Studio ed analisi del Cloud Computing - UNIVERSITA' DEGLI STUDI DI SIENA
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
UNIVERSITA’ DEGLI STUDI DI SIENA
FACOLTA’ DI INGEGNERIA
Corso di Laurea Specialistica in Ingegneria Informatica
Studio ed analisi del Cloud Computing
Relatore
Prof. Marco Maggini
Correlatori
Carlo Bardi
Cesare Bertoni
Tesi di Laurea di
Elvio Stumpo
A.A. 2008/2009
Introduzione: Il calcolo distribuito
Introduzione: Il calcolo distribuito
Negli ultimi anni, lo sviluppo tecnologico-scientifico, per poter progredire, ha richiesto
l’impiego di un numero sempre crescente di uomini e macchine. Nella scienza moderna
l’impiego di calcolatori è diventato di vitale importanza; infatti, ad essi vengono affidate
tutte quelle attività che l’uomo non è in grado di fare con la stessa perizia propria di questi
strumenti. L’utilizzo sistematico di queste apparecchiature negli ambienti scientifici ha da
sempre generato una richiesta costante di macchine sempre più efficienti e sempre più
potenti. Il costante bisogno di calcolatori sempre più performanti, soprattutto agli albori
dell’Informatica, risultò essere un problema di notevole portata. A quei tempi, immettere sul
mercato un elaboratore era uno sforzo ingente sia di capitali che di mano d’opera, tanto che
non si era in grado di soddisfare tutte le potenziali richieste. In quel periodo (o era
informatica) il rapporto macchina-uomo era uno a molti, vale a dire, un calcolatore per molti
utilizzatori. Questa situazione generò non pochi conflitti per l’accaparramento della risorsa
da parte degli utenti. Intorno agli anni ’80 ci fu un sostanziale abbattimento dei costi
hardware che generò una diffusione su larga scala degli elaboratori così che si iniziò a parlare
di personal computer, di conseguenza il rapporto macchina-uomo passò da uno a molti a uno
ad uno. L’era informatica seguente fu caratterizzata da una semplice conclusione sul
confronto di prestazioni: si misero a paragone i supercomputer, all’epoca ancora molto
costosi, e semplici reti di personal computer molto più economiche, ed emerse che queste
ultime riuscivano a fornire prestazioni uguali ed a volte addirittura superiori a quelle proprie
dei supercomputer. Si iniziarono a preparare le basi per quello che oggi chiamiamo reti di
calcolatori. L’introduzione di tali reti modificò il rapporto macchina-uomo che passò a molti a
uno.
Nell’ultima era, l’attuale, la nuova frontiera è il calcolo
distribuito. Quest’ultimo può essere facilmente confuso
con il calcolo parallelo, vale a dire, la capacità di
esecuzione di più task simultaneamente su più
processori contenuti, però, nella stessa macchina.
L’idea di fondo della teoria del calcolo distribuito,
invece, è quella di frammentare il carico di lavoro in un
Fig.1. Esempio di connettività.
numero arbitrario di sotto task indicati solitamente con
il nome di “job” da distribuire ad un numero
imprecisato di macchine, eterogenee tra loro, sparse potenzialmente in tutto il mondo. Al
contrario del calcolo parallelo, in cui l’assegnazione dei task è certa, nel calcolo distribuito
non vi è l’assoluta sicurezza che le macchine della rete siano sempre disponibili (tempi di
latenza diversi, crash imprevedibili di rete o dei computer, ecc. ) quindi è necessario un
continuo monitoraggio dell’architettura. Il problema fondamentale che nasce dall’impiego di
questo genere di tecnologia è tutto concentrato sulla gestione corretta del traffico (cioè
priva di errori sia in trasmissione che in ricezione) di qualsiasi tipo (dati, job, comandi, ecc).
