UNIVERSITÀ DELGI STUDI DI MILANO
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
UNIVERSITÀ DELGI STUDI DI MILANO
FACOLTÀ DI SCIENZE E TECNOLOGIE
Corso di Laurea Triennale in Informatica
Valutazione del recommender system NETT-IRS
Relalore: Prof. Simone Bassis
Correlatore: Dott. Francesco Epifania
Tesi di Laurea di:
Hao Quan
Matricola: 774871
Anno Accademico 2013/2014
1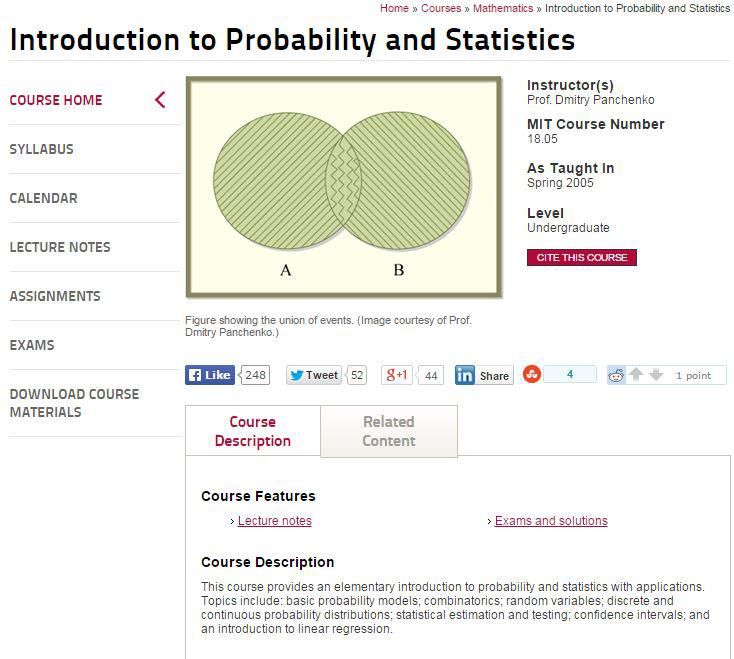
RINGRAZIAMENTI
Al termine di questa lunga e impegnativa esperienza credo sia doveroso rivolgere alcuni ringrazia-
menti alle persone che, in modo diverso, mi sono state vicine.
Innanzitutto ringrazio il Professor Simone Bassis: una guida indelebile. Oltre al suo immancabile
supporto come docente durante i miei studi, lo ricorderò anche come amico durante il mio soggiorno
in Italia. Non riesco davvero ad immaginare il raggiungimento di questo traguardo senza il suo
prezioso contributo umano e accademico.
Ringrazio il Dottor Francesco Epifania per tutto quello che mi ha insegnato e la sua disponibilità
in qualità di supervisore.
Ringrazio la mia famiglia: lontana, decisamente lontana, ma sempre con me. "L' informatica"
avvicina le persone: questo e' un merito che non le si può negare.
Ringrazio Yang Haiyan, mi ha sempre incoraggiato.
Ringrazio Marsel Caka, un amico con cui ho condiviso tante ore di studio e che ha reso più leggera
e piacevole la fatica.
Ringrazio Enzo Agoglia, un amico italiano che potrebbe diventare amico "italo-cinese" semmai un
giorno dovesse trasferirsi in Cina come desidererebbe.
Ringrazio da ultimo, ma non certo per ordine di importanza, le tante persone deliziose che ho incro-
ciato durante questo cammino indimenticabile e che non menziono perché le pagine per contenerle
sarebbero troppe.
2
Contents
1 Introduzione 5
2 Recommender System e metodologie per la loro valutazione 6
2.1 Recommender System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2 Algoritmi di Raccomandazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2.1 Sistemi Collaborativi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2.2 Sistemi Content-based . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.3 Sistemi Knowledge-based . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.4 Sistemi Ibridi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2.5 Sistemi Community-based . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2.6 Sistemi Demographic-based . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.3 Mobile Recommender System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3.1 Context-aware recommendation . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3.2 Proximate selection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3.3 Privacy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.4 Sistemi di raccomandazione ed E-learning . . . . . . . . . . . . . . . . . . . . . . . 14
2.4.1 Algoritmi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.4.2 Design del sistema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.5 Valutazione dei Recommender System . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.5.1 Qualità . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.5.2 Performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3 IRS-NETT(Interactive Recommender System di NETT) 22
3.1 Progetto Nett . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.1.1 Sondaggio sulle esigenze di formazione . . . . . . . . . . . . . . . . . . . . . 23
3.1.2 Risultati del sondaggio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.2 IRS-Nett . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.2.1 Algoritmi NETT-RS: tre fasi principali . . . . . . . . . . . . . . . . . . . . 24
3.2.2 NETT-RS: Architettura a tre livelli . . . . . . . . . . . . . . . . . . . . . . 25
3.3 Confronto tra IRS-Nett e gli altri . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3
4 Valutazione di IRS-Nett 30
4.1 Metodologia di valutazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
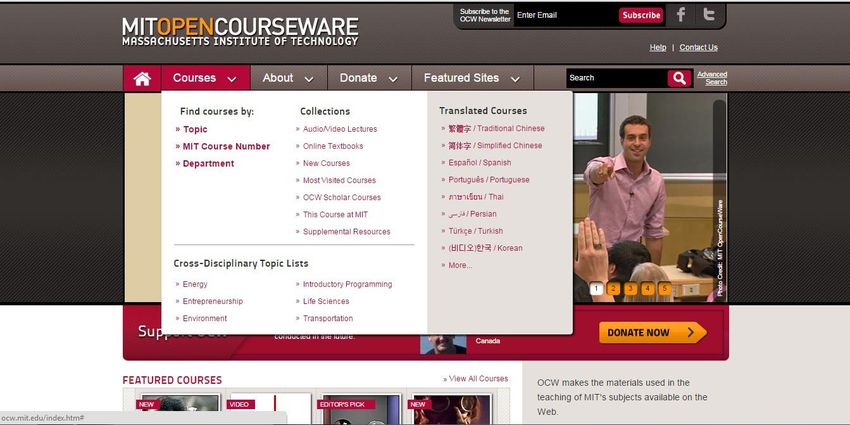
4.2 Perchè Mit OpenCourseWare . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.3 MIT OCW e il dataset di NETT . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.3.1 Crawler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.4 Valutazione NETT-IRS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.5 Questionario . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.5.1 Qualità del sistema percepita . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.5.2 Beliefs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.5.3 Behavioral Intentions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.5.4 Indirect feedback . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.5.5 Possibile domande questionario: . . . . . . . . . . . . . . . . . . . . . . . . . 40
5 Conclusione e sviluppi futuri 42
6 Bibliogra
a e Sitogra
a 43
4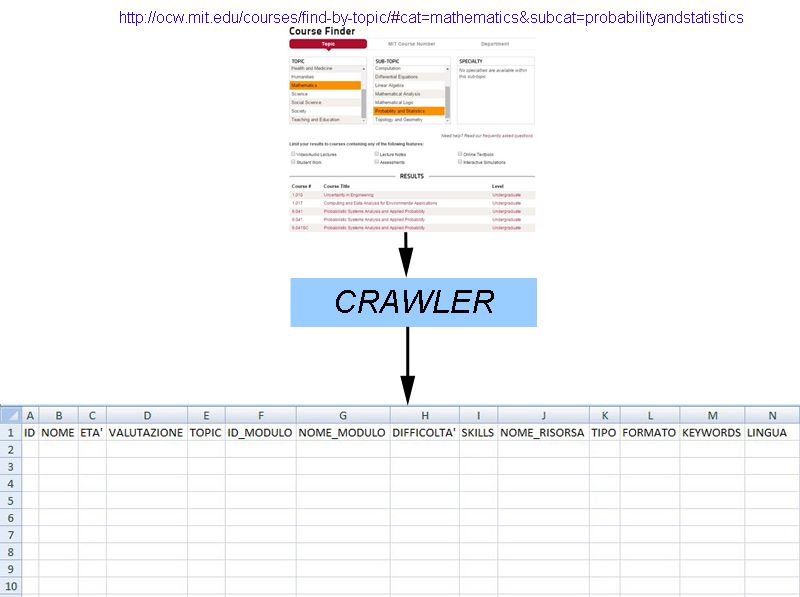
1 Introduzione
La presente Tesi di Laurea si colloca all'interno del laboratorio di WebCentrica. In questo lab-
oratorio si fanno delle valutazione, progettazione e sviluppo di sistemi interattivi multimediali e
multicanali per l'arricchimento di conoscenza, valutazione dei Sistemi di Raccomandazione. Il
laboratorio volge progetti nel settore ICT sia in ambito accademico che in ambito aziendale.
