RIPASSO III E DISTRIBUZIONI DI PROBABILITÀ - METODI QUANTITATIVI PER LA RICERCA 2020/21 AGNESE VITALI - DIDATTICA ONLINE
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Ripasso III e distribuzioni di probabilità Metodi Quantitativi per la Ricerca 2020/21 Agnese Vitali
Argomenti trattati • Ripasso: Metodi di analisi descrittiva: − Descrivere la variabilità dei dati (seconda parte) • La Distribuzione di Probabilità Normale • Lo z score
Ripasso di alcune misure di statistica descrittiva Misure di variabilità • Campo di variazione (range) • Deviazione standard • Scarto interquartile 3
Deviazione standard (campionaria) • La standard deviation (s) misura l’ammontare medio della deviazione dalla media da parte di una osservazione campionaria Deviazioni di ciascuna s = (x i − x) 2 osservazione xi dalla media ҧ n −1 • Il quadrato della deviazione standard è chiamato varianza 4
Proprietà della deviazione standard • s≥0 • Se s è grande, la variabilità intorno alla media sarà grande. • Se s è piccolo, le osservazioni sono concentrate intorno alla media. • s = 0 solo quando tutte le osservazioni hanno lo stesso valore. • E’ uno stimatore della standard deviation della variabile misurata sulla popolazione, espresso con . 5
Quartili e altri percentili • Il p-esimo percentile è il valore nella distribuzione al di sotto del quale ricade il p% delle osservazioni e al di sopra del quale ricade il (100 - p)% delle osservazioni. • Abbiamo già incontrato un percentile, quale? • La mediana, 50mo percentile
Quartili e altri percentili ✓ I quartili vengono definiti attraverso il 25-esimo e il 75-esimo percentile. ✓ Insieme alla mediana, i quartili dividono la distribuzione in quattro parti ciascuna delle quali contiene un quarto delle osservazioni. © 2009 Pearson Paravia Bruno Mondadori S.p.A.
Box Plot: rappresentazione grafica di cinque misure di posizione ✓ La differenza fra il primo e il terzo quartile è chiamata scarto interquartile e viene indicata con IQR (Inter Quartile Range). ✓ La mediana, i quartili, il massimo e il minimo sono cinque misure di posizione spesso impiegate congiuntamente per descrivere la centralità e la variabilità di una distribuzione. ✓ Con un software statistico è stato ottenuto il seguente report riferito alla distribuzione dei tassi di criminalità USA: 100% Max 79.0 75% Q3 51.0 50% Med 36.5 25% Q1 27.0 0% Min 8.0 ✓ I cinque numeri forniscono una semplice descrizione dei dati e li chiameremo sintesi-a- cinque-numeri. © 2009 Pearson Paravia Bruno Mondadori S.p.A. 8
✓ Essi sono anche gli elementi base di una rappresentazione grafica chiamata box plot. ✓ Il box (scatola) contiene il 50% centrale della distribuzione, dal primo al terzo quartile. ✓ La mediana è rappresentata da una linea che attraversa il box. ✓ Le linee che si estendono a partire dalla scatola sono chiamate whiskers e vanno fino al massimo e fino al minimo a meno che nella distribuzione siano presenti osservazioni outlier. © 2009 Pearson Paravia Bruno Mondadori S.p.A. 9
