in cui l'eccezione venga rilanciata
13/07/2017 01:32:34.368 - [INFO] -
,→ SSTmainprovaAspectJ.AspectJEsame
13/07/2017 01:32:34.385 - [INFO] - SST
,→ ThrowsCheckedException.m1(..) 931919113 main
13/07/2017 01:32:34.387 - [WARNING] - CMP
,→ provaAspectJ.ThrowsCheckedException@378bf509
,→ java.io.IOException
13/07/2017 01:32:34.388 - [INFO] - gestione eccezione
,→ provaAspectJ.AspectJEsame catch(java.io.IOException)
13/07/2017 01:32:34.391 - [INFO] - SENmain
Milo SaverioTesi triennale
Questa volta l'IOException viene rilanciata al metodo chiamante, che si pre-
occupa di catturare l'eccezione, invece il metodo chiamato data la sua
ne di
esecuzione non ordinaria genera un errore CMP, qui il metodo che lancia l'ec-
cezione termina perché ha raggiunto un punto di esecuzione che non è capace
di gestire, terminando prima del suo punto di ritorno ordinario.
13/07/2017 01:28:33.971 - [INFO] -
,→ SSTmainprovaAspectJ.AspectJEsame
13/07/2017 01:28:34.003 - [INFO] - SST UncheckedException.m1()
,→ 1828972342 main
13/07/2017 01:28:34.006 - [WARNING] - CMP
,→ provaAspectJ.UncheckedException@6d03e736
,→ java.lang.NullPointerException
13/07/2017 01:28:34.007 - [INFO] - SENmain
La generazione della eccezione unchecked è stata eettuata creando un ogget-
to a cui poi è stato assegnato al suo riferimento il valore null, richiamando
succcessivamente l'avvio di un metodo usando quel riferimento, generando così
un NullPointerException. In questo caso nessun metodo cattura e gestisce
l'eccezione non essendo a carico del programmatore, si è in grado comunque di
rilevarla.
Milo SaverioTesi triennale
4 Conclusioni
La programmazione legata agli aspetti è sicuramente un approccio alla scrittura
di codice orizzontale più elegante e funzionalmente più e
cace di quello ad og-
getti, purtroppo però questa
loso
a di programmazione non è ben supportata,
infatti non esistono strumenti potenti per l'ingegnerizzazione del software, se si
pensa che l'approccio ad oggetti viene utilizzato sin dall'attività di analisi del
prodotto software da realizzare. Legando però l'AOP ad un approccio sistema-
tico come il rule-based logging può portare a risultati soddisfacenti, ovviamente
qui non si è riusciti a descrivere l'intera potenzialità di questo stile, difatti due
tipologie di errore ad esempio, non sono state analizzate, però riscontrando la
semplicità con cui sia possibile analizzare del codice in esecuzione, rende l'AOP
uno strumento estremamente potente per la realizzazione di framework orizzon-
tali che aiutino lo sviluppo di un prodotto software. Un futuro test potrebbe
essere eettuato su un progetto open source come ActiveMQ, rilevando come
si comporta il software in casi più complessi di quelli simulati in questo elabo-
rato, sfruttando ad esempio bug noti della piattaforma ed osservando se questi
vengano rilevati.
Milo SaverioBibliografia
[1] Kiczales, G.; Lamping, J.; Mendhekar, A.; Maeda, C.; Lopes, C.; Loingtier, J. M.;
Irwin, J. Aspect-oriented programming. ECOOP’97. Proceedings of the 11th European
C onference on Object-Oriented
[2] Cinque M.; Cotroneo D.; Pecchia A.; Event Logs for the Analysis of
Software Failures: A Rule-Based Approach.IEEE transactions on software
engineering, vol. 39, no. 6, June 2013
[3] The Eclipse Foundation. "The AspectJ TM Programming Guide".
http://www.eclipse.org/aspectj//doc/next/progguide/index.html. 30/08/2017
[4] Antonio Pecchia; Marcello Cinque; Gabriella Carrozza; Domenico Cotroneo.
Industry Practices and Event Logging: Assessment of a Critical Software Development
Process; ICSE 2015. International Conference on Software Engineering
[5] The Apache Software Foundation. "Apache Log4j 2 ™". https://logging.apache.org/log4j/2.x/.
30/08/2017Puoi anche leggere

















