Studio ed analisi del Cloud Computing -1- Stumpo Elvio
Introduzione: Il calcolo distribuito
Un’ulteriore problematica deriva da una caratteristica fondamentale del calcolo distribuito:
la coesistenza nella rete di macchine che supportano diversi sistemi operativi spesso
incompatibili con altri. Per porre rimedio a tale ostacolo si è lavorato su due fronti diversi: il
primo, implementando nella rete la possibilità di trasmissione di software scalabile ed
adattabile (scalabilità e portabilità) fra macchine diverse; il secondo, invece, basando tutta
l’architettura su applicazioni di tipo web (web-oriented). Una corretta condivisione delle
risorse su scala mondiale permette di generare una potenza di considerevole dimensione,
che può essere impiegata per risolvere problemi con grandi moli di dati d’ingresso.
L’utilizzatore del calcolo distribuito ignora completamente come le risorse siano reperite:
infatti, per l’utente, l’impiego di tale tecnologia consiste solamente nell’operazione di
connessione tramite internet ad una macchina non meglio identificata che gli fornirà la
potenza necessaria. Il fruitore standard del calcolo distribuito, infatti, non sarà in grado di
sapere se le risorse impiegate per il suo programma provengano dalla sua macchina, da un
cluster di computer dall’altro capo del mondo, dal vicino di casa o da una elaborata unione di
queste varie realtà. L’utente, inoltre, non conosce lo stato d’opera dei processi eseguiti
tramite il calcolo distribuito, ma ha la reale possibilità di conoscere l’istante in cui il job è
stato lanciato e quando esso terminerà effettivamente (con successo o crash).
Attualmente sono presenti diverse tipologie di sistemi di interconnessione per il calcolo
distribuito:
• Client-Server: la macchina client contatta la macchina server grazie ad un
programma specifico lanciato in remoto sul client stesso, il quale si occupa di
contattare i vari sistemi e/o servizi per ottenere dati, configurazioni varie ed inoltre è
fornito di una interfaccia utente riassuntiva della rete consultabile dal fruitore.
• Architettura a 3 strati (3-iter architecture): sistema a tre stati nel quale le
informazioni del client vengono inserite in uno stato intermedio in cui sono presenti,
a sua volta, client inattivi in attesa di utilizzo (ad esempio per l’accesso ai dati).
Questo sistema semplifica molto il processo dello sviluppo applicativo. La maggior
parte delle applicazioni web di richiesta sono strutturate a 3-strati.
• Architettura a N strati (N-iter architecture): si riferisce tipicamente ad applicazioni di
tipo web che fondamentalmente inoltrano le loro richieste a terze parti. Questo
metodo per richiedere informazioni è stato la chiave del successo delle applicazioni
server.
• Accoppiamento stretto (tight coupling): si riferisce tipicamente ad un cluster di
macchine strettamente connesse, che gestisce un processo condiviso in parallelo. La
frammentazione del task originario è molto elastica e strettamente legata al tipo di
risorse che ogni elemento delle rete è in grado di offrire. A conclusione di tutti i job
su tutte le macchine, tramite un processo di merge, si ha il risultato finale.
• Peer-to-peer: un'architettura dove non sono presenti macchine speciali o macchine
che offrono un servizio o gestiscono le risorse di rete. Tutte le attività, invece, sono
divise uniformemente fra tutte le macchine, note come peers (pari). I peers possono
comportarsi alternativamente sia da client che da server.