Boxplots • Utili per mostrare la distribuzione di varibili continue – in particolare per confrontare due o più gruppi Source: Hill, H and Choi, Y (2006) Neonatal mortality in the developing world. Demographic Research, 14(18)
Outlier ✓ I box plot sono degli strumenti efficaci anche per identificare le osservazioni outlier. ✓ Definizione di outlier (valore anomalo): Un'osservazione viene definita outlier se ricade a più di 1.5(IQR) al di sopra del terzo quartile oppure a più di 1.5(IQR) al di sotto del primo quartile. ✓Se nella distribuzione non sono presenti outlier, i whisker del box plot si estendono fino alle osservazioni massima e minima. ✓ Se ci sono outlier, i whisker si estendono fino all'osservazione che è compresa entro 1.5(IQR) oltre i quartili; gli outlier sono indicati separatamente nel grafico. © 2009 Pearson Paravia Bruno Mondadori S.p.A. 11
• Distribuzioni di Probabilità
Probabilità come lunga serie di frequenze relative ✓ Per un campione casuale, la probabilità di un’osservazione è la proporzione di volte in cui essa dovrebbe verificarsi in una lunghissima sequenza di osservazioni ✓ E’ la frequenza relativa (proporzione) che indica quanto frequente è quella particolare osservazione rispetto a tutte le altre. © 2009 Pearson Paravia Bruno Mondadori S.p.A. 14
Distribuzioni di probabilità per variabili discrete ✓ L'insieme di tutti i possibili valori di una variabile e le corrispondenti probabilità definiscono la distribuzione di probabilità. ✓ Se la variabile è discreta, ciascun valore y ha una probabilità P(y) di verificarsi, per cui: 1. 0 P(y) 1; 2. tuttiy P(y) = 1. ✓ Ad es., si consideri il lancio di un dado i cui valori che è possibile osservare sono gli interi da 1 a 6. 1 ✓ Ciascun valore y =1,2,3,4,5,6 ha la stessa probabilità di verificarsi P(y) = 6 © 2009 Pearson Paravia Bruno Mondadori S.p.A. 15
✓ Consideriamo la seguente distribuzione di probabilità riferita alla variabile numero ideale di figli: ✓ Graficamente: © 2009 Pearson Paravia Bruno Mondadori S.p.A. 16
Distribuzioni di probabilità per variabili continue ✓ Le variabili continue assumono infiniti valori nell'intervallo considerato ✓ In pratica, tra due valori, anche molto vicino tra loro, vi sono infiniti altri valori. ✓ Le distribuzioni di probabilità di variabili continue, quindi, assegnano probabilità a intervalli di numeri. ✓ La rappresentazione grafica sarà, quindi, una curva. © 2009 Pearson Paravia Bruno Mondadori S.p.A. 17
Distribuzioni di probabilità per variabili continue • L’area sottesa alla curva è pari a 1. • La proporzione dell’area sotto la curva compresa tra due punti può essere calcolata e sarà un numero compreso tra 0 e 1 • La proporzione dell’area sotto la curva compresa tra due punti = probabilità che un'osservazione ricada tra quei due valori