In questa tesi si è occupato dei Sistemi di Raccomandazione e la sua valutazione, sopratutto sono
stati analizzati i sistemi di raccomandazione nell'ambito e-learning. Prima di parlare dei RS in
ambito e-learning si sono analizzati diversi algoritmi di raccomandazione partendo da quelli più
classici come quelli Collaborative-based e Content-based per poi parlare dei Knowledge-based,
Community-based e Demographic-based. Poi si è analizzato anche l'algoritmo utilizzato per fare
IRS-NETT ovvero quello ibrido mischiando in questo caso i Collaborative-based e Content-based.
Abbiamo analizzato anche i Mobile Recommender System visto che siamo nel era dei smartphone
non potevamo ignorare questo fatto, anche se lo abbiamo analizzato, purtroppo questo tipo di RS
non è stato analizzato approfonditamente visto che non entrava nei limiti della tesi. Non potevamo
assolutamente lasciare fuori i sistemi di raccomandazione nell'ambito e-learning per il semplice
fatto che fa parte del core del lavoro di questa tesi.
Abbiamo fatto una valutazione generale dei recommender system dove ci siamo focalizzati di più
sui due tipi di metriche per valutarli, le misure per valutare la qualità e le misure per valutare le
performance. Le prime analizzano i suggerimenti e le seconde il RS come sistema. Sulle metriche
basate sulla qualità possiamo elencare l'accuratezza che è la metrica usata anche da IRS-NETT,
copertura che è una metrica abbastanza importante nel campo dei RS. Poi arrivano anche le altre
che non sono meno importanti come con
denza,
ducia, novelty, serendipity chè è forse la metrica
più interessante e di
cile da calcolare, diversity, utility, risk, robustezza, adaptivity e scalability.
Invece le metriche per calcolare le performance dei RS possiamo elencare il tempo di risposta del
sistema, requisiti di memoria e la complessità computazionale.
Al capitolo tre veniamo a parlare del progetto NETT che è un progetto europeo che si basa
sulla creazione di una piattaforma
nalizzata allo scambio di contenuti, esperienze, metodi tra
insegnanti di oggi e di domani responsabili dell'educazione all'imprenditorialità.Prima di iniziare
il lavoro sono stati fatti dei sondaggi per vedere al meglio le esigenze degli utenti futuri. L'idea
principale è quella di motivare l'uso di un RS in termini di riduzione della grande quantità di
risorse disponibili, risparmio di tempo nella ricerca di materiale e la possibilità concreta di creare
un corso di alto livello e ben strutturato e ben organizzato, tutto ciò in conformità con le esigenze
del docente stesso. Architettura di NETT-RS è a tre livelli :
1. User Web Interface
2. Switcher Server
3. Recommender Server
E' stato fatto anche un confronto con altri sistemi di raccomandazione ovvero con quelli ibridi
(collaborative-based e content-based).
Arrivando al capitolo quarto abbiamo analizzata la metodologia di valutazione usata per questo al-
goritmo ovvero quella sull'accuratezza e abbiamo analizzato MIT OpenCourseWare chè è il dataset
scelto per poter costruire poi il dataset che utilizzerà NETT. Il dataset di NETT sarà composto
da corsi,moduli e risorse e ognuna di loro avrà dei metadati.
5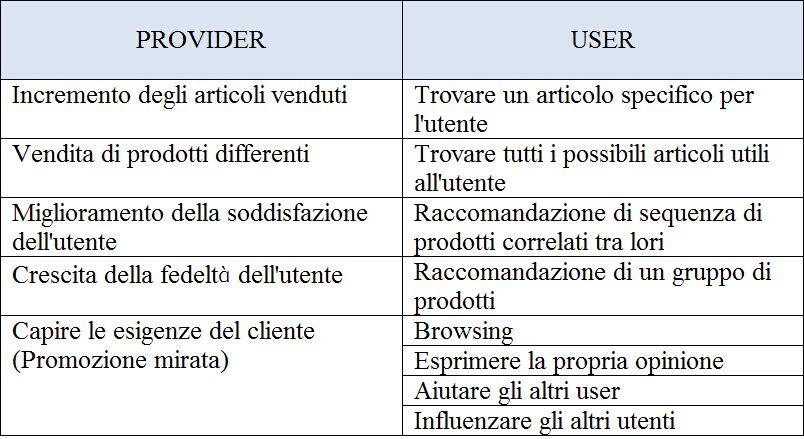
2 Recommender System e metodologie per la loro valutazione
Quello che l'informazione consuma è piuttosto ovvio: consuma l'attenzione dei suoi
destinatari. Dunque un'abbondanza di informazione crea povertà d'attenzione, ed
il bisogno di scegliere come distribuire in maniera e
ciente questa attenzione tra la
sovrabbondanza di informazioni che potrebbero consumarla
H.A. Simon
La diusione pervasiva delle tecnologie informatiche, e la crescente diusione dei contenuti digitali
orono agli utenti la possibilità di fare del media digitale uno strumento da utilizzare in ogni
contesto e in ogni occasione e, lo promuovono a dispositivo che può essere d'ausilio alla vita
dell'utilizzatore a trecentosessanta gradi. Ciò rende il problema della gestione e dell'organizzazione
di questa mole informativa una questione quantomai prioritaria, che cerca soluzioni nuove e che
facilitino l'esperienza utente. I sistemi di raccomandazione si inseriscono in questo scenario: ci
imbattiamo sempre più spesso in loro quando si ha a che fare con siti di e-commerce, nascosti da
etichette come:
Forse ti piacerebbe comprare anche..., ma è molto comune anche incontrarli in ambiente enorme-
mente diversi, nella forma di raccomandazioni musicali, cinematogra
che, di pagine web, o anche
persone. Insomma, in ogni situazione in cui possa aver valore un consiglio. Il grande merito di
questi sistemi è infatti quello di fornire a chi li utilizza uno strumento per valutare degli oggetti
prima di spendere denaro o semplicemente tempo su di essi. È da notare come in un certo senso
l'uso di questo tipo di strumento, che implicitamente modella il meccanismo naturale di consigli
tra gli uomini, porti con se una forte connotazione sociale, oltre alla più evidente valenza econom-
ica: al di là del contenuto delle raccomandazioni, il semplice fatto che siano mantenuti dati su
diversi utenti e sulle loro preferenze rende possibile la scoperta di relazioni (implicite o esplicite)
tra persone, fondate sui loro gusti comuni. Non è dunque improprio dire che ciascun sistema di
Raccomandazione costruisce o, ancor meglio, rivela una rete di legami tra persone, una rete sociale.