Un altro aspetto di base dell’architettura di calcolo distribuito è il metodo di comunicazione
e coordinamento del lavoro con processi simultanei. Attraverso l’impiego di vari protocolli di
Studio ed analisi del Cloud Computing -2- Stumpo Elvio
Introduzione: Il calcolo distribuito comunicazione, i processi possono sincronizzarsi e comunicare direttamente con l'un l'altro, solitamente secondo il criterio client/server. Con il continuo aumento di apparecchiature contenenti un microprocessore e una connessione ad alta velocità è facile dedurre che l’impiego del calcolo distribuito attuerà un processo di riduzione dei tempi di computazione, fino ad arrivare a ottenere risposte in real- time a problemi che attualmente richiedono ore, giorni o anni. Alcune applicazioni del calcolo distribuito hanno avuto un tale impatto sul mondo scientifico da meritare di essere descritti individualmente. Studio ed analisi del Cloud Computing -3- Stumpo Elvio
Capitolo 1 Architetture di calcolo distribuito
Capitolo 1 Architetture di calcolo distribuito
1.1-Grid computing
I sistemi Grid sono le prime grandi infrastrutture di calcolo distribuito, utilizzate per
l’elaborazione di un gran numero di dati, mediante l’uso
di una vasta quantità di risorse. In particolare, tali sistemi
permettono la condivisione coordinata di risorse
all’interno di un’organizzazione virtuale. La condivisione
non è limitata solo allo scambio dei files, ma si estende
all’accesso diretto al computer, al software, ed in
generale a tutto l’hardware necessario alla risoluzione di
un problema scientifico, ingegneristico o industriale. Il
sistema grid si articola essenzialmente in due fasi
Fig.1-1. Classica disposizione di una rete principali: creazione e testing. Nella prima fase,
a griglia (Grid Computing). mediante un’opportuna interfaccia grafica, l’utente è in
grado di inserire le caratteristiche del sistema grid
desiderato. Al termine della prima fase, data dall’inserimento delle caratteristiche, inizia la
seconda fase, relativa alla simulazione. Durante la simulazione i dati vengono elaborati e
viene presentato all’utente un report contente tutte le informazioni e le risposte del sistema,
cioè il risultato raggiunto dalla rete per il problema propostole. Il problema alla base del
concetto di griglia è la condivisione coordinata di risorse all’interno di una dinamica e multi-
istituzionale organizzazione virtuale (Virtual Organization, brevemente indicata con VO).
L’utente conosce il numero delle macchine che verranno impiegate per la propria
simulazione (tale valore fa parte della configurazione statica della rete che è scelta
dall’utente), ma ignora la loro posizione geografica.
Attualmente, la più importante grid europea è quella del CERN di Ginevra (ora diventata
EGEE); il software più famoso ed utilizzato è BOINC (Berkeley Open Infrastructure for
Network Computing). Questo è un software di grid computing sviluppato dall'Università della
California (Berkeley) ed è classificato come un open source, anche se sarebbe meglio parlare
di software gratuito e completamente personalizzabile. L’idea che guida questo genere di
sistema, infatti, è quello di donare, a progetti che la richiedono 1, la potenza computazionale
inutilizzata delle proprie apparecchiature connesse in rete (ora è disponibile anche in
remoto). Per aderire a tale progetto le operazioni fondamentali sono due : inizializzazione e
elaborazione. Nella prima fase (inizializzazione) si compiono diverse operazioni, alcune delle
quali una tantum (download del client BOINC e sua relativa GUI, creazione di credenziali
valide per la rete, configurazione della macchina ecc.) altre, invece, mutabili nel tempo
1
Un classico esempio di impiego dell’architettura grid è Seti@home. Tale progetto consiste
nell’ascolto del rumore cosmico proveniente dallo spazio alla ricerca di un qualsiasi tipo di segnale
contenente informazioni. La distinzione tra il rumore spaziale ed i potenziali segnali artificiali (segnali
non di origine naturale, ma generati per un scopo ben preciso) viene eseguita mediante una
monitorizzazione continua dello spettro conosciuto.