✓ Calcoliamo la P(y > 45), cioè la probabilità di impiegare più di 45 minuti per raggiungere il posto di lavoro. ✓ Il grafico evidenzia la porzione di area corrispondente alla probabilità cercata. © 2009 Pearson Paravia Bruno Mondadori S.p.A. 19
La Distribuzione di probabilità Normale • Forma a campana, distribuzione tipica di molte variabili continue Simmetrica rispetto alla media
• Estremamente importante in statistica. Perchè? • In parte perchè molte varibili continue hanno una distribuzione di frequenze che ha una forma approssimativamente normale, ad es: peso, altezza, indice di massa corporea • Inoltre per via del Teorema del Limite Centrale (TLC) – vedi poi
Propertietà della Distribuzione Normale • Tanti tipi di distribuzioni Normali – ognuna definita da due parametri: la media () e la standard deviation () • Stessa forma a campana – ma alcune sono alte e strette (piccola ), alter corte e grasse (grande ) • La simmetria implica che metà dell’area sottesa alla curva normale cade sopra la media, e l’altra metà cade sotto la media (e che media = mediana)
• L’area totale sottesa alla curva è pari a 1. • La proporzione dell’area sotto la curva compresa tra due punti può essere calcolata e sarà un numero compreso tra 0 e 1 • La proporzione dell’area sotto la curva compresa tra due punti = probabilità che un'osservazione ricada tra quei due valori • La probabilità che un'osservazione ricada all'interno di un intervallo definito dalla media più o meno un certo numero di deviazioni standard è la stessa per tutte le distribuzioni normali
Area sotto la curva Normale 95.4% 68.2% 68.2% delle osservazioni cade a distanza di una SD dalla media (sia adestra che a sinistra) 95.4% cade a due SD dalla media 2.3% 2.3% la quasi totalità (99.7%) cade a tre SD dalla media
Esercizio: Quale % dell’area cade tra la media e 2 SD alla destra della media? 2.3% 2.3%
Esercizio: Quale % dell’area cade tra la media e 2 SD alla destra della media? 13.6+34.1 = 47.7% (Oppure 95.4 / 2) 2.3% 2.3%
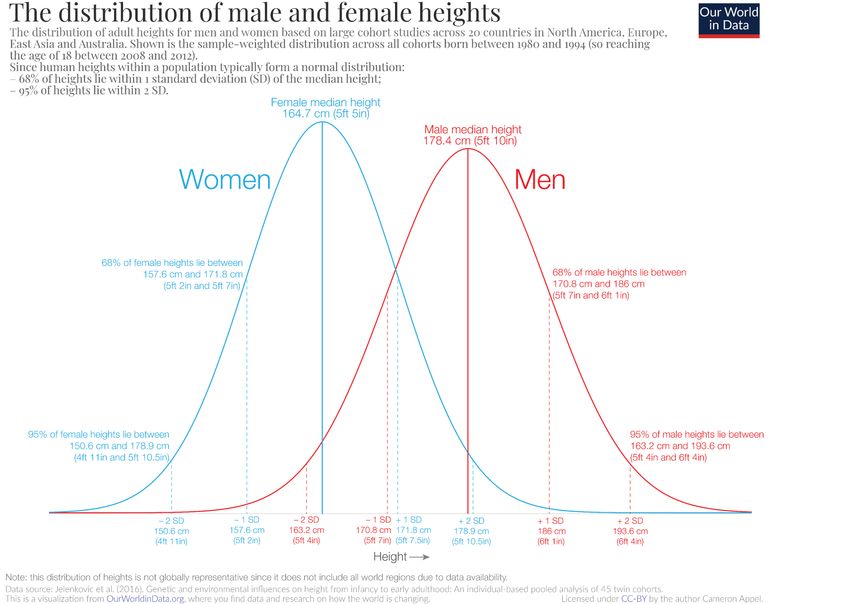
Distribuzione dell’altezza per uomini e donne • Per gli uomini: μ=178.4 cm e σ=7.59 cm • Per le donne: μ=164.7 cm e σ=7.07 cm https://ourworldindata.org/human-height
• Poiché l’altezza ha una distribuzione Normale, possiamo calcolare il range in cui cade l’altezza del 68% degli uomini e delle donne • Ricorda: Il 68% delle osservazioni ricade tra μ+σ e μ- σ • Per gli uomini: • μ + σ =178.4 + 7.59 = 170.81 • μ - σ = 178.4 - 7.59 = 185.99 • Range (approssimando): (171; 186)
Esempio: Tempo di attesa per trovare il primo lavoro a tempo indeterminato dopo la laurea • Il tempo di attesa medio per trovare lavoro dopo la laurea è di 18 mesi con una SD di 7 mesi. • I dati sono normalmente distribuiti. • Qual’è la probabilità che si debba aspettare almeno 32 mesi?