2.1 Recommender System
Reccommender System (RS) o Sistemi di Raccomandazione in italiano, è ogni sistema che produce
raccomandazioni individuali come output o ha l'eetto di giudare l'utente nella strada di person-
alizzazione di oggetti interessanti e utili fra una miriande di possibilità. Tra le altre utilità dei
Reccommender System possiamo elencare anche:
• Suggeriscono interazioni con nuovi item analizzando le passate interazioni.
• Arontano e
cacemente l'information overload.
• Forniscono valore aggiunto per utenti,imprese e relazioni fra loro.
I RS si occupano di fornire agli utenti consigli personalizzati e di loro probabile interesse riguardo
un set di oggetti appartenenti ad uno speci
co dominio (e.g. musica, cinema, libri), a partire dai
dati di cui dispone: informazioni su utenti e oggetti.
Nella tabella sotto vediamo alcuni delle principali funzioni che un RS può avere sia dal punto di
vista di un provider che ha dei prodotti da vendere e l'utente che va a controllare e magari anche
comprare i prodotti.
6
Una de
nizione formale del problema delle raccomandazioni può essere espressa in questi termini:
Sia C l'insieme degli m∈N utenti del sistema, ed I l'insieme degli n∈N oggetti che possono essere
raccomandati.
La cardinalità degli insiemi C ed I può essere molto alta, ed i valori m ed n possono essere dell'ordine
delle centinaia di migliaia di unità.
Si de
nisce inoltre funzione di utilità u : C×I→R. Essa misura quanto un dato oggetto i sia utile
ad un determinato utente c.
R è un insieme totalmente ordinato, ed i suoi elementi rappresentano quantitativamente l'utilità
di un'oggetto per un utente.
L'utilità di un oggetto è tipicamente rappresentata da una valutazione (es. numerica) che un utente
ha assegnato o assegnerebbe ad un oggetto. Date queste de
nizioni, si vuole scegliere per ciascun
utente c∈C, l'oggetto I'∈I che massimizza la funzione di utilità per l'utente.
Il problema centrale delle raccomandazioni sta nel fatto che la funzione u, non è de
nita su tutto
lo spazio C×I : nelle applicazioni tipiche un utente non esprime mai preferenze su ogni oggetto del
catalogo a disposizione; per esempio, in un sistema di e-commerce il voto di un utente è rappre-
sentato da un valore binario (0 se l'oggetto non è stato acquistato, viceversa 1): è quindi di
cile
assumere che un utente possa aver acquistato tutti gli oggetti in vendita; e nel caso improbabile in
cui lo avesse fatto, le raccomandazioni gli sarebbero del tutto inutili.
I Recommender Systems devono essere perciò in grado di stimare i valori della funzione di utilità
u anche nella parte dello spazio dei dati in cui non è de
nita, estrapolandoli a partire dai punti di
C×I in cui essa è nota: questo è anche il compito più problematico. In altre parole l'obiettivo è
fare una predizione sul voto che un determinato utente darebbe ad un oggetto del sistema che non
ha ancora valutato.
7
2.2 Algoritmi di Raccomandazione
Le tecniche attraverso le quali i diversi sistemi predicono voti sconosciuti a partire da quelli
conosciuti, ed il modo in cui queste predizioni sono sfruttate e rese fruibili all'utente
nale, rapp-
resentano due fondamentali aspetti alla luce dei quali caratterizzare i sistemi stessi.
Prendendo in considerazione il primo aspetto come criterio di classi
cazione, emergono tre grandi
categorie di Sistemi di raccomandazione:
• Sistemi Collaborativi: All'utente sono raccomandati oggetti che sono piaciuti ad altre persone
con gusti simili.
• Sistemi Content-based: All'utente sono raccomandati oggetti simili a quelli che gli sono
piaciuti nel passato.
• Sistemi Knowledge-based: All'utente sono raccomandati oggetti sulle speci
che esigenze
dell'utente.
• Sistemi Ibridi: Combinano approcci content-based e collaborativi.
• Sistemi Community-based: All'utente sono raccomandati oggetti che sono piaciuti ad altre
persone della stessa rete sociale.
• Sistemi Demographic-based: All'utente sono raccomandati oggetti sulle speci
che esigenze
demogra
che dell'utente.
2.2.1 Sistemi Collaborativi
Le reccomandazioni si basano sulle valutazioni che gli utenti fanno sull'articolo, raccolte in una
user-item rating matrix.
I Sistemi Collaborativi usano dierenti tecniche di implemetazione che si dividono in due categorie:
• Memory-based: metodo che usa l'intera matrice o una parte di essa.
• Item-based (item-item): due articoli sono simili se l'utente ne dà una valutazione simile.Il
sistema suggerisce l'articolo con le caratteristiche più simili a quelle dell'articolo a cui l'utente
ha dato la valutazione migliore.
• User-based (user-user): due user sono simili se danno valutazioni concordi. Il sistema fa una
raccomandazione basandosi sulle opinioni espresse dallo user più simile.
8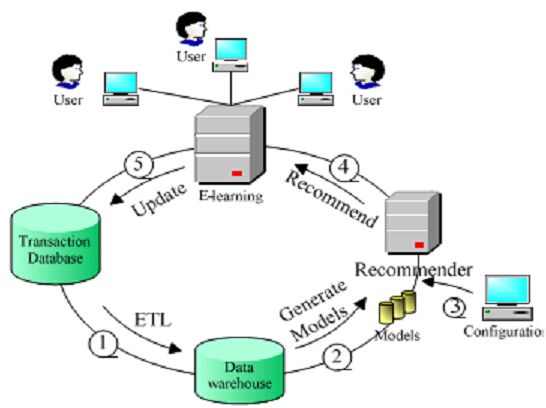
• Model based: i dati presenti nella matrice utente-articolo vengono rielaborati da algoritmi di
machine learning e data minig(algoritmi di clustering).
Le problematiche dei Sistemi Collaborativi:
• Cold Start: al momento del primo utilizzo del sistema non ci sono abbastanza utenti con cui
cercare delle similarità.
• First rater problem: i nuovi articoli, se non sono ancora stati valutati, non possono essere
proposti a nessun utente.
• Data sparsity: ipoteticamente si dovrebbe avere una matrice completa con dati di tutti
gli utenti e di tutti gli articoli. Gli utenti dovrebbero essere molto attivi (rating), ma è
impossibile una copertura del 100% degli utenti e degli articoli.
2.2.2 Sistemi Content-based
I Sistemi Content-based raccolgono informazioni sia relative all'articolo che allo utente ( i sistemi
collaborativi invece si basano solo sul rating degli user).
• Item representation: gli articoli vengono descritti con set di proprietà de
nite manualmente
o estratte automaticamente dalle caratteristiche dell'articolo.
• User pro
le: raccoglie informazioni che rispecchiano gli interessi e le caratteristiche dell'utente.
Le informazioni sono raccolte implicitamente(e.s social network) o esplicitamente ( dati
dichiarati volontariamente dell'utente).
Le problematiche dei Sistemi Content-based:
• Lack of infos: in alcuni ambiti di interesse potrebbero mancare informazioni relative un
determinato articolo o potrebbero esistere contenuti di
cili da analizzare.
• User pro
le: possono essere suggeriti solo articolo il cui contenuto sia associabile ad un pro
lo
utente. Se l'utente ha delle preferenze che non esprime, articoli inerenti a questo interesse
non verranno raccomandati.