Studio ed analisi del Cloud Computing -4- Stumpo Elvio
Capitolo 1 Architetture di calcolo distribuito (scelta dei progetti a cui si intende partecipare, pacchetti di dati da analizzare (work unit dette WU), ecc ). Nella seconda fase il client di BOINC, in remoto, analizza costantemente le risorse impiegate, per adoperare le rimanenti risorse inutilizzate per eseguire le work unit. Queste donazioni di risorse vanno a fondo perduto, l’utente standard di BOINC non ha nessun ritorno oggettivo (economico, computazionale ecc). Gli unici beneficiari del servizio sono i committenti dei progetti a cui gli utenti collaborano. BOINC è il classico esempio di grid computing anche se unidirezionale (utente=forza lavoro). Esistono anche reti a griglia che, diversamente dal BOINC, consentono agli utenti, che ne fanno espressa richiesta, di sfruttare le risorse per progetti propri (l’utente è forza lavoro ma anche utilizzatore della rete grid). L’elemento fondamentale che caratterizza il grid, ed anche uno dei componenti più critici del sistema di gestione delle risorse, è lo schedulatore di risorse. Esso ha il compito di assegnare le risorse ai job, in modo da soddisfare le esigenze delle applicazioni e del sistema. Le risorse delle griglie sono strettamente connesse tra loro, geograficamente distribuite, eterogenee ed, inoltre, appartengono a diversi individui o organizzazioni, ciascuno con le proprie politiche di scheduling, modelli di costo di accesso differenti, carichi di lavoro e disponibilità di risorse che variano dinamicamente nel tempo. La mancanza di un controllo centralizzato, insieme alla presenza di utenti che generano job, molto diversi l’uno dall’altro, rendono la schedulazione più complicata rispetto a quella dei sistemi di calcolo tradizionali. Il calcolo a griglia, rispetto ad altri tipi di tecnologie, ha già subito un processo di standardizzazione univoca che quindi permette l’iter-connessione delle griglie stesse senza problemi di interfacciamento. Fra le caratteristiche che sono state formalizzate e che, quindi, qualsiasi sistema grid deve garantire vi è il carico minimo: il fornitore delle rete certifica che il proprio prodotto in situazione di estremo carico garantisce per ogni progetto in corso l’esecuzione di un determinato carico di lavoro. Sono tuttavia emersi alcuni difetti di questo tipo di rete (la non completa trasparenza delle macchine ma soprattutto la loro assegnazione molto rigida e statica) che hanno portato allo sviluppo di altri tipi di reti, le reti cloud. Studio ed analisi del Cloud Computing -5- Stumpo Elvio
Capitolo 1 Architetture di calcolo distribuito
1.2-Cloud computing
Il cloud computing (calcolo a nuvola, o nube) è visto dagli esperti del settore come la vera
innovazione del web 2.0. Spesso, per una migliore comprensione della nube, la si paragona
alle Google Apps.
Questa comparazione è ammissibile solo a livello teorico-nozionistico, ma non è del tutto
corretta, anche se vi sono effettivamente dei punti di contatto tra le due tecnologie.
Il cloud computer può essere
visto come un super computer
(inteso come grandi risorse di
tipo informatico) che ha come
sua ubicazione la rete internet.
Il clouding in realtà, non
basandosi su una architettura
rigida, “racimola”, su richiesta,
le risorse disponibili ovunque
nella rete, sia provenienti da
un PC, da un notebook, da un
netbook, da un palmare e,
addirittura, anche da un
Fig.1-2. Rappresentazione dello sviluppo del word wide web cellulare connesso ad internet.
Il pioniere del cloud
computing fu John McCarthy che fornì una sua prima formalizzazione nel 1960. Solo negli
anni ‘90 il termine cloud iniziò ad entrare nei linguaggi di tipo commerciale per riferirsi alle
grandi reti di ATM. Negli ultimi anni, iniziò ad apparire il termine "cloud computing", anche
se la maggior parte dell’interesse verso questa emergente innovazione era finalizzata alla
realizzazione di un software che
offrisse un servizio.
Per l'alto livello concettuale,
infatti, la nube di calcolo è
definita come "una
combinazione di hardware,
software, dati e persone, che
fornisce servizi on-line".