• 32 è 2 SD sopra la media (32 – 18 = 14 = 2 x 7; o 18+7+7) • Quindi la probabilità di aspettare almeno 32 mesi per il primo lavoro a t.i. dopo la laurea è pari a 2.3% 2.3% 2.3%
• Qual’è la probabilità che si debba aspettare almeno 23 mesi? • 23 non è multiplo di 7, che facciamo? • Prima di procedere…
Standardizzare i dati • Possiamo standardizzare i dati calcolando lo z-score. Per un’osservazione x lo z-score è x − media z = SD • Nota: Per costruzione, la media dello z-score è 0 e la deviazione standard è 1
• lo z-score ci dice a quante deviazioni standard x − media di distanza dalla media cade un’osservazione z = SD • Per esempio, uno z-score di +1 indicata che l’osservazione cade a una SD dalla media • Nell’esempio preceente: • Il tempo di attesa medio per trovare lavoro dopo la laurea è di 18 mesi con una SD di 7 mesi. 32 − 18 • I dati sono normalmente distribuiti. z = 7 = 2 • Qual’è la probabilità che si debba aspettare almeno 32 mesi per trovare lavoro dopo la laurea?
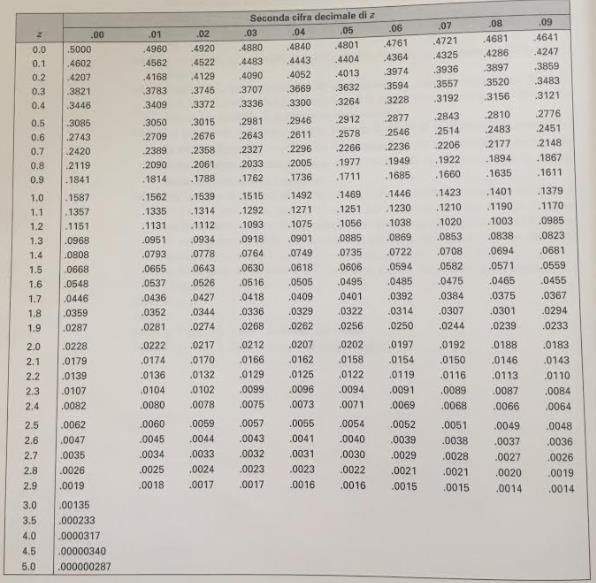
• Perchè standardizzare? • Se i dati sono normalmente distribuiti, lo z-score ha una Distribuzione Normale Standard con media =0 e SD=1 • Importante perchè: ➢ la Distribuzione Normale Standard è tabulata.
Cf Appendice Tavola A libro Tavola della Normale Standard I valori in tabella ci dicono qual’è l’area a destra di un punto che si trova z deviazioni standard sopra la media
Torniamo all’esempio… • Qual’è la probabilità che si debba aspettare almeno 23 mesi per trovare lavoro dopo la laurea? Normal distribution curve Quest’area probabilities rappresenta la probabilità che cerchiamo 18 23
Step 1: Calcola lo z-score corrispondente a 23: 23 − 18 z = 7 = 0.71 Step 2: Dalla tavola della distribuzione Normale standard: Proporzione > 0.71 = 0.2389 0.24 probabilità di aspettare almeno 23 mesi.
Step 2: Dalla tavola della distribuzione Normale standard: Proporzione > 0.71 = 0.2389 0.24 probabilità di aspettare almeno 23 mesi.
Altri usi dello Z-Score • z-score può essere usato per: ➢ Confrontare dati provenienti da due diverse distribuzioni ➢Esempio: ➢voto di Marco in MQR = 25; voto di Maria in sociologia della famiglia= 26 ➢Chi ha fatto meglio all’esame rispetto al resto della classe? ➢Identificazione di outliers
Altri usi dello Z-Score • z-score può essere usato per: ➢Identificazione di outliers: Z < -2 or Z > +2 Inusuale – ma ci aspettiamo 5% del campione si comporti così Z < -3 or Z > +3 Outlier – estremo
Letture • Agresti – Finlay: − Capitolo 3, paragrafi 3.3, 3.4, 3.6 e 3.7 − Capitolo 4, paragrafo 4.1 (escluso «Leggi probabilistiche di base»), 4.2, 4.3
Puoi anche leggere

















