2.2.3 Sistemi Knowledge-based
Possiamo elencare due tipologie di Recomender System Knowledge-based:
• Case-based: viene stimato quanto le necessità dell'utente (descrizione del problema) comba-
cino con le raccomandazioni (soluzione del problema). Il risultato della stima è un punteggio
(similary score) che rispecchiano l'eettiva utilità del RS.
• Constraint-based: simili ai case-based ma sfruttano conoscenze prede
nite che contengono
regole speci
che inerenti il rapporto tra user e item(e.s SPOTIFY).
Nella tabella sotto vediamo i pro e i contro dei sistemi visti
n'ora:
9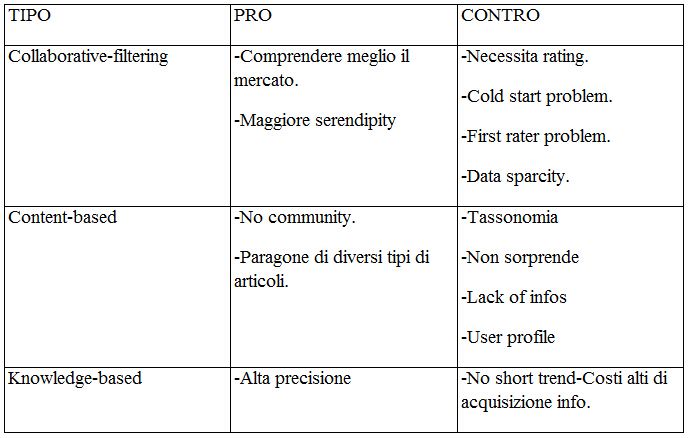
2.2.4 Sistemi Ibridi
Con i cosidetti Sistemi Ibridi si è tentato di rispondere ai problemi di entrambi gli approcci Content-
based o Collaborativi utilizzando contempora- neamente le due tecniche. Gli algoritmi content-
based promettono, infatti, di fornire raccomandazioni accettabili anche in casi in cui i dati sono
minimi, mentre quelli collaborativi riescono a rispondere alla necessità di generare raccomandazioni
non ovvie e sempre interessanti.
Esistono due distiniti approcci con cui è gli algoritmi ibridi possono essere realizzati:
• Un'implementazione separata di algoritmi content-based e collaborativi, per poi utilizzare
come risultato
nale una combinazione di predizioni provenienti da entrambi gli approcci.
• Lo studio di un'unica implementazione che riesca a fondere in uno tecniche basate sui con-
tenuti e collaborative.
Il primo si rivela valido in casi in cui sia preferibile usare, a seconda delle circostanze, una tecnica
piuttosto che un altra, o addirittura in casi in cui si voglia de
nire con un parametro quanto la rac-
comandazione debba essere collaborativa e quanto content-based. Il secondo, invece, non permette
un tuning speci
co, ma ha il vantaggio di essere, in generale, di più semplice implementazione
fornendo, comunque, risultati comparabili con l'altro tipo di approccio.
• VANTAGGI: I sistemi ibridi, come appena descritto, presentano in parte tutti i vantaggi dei
sistemi Content-based e Collaborativi, sebbene ognuno di essi sia eettivamente limato in
quanto inserito in un approccio non puro.
• Limiti dei Sistemi Ibridi: Il tentativo, peraltro ben riuscito, di porre dei paletti alle limitazioni
di entrambi i modelli che i sistemi ibridi si fanno obiettivo di fondere, ha come ovvio prezzo
da pagare quello di smussare anche i vantaggi derivanti dall'uno e dall'altro approccio!
Sopra abbiamo visto l'implementazione dei sistemi ibridi mettendo solo Content-based e Collabo-
rativi come due Recommender System per realizzarli ma esistono anche approcci generali di Sistmi
ibridi:
• Monolytic hybridation: i dati di due tipologie di RS vengono uniti.
10• Parallel hybradation: i risulati di due tipologie di RS vengono uniti.
• Pipeline hybridation: un tipo di RS (solitamente Knowledge-based) elabora i propri dati e
esclude gli item che non matchano con gli interessi dell'utente. I dati vengono elaborati su
un'altra tipologia di RS per poi produrre l'output.
2.2.5 Sistemi Community-based
I social network orono connessioni di diverse dimensioni, le persone possono essere amici tra
di loro. Queste persone, amici tra di loro possono avere interessi comuni e possono classi
care i
prodotti in maniera uguale. I sistemi community-based possono essere usate per dare una soluzione
al Cold Start Problem, e prendendo come rating il risultati degli amici per l'utente interessato.
112.2.6 Sistemi Demographic-based
Per spiegare questo sistema prendiamo l'esempio dei turisti. Maggior parte dei RS esistenti per
turisti applicano gli approcci knowledge-based and content-based, i quali hanno bisogno dello
storico dei rating o informazioni extra e sorono dal Cold Start Problem. Il Demographic-based
categorizza i turisti usando i loro dati demogra
ci e poi dà delle raccomandazioni basata sui dati
demogra
ci forniti.
Il vantaggio:
• Non ha più bisogno dello storico dei rating e delle informazioni extra.
• Cosi un nuovo turista può avere delle raccomandazioni precise.
Concentrandosi sui rating di Trip Advisor, possiamo utilizare diversi metodi di machine learning su
di esse per la produzione di previsione di rating. Mischiando il rating e le informazioni demogra
che
dei turisti possiamo produrre delle raccomandazioni con maggiore precisione.
122.3 Mobile Recommender System
Un'area di ricerca in crescita nell'area di Recommender System è l'area di Mobile Recommendere
System. Un'esempio di mobile recommender system è la geolocalizzazione del utente.
2.3.1 Context-aware recommendation
Il contesto è fondamentale: qualsiasi informazione su tutto ciò che circonda l'utente, qualsiasi
contenuto rilevante per l'interazione tra l'utente e l'ambiente.
Gli aspetti principali sono:
• Posizione dell'utente
• Persone con cui si trova l'utente
• Risorse nelle vicinanze
2.3.2 Proximate selection
La geolocalizzazione è fondamentale nella Proximate selection: elementi in prossimità della po-
sizione dell'utente sono enfatizzati e resi più facili da visualizzare e quindi da scegliere.
Ciò comporta due variabili:
• Geolocalizzazione
• Selezione di elementi da visualizzare ( preferenze dell'utente)
2.3.3 Privacy
Un collo di bottiglia per i mobile recommender system è la privacy: l'interoperibilità degli utenti
può essere limitata. Paura della violazione della privacy. La domanda che potrebbe fare è : Perchè
dovrei darti i miei dati personali?
• Non voglio che l'applicazione abbia accesso ai miei dati
• Non voglio condividere con l'applicazione la mia posizione
• Ho paura a immetere le mie preferenze all'interno di un sistema che non so se eettivamente
mi potrà essere utile.
Tuttavia la maggior parte delle app fa proprio a
damento sulla geolocalizzazione dell'utente.
Per cui se l'utente non vuole condividere la propria posizione, vi è data la possibilità di inserire
un indirizzo attorno al quale cercare servizi ed elementi utili richiesti. Così facendo anche gli
utenti inpauriti dalla loro privacy possono usufruire dalle potenzialità dei Recommender System
che orono le applicazioni.
132.4 Sistemi di raccomandazione ed E-learning
La popolarità del e-learning nei nostri giorni ha causato una crescita esponenziale di risorse disponi-
bili nella rete e parallelamente, una maggiore di
coltà nella ricerca e selezione delle risorse. I lettori
che sono interessati ai corsi oerti dalle diverse piattaforme e-learning sono obbligati alla ricerca
in
nita che li porta magari anche sui percorsi un pò fuori dal motivo vero e proprio della ricerca.
Il successo della implementazione dei sistemi di raccomandazione nel ambito del e-commerce ha
creato un grande interesse nelle Università e negli altri ambienti scienti
ci l'implementazione dei
raccomander system anche nel ambito di e-learning. Questa implementazione ha portato con se
anche diverse teorie per far si che il RS sia abbastanza mirato da schiacciare via i fantasmi del
passato in questo ambito, dico i fantasmi perchè prima per trovare dei corsi buoni ed e
cienti
bisognava spendere ore ore davanti al computer.
A dierenza dei tradizionali motori di ricerca, i RS possono coniugare le risorse che rispon-
dono a speci
che richieste dell'utente con quelle di possibile interesse perché implicitamente col-
legate ad esse. La de
nizione di una tecnica di raccomandazione per l'e-learning richiede, però,
un'approfondita analisi di tutte le dimensioni coinvolte nel processo di apprendimento, che vanno
dall'obiettivo didattico delle risorse, alle caratteristiche cognitive dello studente.
Questo paragrafo descrive brevemente i Sistemi di Raccomandazione in ambito E-learning.
2.4.1 Algoritmi
I sistemi di raccomandazione basati sulla correlazione dei lettori ( Learner-to-Learner )raccoman-
dano corsi ai lettori basandosi sulle correlazioni tra i lettori presenti e quelli del passato che hanno
studiato nella piattaforma di E-learning online. Questa tecnologia è conosciuta come abbiamo
già visto nei paragra
di questo capitolo, Collaborative Filtering ma in questo caso applicata in
ambito E-learning. Questo algoritmo è classi
cato come tecnica di
ltraggio di informazioni che
usa opinioni di gruppi per raccomandare agli individui singoli.
In questo ambito la tecnica viene implementata in due maniere. La prima, gli utenti votano i corsi
in maniera esplicita, in questo caso il sistema va verso la maniera manuale delle raccomandazioni.
Quella di prendere la classi
ca dei corsi più votati e poi raccomandare agli utenti. La seconda, gli
utenti guardano i corsi e il sistema memorizza il comportamento dei lettori in relazioni ai corsi o
video corsi. In questo caso il sistema è tutto automatizzato, perchè trasforma tutto quello che ha
memorizzato da un rating implicito a quello esplicito. Praticamente registrando e dando un voto
ai corsi visitati.
Il punteggio dei lettori può essere mostrata come una matrice m•n come mostrato nella tabella
sotto, dove m è il numero degli utenti, n è il numero dei corsi e Rj,k rappresenta il punteggio del
corso Corsok dato dal utente j .
Il passaggio più importante nel RS Collaborative Filtering based è quella di calcolare la similarità
tra i lettori come si potrebbe fare per calcolare il proximity-based neightborhood tra un utente
speci
co e un numero di utenti che hanno la stessa opinione. Il processo della creazione dei cluster
è il modello della costruzione per un algoritmo di RS.Il principale scopo della creazione di questi
cluster è di trovare, per ogni utente u, una lista ordinata di l'utenti N = {N1 , N2 , N3 , ..., Ni } tale
che u∈
/N e sim(u,N1) è massima, sim(u,N2) è la massima prossima e cosi via.
142.4.2 Design del sistema
Di solito il sistema di raccomandazione si progetta indipendentemente dal sistema di e-learning,
per ridurre la carica del sito di e-learning. Comunque la collaborazione tra il RS e il sistema di
e-learning è trasparente al utente. Quando un utente fa una ricerca, gli viene fornita la pagina
delle raccomandazioni, non sapendo la tecnologia dell'implementazione che sta sotto. L'unione del
servizio di e-learning e RS dà un sistema di raccomandazione personalizzato, e la relazione tra i
servizi è mostrata nella
gura sotto:
Come possiamo vedere, la parte centrale del servizio è il sistema di raccomandazione. Il processo
principale e diviso in cinque step:
• Data Collection: recuperando i dati storici, interessi degli utenti e le pagine o corsi più
frequentati. I log dell'accesso, informazioni sui corsi e la classi
ca dei corsi sono le fonti dei
dati primari.
• ETL ( Extract, transform, load): L'estrazioni dei dati è determinante per la raccomandazione,
dati dierenti sono processati per diverse richieste.
• Model Generation: Secondo i requisiti di raccomandazione , i modelli sono generati utiliz-
zando i corrispondenti algoritmi di raccomandazione , e sono memorizzate nel database dei
modelli.
• Con
guration: Dierenti modelli e algoritmi sono deployate in diverse strategie di raccoman-
dazione per supportare diversi tipi di servizi.
• Service Supply: I RS analizzano le richieste degli utenti, eseguono gli algoritmi corrrispon-
denti e poi restituiscono il risultato all'utente.
I processi descritti sopra sono in constante circuito e vengono mostrate dalla
gura sotto:
La
gura sopra mostra l'architettura dei raccomander system nel ambito e-learning. I moduli
principali dell'architettura sono:
15• Recommendation Models Database: I modelli di raccomandazione sono salvate nel database
che poi vengono estratte da diversi servizi di raccomandazione. Questo database è gestito dal
modulo Data/Models Managment, il quale costruisce modelli di raccomandazione multipli
per generare diversi tipi di raccomandazione.
• Recommender System Database: Su questo database vengono salvate le strategie di racco-
mandazione. Stabiliscono una relazione una-a-una con la macchina delle raccomandazioni, e
viene gestita dal modulo Recommendation Managemen . Raccomandation Engine carica
diverse strategie con
gurate nel Recommendation System Databas e genera le raccoman-
dazioni.
• Recommendation Managment: Questo modulo gestisce le strategie per il Recommendation
Engine , includendo l'algoritmo della raccomandazione ed il modello nello stesso tempo.
Controllo la sicurezza sugli utenti e le transazioni, gestisce anche lo stop e lo start del Engine.
• Data/model Management: Questo modulo gestisce i modelli ed il dataset nel data ware-
house , creando delle operazioni di CRUD sulle raccomandazioni, caricando, cancellando e
aggiornando il dataset.
2.5 Valutazione dei Recommender System
Si distinguono due tipi di metriche per valutare un Recommender System: le misure per valutare
la qualità e le misure per valutare le performance. Le prime analizzano i suggerimenti,le seconde
il RS come sistema.
2.5.1 Qualità
Le metriche per valutare le qualità di un Reccomender System sono tante e noi elenchiamo quelle
più note e importanti.
2.5.1.1 Accuratezza
Le tecniche ideate per quanti
care l'accuratezza sono molte, e tra queste possiamo annoverare
le metriche statistiche e la teoria delle decisioni. Alla prima categoria appartengono la mean
absolute error (MAE) e la root mean squared error (RMSE) e della seconda possiamo già
citare la ROC sensivity.
• Mean Absolute Error (MAE): uno dei metodi per determinare l'accuratezza (o viceversa,l'errore
di classi
cazione), è il Mean Absolute Error, che calcola la media della dierenza assoluta
tra i rating previsti dal RS e la valutazione che successivamente l'utente esprime.
|pi,j − ri,j |
P
{i,j}
M AE =
n
dove n è il numero totale di rating su tutti gli user, Pi,j è il rating previsto per l'utente i sull'item
j e ri,j è il rating eettivo.Più basso è il valore del MAE e migliore è la predizione del rating. A
volte è utile normalizzare tale valore rispetto alla scala utilizzata nel RS speci
co, in modo da
poter poi comparare sistemi che utilizzano rating minimo (r min ) e massimo (r max )diversi. In tal
caso si calcola la Normalized MAE (NMAE):
M AE
N M AE =
rmax − rmin
16• Root Mean Squared Error (RMSE): è la metrica prescelta per stimare la qualità dei RS
nell'ambito del Net
ix Prize.
v
u1
u X
RM SE = t (pi,j − ri,j )2
n {i,j}
dove n è il numero totale di rating su tutti gli user, pi,j è il rating previsto per l'utente i sull'item
j e ri,j è il rating eettivo.
• ROC sensivity: è una misura della potenza di previsione di un RS. Operazionalmente è data
dalla Area Under the ROC Curve (AUC), letteralmente l'area sotto la curva ROC12.In realtà
il valore di AUC è quello dell'area sotto la curva ROC soltanto se la previsione è un problema
con due possibili esiti (problema binario). In generale la ROC sensivity si calcola con la
seguente formula:
S0 − n0 (n0 + 1)/2
AU C =
n0 n1
dove
P n0 e n1 sono rispettivamente il numero di previsioni sbagliate e di previsioni corrette,e s0 =
ri , dove ri è il rank dell'i-esima previsione positiva nella lista delle previsioni, ordinata per
precisione.
2.5.1.2 Copertura
La copertura è una misura della percentuale di oggetti per i quali l'algoritmo che genera i
suggerimenti può risolvere il recommandation problem. In alcuni casi, ad esempio a causa della
sparsità della matrice user-item, il sistema non è in grado di produrre una predizione per i rating
di molti oggetti. In situazioni simili il valore della copertura certamente è basso.
Assumendo che ni siano gli item per i quali l'utente ui ha fornito una valutazione e npi sia il
numero degli item per cui il RS è in grado di generare una predizione del rating, allora la copertura
è data dalla formula:
Pm
npi
Coverage = Pi=1
m
i=1 ni
dove m è il numero di righe e colonne della matrice user-item (m x m).
Esistono due tipi di coperture, chiamate prediction coverage and catalogue coverage. Prediction
coverage è un misura per la percentuale dei item che i RS posso fornire previsioni. Catalogue cov-
erage dall'altra parte fornisce una misura della percentuale dei item che non verrano racomnadate
a nessun'utente. Una copertura completa signi
ca che il RS puo prendere decisioni in qualsiasi
situazione. La copertura puo essere misurata prendendo un semplice esempio random di user/item
da un set di dati e chiedere al RS di dare la raccomandazioni per tutti quelli scelti. Le coperture
Predictive e Catalogue possono essere stimate insieme.
172.5.1.3 Con
denza
Con
denza nei RS può essere de
nita come la
ducia che i sistemi hanno nelle loro raccoman-
dazioni e previsioni. Come abbiamo visto nei collaborative
ltering che tendano a migliore la loro
precisione mentre la quantità dei dati sugli articoli cresce. Simile, la con
denza nella previsioni
tipicamente cresce con l'aumento dei quantità dei dati.
Le raccomandazioni fatte da un RS possono essere caratterizzate da due dimensioni: la forza (la
potenzialità che un RS ha) e la con
denza. La forza indica quanto piacerà all'utente l'articolo rac-
comandato. Con
denza indica quant'è sicuro un RS riguarda l'accuratezza della raccomandazione
che dà.
I RS hanno approcci dierente per la Con
dence. La maggior parte dei quali non raccomandano
gli articoli con il livello di con
denza sotto un certa soglia. Un'altro approccio è quella di mostrare
all'utente la con
denze della raccomandazione. Quest'ultimo approccio dà più possibilità all'utente
di fare da solo le scelte.
Per esempio, se un RS raccomanda un
lm con una con
dence molto alto, e un altro
lm con
lo stesso rating ma con un con
dence basso. L'utente che sta consultando questo sistema può
aggiungere nella lista dei
lm da vedere il
lm con con
dence alto ma invece per l'altro può andare
a cercare altre informazioni prima di aggiungerlo o forse non aggiungerlo neanche.
2.5.1.4 Fiducia(Trust)
Se la Con
dence e la
ducia che il sistema ha nel suo rating, nel Trust si riferisce alla
ducia
dell'utente nelle raccomandazioni del sistema. Per esempio, può essere un bene
cio per il sistema
di raccomandare quei pochi articoli che l'utente conosce già e li piacciono. In questo modo l'utente
crea la
ducia nel sistema ma non serve a niente perché queste raccomandazioni non li stanno
aggiungendo nessun valore nella consultazione. Questa
ducia creata al sistema può aumentare la
sua
ducia anche sui articoli che questo sistema raccomanderà in futuro, articoli forse sconosciuti
per l'utente.
Un altro metodo per sapere la
ducia che l'utente ha nel sistema è quello più ovvio dobbiamo dire,
perché si tratta di fare i sondaggi sugli utenti che usano il sistema.
Possiamo assumere anche che la
ducia sulle raccomandazioni del sistema è correlata anche con
la frequenza che l'utente visita il sistema. Se l'utente torna quando il sistema dà delle nuove
raccomandazioni, perché se per esempio abbiamo sempre utenti nuovi e cerchiamo sempre di avere
la
ducia nel nostro RS dai quei utenti rischiamo di non avere utenti che hanno già
ducia nel
nostro RS e possono consultare le raccomandazioni fornite.
2.5.1.5 Novelty
Le raccomandazioni Novel sono raccomandazioni per degli articoli che l'utente non conosce.
Nelle applicazioni che si usano questi tipi di raccomandazioni l'implementazione richiede dei
ltri
che escludono tutti gli articoli che gli utenti hanno già usato e aver dato un parere su di esse. Resta
il fatto che in tanti casi gli utenti non dicono gli articoli che hanno usato in passato, quindi questo
semplice metodo per
ltrare sui item risulta insu
ciente.
Possiamo misurare la Novelty anche o ine chiedendo agli utenti che hanno familiarità con gli
articoli raccomandati. Per questo possiamo fare un esperimento:
Facciamo uno split del dataset in base al tempo, nascondendo tutti i feedback degli utenti che si sono
veri
cati dopo uno speci
co punto temporale.In aggiunta possiamo nascondere alcune valutazioni
che si sono veri
cati prima di quel tempo, simulando gli elementi che l'utente abbia familiarità ma
non ha dato valutazioni per loro. Quando raccomandando, il sistema viene premiato per ogni
18elemento che è stato consigliato e valutato dopo il tempo di split, ma sarebbe stato punito per
ogni elemento che è stato consigliato ma valutato prima del tempo dello split.
Per implementare la procedura sopra descritta dobbiamo modellare attentamente il sistema che
toglie i feedback. Questa progettazione è abbastanza di
cile perché se per esempio se crediamo
che l'utente fornirà più rating su oggetti speciali, ma meno ratings per oggetti popolari, allora
il sistema dovrebbe tendere a nascondere gli elementi più popolari. Ad usare questa sistema di
valutazione è importante controllare la precisione, raccomandazioni irrilevanti possono essere nuove
per l'utente ma possono essere anche di nessun valore.
Un possibile approccio potrebbe essere di considerare Novelty solo tra gli item rilevanti.
2.5.1.6 Serendipity
Serendipity è una misura di quanto sorprendenti sono le raccomandazioni di successo. Per
spiegare meglio prendiamo un esempio concreto: se l'utente ha valutato positivamente molti
lm
in cui compare un attore famoso, raccomandando il nuovo
lm di quell'attore può essere una
novità, perché l'utente non può sapere l'esistenza di quel
lm, ma di
cilmente si sorprenderà.
Ovviamente, le raccomandazioni casuali possono essere molto sorprendenti, e per fare ciò abbiamo
quindi bisogno di bilanciare la serendipità con la precisione.
Le probabilità del veri
carsi della serendipità:
• La serendipità non può avvenire se l'utente conosce già ciò che gli viene proposto.
• Minore è la possibilità che l'utente conosca un item, maggiore è la probabilità che la proposta
sia serendipitosa.
• Possiamo assumere che la probabilità che l'utente conosca qualcosa concettualmente vicino
a iò che siamo erti lui conosca sia maggiore della probabilità che lui conosca qualcosa di
concettualmente lontano.
• Se decidiamo di valutare la vicinanza concettuale con una metrica di similarità, ne risulta
che è più probabile che si veri
chi serendipità proponendo all'utente qualcosa di dissimile dal
suo pro
lo.
Novelty vs Serendipity Sia Novelty e Serendipity sono tutti i due esempi di non-ovvietà.
• Novetly: raccomandazione di un item non conosciuta che l'utente avrebbe potuto scoprire
autonomamente.
• Serendipity: raccomandazione di un item non conosciuto che l'utente non avrebbe potuto
scoprire autonomamente
L'esempio classico e quella della raccomandazione dei
lm come sono descritti sopra.
2.5.1.7 Diversity
Diversity è de
nita come il contrario di Similarity. In tanti casi suggerire un insieme di oggetti
simili può mandare in tilt l'utente perché può stare ore e ore su quei oggetti ad esplorare quello che
interessa a lui. Per spiegare questa di
coltà possiamo prendere come esempio un RS di vacanze
dove vengono raccomandate cinque pacchetti viaggio, tutti nello stesso posto ma hanno diversi
hotel o dipendono dalle attrazioni che loro orono. Invece sarebbe più opportuno raccomandare
cinque pacchetti viaggio in posti diversi così l'utente ha più facilità a decidere. Il metodo più usato
19per misurare la Diversity usa la similarità degli oggetti, basato sul contenuto di quei oggetti. Come
in caso delle vacanze. Dopo questo andiamo a misurare la diversità della lista basato sulla somma,
media,minima e massima distanza tra la coppia degli oggetti(item-item).
L'approccio ideale per misurare la diversity deve tenere conto di :
• Diversi
care con minime perdite di accuratezza.
• Applicare meccanismi di bilanciamento parametrizzato.
2.5.1.8 Utility
Tanti siti web di e-commerce sono alla ricerca delle raccomandazioni che aumentano le vendite per
aumentare i pro
tti. In questo caso i RS sono valutati per quanto pro
tto porta al sito. Misurare
l'utilità può diventare molto più importante che misurare la precisione della raccomandazione. Si
possono usare altri funzioni come potrebbe essere la Diversity e Serendipidity. Cosi come abbiamo
visto negli esempi sopra può aumentare l'utilità di una raccomandazione può essere alta mischiando
le due funzioni sopra citate. Un approccio possibile sarebbe usare la Diversity per facilitare il
compito agli utenti per scegliere gli articoli nel sito di e-commerce e la Serendipidity per sorprenderli
a farli comprare quei articoli che stanno guardando.
2.5.1.9 Risk
In alcuni casi una raccomandazione può essere associato a potenziali rischi. Il metodo standard
per valutare il rischio è non solo per valutare l'utilità ma anche la varianza dell'utilità:
Possiamo usare un parametro q e confrontare due sistemi nella:
E[X] + q • V ar(X)
Quando q è positivo questo approccio dà delle raccomandazioni risk-seeking, e quando q è negativo
dà delle raccomandazioni risk-averse.
2.5.1.10 Robustness
La robustezza è la stabilità a dare delle raccomandazioni in presenza delle informazioni fake,
tipicamente inseriti a proposito per in
uenzare le raccomandazioni. Ci sono delle persone che si
a
dano ai RS di guidarli verso una vasta gamma di oggetti ed altre persone che in
uenzano i RS
per dare delle raccomandazioni che potrebbero essere molto redditizie per alcuni.
Questi tentativi per in
uenzare le raccomandazioni in un RS sono chiamati attacchi, come tutti
gli attacchi informatici comuni (tipo SQL injection) fatti apposto da un utente malintenzionato.
Creare un sistema che è immune a qualsiasi attacco informatico è irrealistico. Un attacco che per
esempio può iniettare una massa di informazioni tale per cui varia le raccomandazioni in un RS
può capitare, è molto utile misurare il costo della in
uenza delle raccomandazioni.
Un altro tipo di robustezza è la stabilità di un sistema sotto condizioni estreme, come una grande
numero di richieste.
202.5.1.11 Adaptivity I sistemi di raccomandazioni reali possono operare in un ambiente dove
gli ogetti cambiano rapidamente, o i trend del mercato possono cambiare così rapidamente che
le raccomandazioni possono essere inutile o addirittura obsoleti. Un esempio di questo tipo di
sistema è quello dei NEWS. In questo scenario le raccomandazioni possono essere interessanti solo
in un periodo breve del tempo, dopo la quale diventano obsoleti. Se una notizia inaspettati come
un disastro naturale per la gente diventa interesasnte ed è da raccomandare. In questo caso il
problema del Cold Start non cè più perchè non è collegato all'utente ma da altri fattori. Per
valutarlo possiamo misurare la dierenza tra la lista di raccomandazioni prima e dopo l'aggiunta
di una nuova notizia.
2.5.1.12 Scalability Come i sistemi di raccomndazione sono disegnate per aiutare gli utenti
a navigare in una marea di informazioni, uno degli obbiettivi principali dei progettisti è di scalare
verso un dataset reale. Come tale, capita speso che l'algoritmo prende altre proprietà , come
l'accuratezza e la coprebilità, per restituire risultati velocemente anche se abbiamo a che fare con
un grande dataset con millioni di oggetti. La scalabilità è misurata tipicamente da esperimenti
con l'aumento dei dati che ci sono nel dataset, mostrando come la velocità di suggerimenti ed il
consumo delle risorse cambiano nel aumentare dei dati.
2.5.2 Performance
Le metriche per misurare le performance di un RS che ho considerato sono il tempo di risposta, i
requisiti di memoria e la complessità computazionale.
• Tempo di risposta: è de
nito come il tempo che intercorre tra la richiesta iniziale di un
utente e la risposta del sistema a tale richiesta. Si noti che si suppone di avere a che fare con
RS di tipo pull, cioè dove esiste una query esplicita da parte dell'utente.
• Requisiti di memoria: di solito i requisti di memoria sono analizzati secondo due direttrici.
Una è lo spazio occupato online, l'altra è lo spazio occupato o ine. Gli elementi di cui si
tiene conto per calcolare tali valori sono principalmente la memoria necessaria per gli utenti
e quella necessaria per gli item.
• Complessità computazionale: nell'esecuzione di un RS di solito si possono distinguere due
fasi. Alla prima appartengono tutte le operazioni che possono essere eseguite o ine, come il
preprocessing, la rappresentazione di utenti e item, il calcolo delle similarità e l'individuazione
dei vicini. La seconda, invece, comprende tutte i calcoli che devono essere eettuati necessari-
amente online, in base alle interazioni con l'utente. Delle due, la fase che incide maggiormente
sulla complessità computazionale del RS è la prima.
213 IRS-NETT(Interactive Recommender System di NETT)
3.1 Progetto Nett
NETT (Networked Entrepreneurship Training of Teachers), il cui logo è mostrato sopra, è un pro-
getto
nanziato dalla Commissione Europea e da DG Impresa e Industria con il compito di creare un
Social Network per migliorare l'insegnamento dell'imprenditorialità nel sistema educativo europeo.
Il progetto si basa sulla creazione di una piattaforma
nalizzata allo scambio di contenuti, espe-
rienze, metodi tra insegnanti di oggi e di domani responsabili dell'educazione all'imprenditorialità.
La piattaforma, attraverso l'uso delle più avanzate tecnologie, sarà di supporto ad una Social
Community dove le persone coinvolte nell'educazione all'imprenditorialità potranno trovare un
luogo dove discutere, scambiarsi opinioni e trovare risposte ed aiuti concreti per realizzare una
modalità Europea di formare i giovani imprenditori, rispettando la realtà industriale e commerciale
locale.
Il progetto coinvolge tre nazioni europee: Italia, Bulgaria e Turchia e tra i partner aderenti al
progetto troviamo: l'Universita degli Studi di Milano e Arkè Management Consulting per l'Italia,
EGECED (Institute of Education and Youth Studies Association) per la Turchia e ITD (Institute
of Technology and Development) per la Bulgaria.
Questo progetto nasce come parte integrante delle iniziative promosse dall'Unione Europea con
l'obiettivo di promuovere lo sviluppo dell'imprenditorialità in Europa, facendo leva sul delicato
tema dell'educazione.
Lo spirito imprenditoriale si sviluppa in un ambiente che incoraggia le forme attive d'apprendimento
e tal ne è necessario un sostegno che suppone una formazione iniziale dei docenti, i quali devono
disporre del tempo e delle risorse necessarie per piani care, realizzare e valutare le attività e chiarire
le responsabilità.
NETT fornirà agli educatori all'imprenditorialità uno spazio virtuale sempre disponibile ed acces-
sibile a tutti, dove trovare le competenze appropriate, le opportunità, gli strumenti e le tecnologie
di qualità per insegnare in modo pratico ed e
cace l'imprenditorialita, creando una vera e propria
online community dove condividere tecniche d'insegnamento e esperienze personali,contribuendo
alla continua formazione personale dei docenti.
La piattaforma, partendo dai docenti e dai formatori, avrà un impatto sull'intero sistema educativo
europeo: si stima che essa, nei primi mesi di attività, avrà oltre 100 utenti, per poi incrementare
il loro numero
no a 1000 al termine dei due anni dal rilascio.
223.1.1 Sondaggio sulle esigenze di formazione
Per la realizzazione di una piattaforma che possa rispondere al meglio alle esigenze di formazione
all'imprenditorialità, si è reso necessario un sondaggio quantitativo su piccola scala, il quale ha
coinvolto docenti italiani, turchi e bulgari provenienti da scuole primarie, secondarie ed istituti
universitari.
La maggior parte dei quesiti posti agli insegnanti ha come obiettivo l'individuazione di quelle
attività e metodi didattici ritenuti basilari per l'apprendimento di competenze in ambito impren-
ditoriale.
Tale sondaggio sulle esigenze di formazione ha preso in esame le seguenti problematiche e interrog-
ativi:
1. Quali sono le età, il sesso, il livello di istruzione e l'esperienza di insegnamento dei docenti
partecipanti?
2. I docenti si sentono competenti in materia di imprenditorialità o parteciperebbero ad un
corso di formazione in materia? Pensano che trarrebbero bene
ci seguendo un corso?
3. Quali competenze sono piu importanti in materia di imprenditorialità?
4. Quali competenze sono necessarie per l'apprendimento?
5. Qual'e la percentuale di docenti che insegnano imprenditorialità?
6. Quali vantaggi potrebbe portare la divulgazione?: a)sostenere lo sviluppo e creare nuovi
posti di lavoro? b)adattarsi alle attuali realtà di mercato? c)inserire gli studenti in ambiente
imprenditoriale? d)contribuire allo sviluppo del business plan?
7. Quali metodi sarebbero da adottare per l'insegnamento?
3.1.2 Risultati del sondaggio
Questo sondaggio ha fortemente condizionato la struttura della piattaforma. Professori e pro-
fessionisti sono stati selezionati da diverse regioni italiane, in modo da avere i punti di vista
delle diverse aree geogra
che e dei contesti italiani. Infatti è evidente la tendenza a considerare
l'imprenditorialità come una serie di capacità personali quasi innate, in netto contrasto con le
disposizioni europee che la considerano come una materia scolastica da inserire nei programmi
didattici dei singoli istituti.
233.2 IRS-Nett
L'idea è quella di motivare l'uso di un RS in termini di:
• Riduzione della grande quantità di risorse disponibili;
• Risparmio di tempo nella ricerca di materiale;
• Possibilità concreta di creare un corso di alto livello, ben strutturato e ben organizzato; tutto
ciò in conformità con le esigenze del docente stesso.
L'appellativo Interactive presente nel nome del Sistema di Raccomandazione di NETT, che si col-
loca nell'ambito dell'Interactive Machine Learning, sottolinea una caratteristica fondamentale che
dierenzia questo preciso Recommender System dalla maggior parte di quelli presenti in letter-
atura, fondamentalmente per il paradigma altamente interattivo che abbraccia; permette, infatti,
che sia l'utente a dirigere i vari step della raccomandazione sulla base dei suggerimenti e proposte
inviati dal sistema automatico; si tratta quindi di un sistema intelligente user-centric.
NETT-RS fornisce inoltre una raccomandazione basata su regole: se si veri
ca una determinata
condizione, allora verrà prodotto un determinato tipo di raccomandazione; tale approccio è stato
scelto in quanto questo tipo di modello è allo stesso tempo uno dei più espressivi e comprensibili
ovvero fornisce soluzioni facilmente interpretabili e di indubbia semantica. Molto spesso gli utenti
non sono precisi nel prendere decisioni o nel manifestare preferenze: utenti dierenti interpretano
in maniera diversa gli stessi concetti; si è deciso, così, di adottare il paradigma Fuzzy, il quale
attribuisce un grado di verità da 0 a 1 a determinate proposizioni.
Ultima osservazione riguardante NETT-RS: viene sfruttata anche una valutazione espressa sui
corsi e sui moduli all'interno della piattaforma; valutazione fornita da Experts, da studenti e da
insegnanti. Come si può notare, questa caratteristica è propria dei sistemi Collaborative; sfruttando
anche metadati e keywords, alla stessa stregua di un Content Based System, rientra nella categoria
degli approcci ibridi.
3.2.1 Algoritmi NETT-RS: tre fasi principali
Il Sistema di Raccomandazione NETT-RS fornirà al docente una scelta limitata di risorse didattiche
presenti nella piattaforma, tra quelle più pertinenti e di successo, mirando a fornire consigli e
suggerimenti con una frequenza elevata, aspettandosi dall'utente una decisione prima di procedere
ad ulteriori raccomandazioni.
Tutto ciò rende questo processo una sorta di catena Markoviana, dove il suggerimento al tempo t
dipende dai suggerimenti precedenti e dalle decisioni prese dall'utente.
Il sistema richiede all'utente alcune informazioni per essere in grado di fornire suggerimenti corretti;
tra queste è presente anche il numero di parti in cui il docente vorrà suddividere il corso che vorrebbe
comporre.
L'interazione tra sistema e utente consiste in un loop dove, ad ogni ciclo, viene completata
l'organizzazione di una singola parte del corso; si possono distinguere tre fasi di questo ciclo:
1. Scelta della parte più signi
cativa: Il Sistema di Raccomandazione invoca J48, algoritmo
di classi
cazione il quale permette di individuare la parte più signi
cativa tra le rima-
nenti e, inoltre, ha il compito di selezionare i soli record che si riferiscono alla parte se-
lezionata. Valutando quindi la signi
catività delle parti, il sistema ripulirà il dataset, ri-
cavato dalle informazioni presenti nella tabella di mdl_metadata (Id_metadata, Id_course,
24Puoi anche leggere

















