Importante è notare la
strettissima coesistenza che
esiste nel cloud computing tra i
consumatori e i produttori dei
servizi. Le architetture cloud
Fig.1-3. Rappresentazione schematica dell’evoluzione architetturale di sono enormi aggregati di
Internet diverse reti (universitarie,
Studio ed analisi del Cloud Computing -6- Stumpo Elvio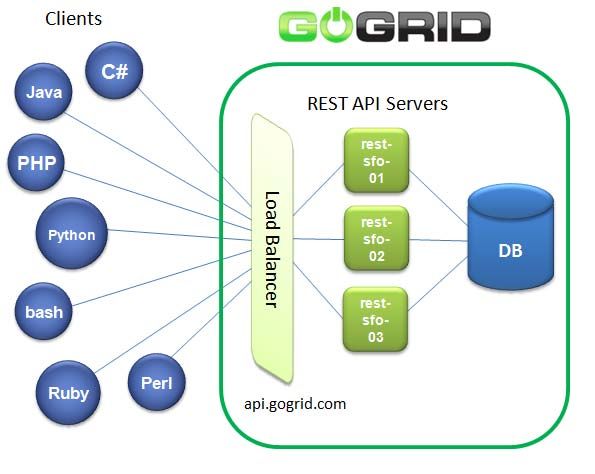
Capitolo 1 Architetture di calcolo distribuito commerciali), di supercomputer e di cluster di computer. Esse sono utilizzate da un numero enorme di persone sia in qualità di utenti (solo Microsoft Live ha più di 300 milioni di utenti) e sia in qualità di sviluppatori (Amazon EC2 ha attualmente più di 330.000 sviluppatori di applicazioni). Attualmente nel web centinaia di milioni di utenti si collegano a Google regolarmente ogni giorno (20 Petabytes di dati giornalieri); a questi si aggiungono le operazioni che gli utenti dei servizi di eBay compiono (1 Terabyte di log giornalieri solo nel 2000): tali fenomeni generano enormi flussi di dati e di informazioni che in qualche modo devono essere gestiti. Possiamo concludere che il cloud computing, per le sue caratteristiche intrinseche, ha una massiccia partecipazione ad analizzare tali dati, tanto da collaborare attivamente alla creazione di una mega-struttura onnipresente, sempre disponibile, che lavora con circa 100 di milioni di utenti. Diversamente dal calcolo a griglia, ogni utente partecipa alla rete per avere un proprio beneficio, quindi, più risorse. In queste condizioni il cloud pone grandi sfide, ma offre opportunità senza precedenti a tutta la comunità informatica-scientifica che gravita attorno a questa architettura. Il cloud computing, infatti, rappresenta un nuovo approccio alle infrastrutture in cui grandi insiemi di sistemi sono collegati tra loro per fornire servizi IT. L’esigenza di tali ambienti è sempre più sentita per la crescita esponenziale delle apparecchiature connesse in rete e dei processi di streaming di dati in tempo reale e anche per la diffusione di architetture e applicazioni web 2.0 orientate al servizio, ai progetti di collaborazione e di ricerca. I progressi nelle prestazioni dei componenti digitali hanno provocato un enorme aumento della portata degli ambienti IT, e di conseguenza, è nata l’esigenza di poterli gestire uniformemente in un’unica “nuvola” (cloud). Le potenzialità del calcolo a nube, inoltre, risultano essere particolarmente adatte ad un gran numero di progetti, ma soprattutto a quelli di carattere scientifico, tanto da essere impiegate massicciamente per il calcolo intensivo. La scienza ha da sempre impiegato le migliori risorse disponibili per raggiungere i propri obiettivi; essa, infatti, può essere suddivisa in tre grandi periodi: empirico, teorico e sperimental-simulativo. Il primo periodo è stato principalmente applicativo, ovvero, privo di una qualunque struttura astratta; il secondo periodo, quello delle grandi scoperte, è stato caratterizzato dalla formulazione delle principali teorie scientifiche. Oggi ci troviamo nel terzo periodo, quello della scienza sperimentale in cui si creano flussi di dati da utilizzare per la simulazione, ma soprattutto si sta attuando un processo di condivisione e di collaborazione tra gli scienziati ad un livello senza precedenti. L’evoluzione di mega strutture di dati, ha generato fenomeni sociali articolati su vasta scala denominata “social computing”. In tali condizioni sono presenti tutti gli stimoli necessari per creare un nuovo tipo di ricerca scientifica basata sul web la “web-scienza”. Se tale ricerca vedrà la luce, il calcolo a nube ricoprirà un ruolo fondamentale in questa nuova dimensione scientifica. L'emergere delle architetture a nube consentirà, infatti, nuove prospettive stimolanti in ingegneria, in medicina e per molti problemi di ordine sociale. La nascita della nube di calcolo rinvigorirà la ricerca accademica e fornirà un forte spinta alla creazione di collaborazioni, di metodi innovativi e di nuovi comportamenti. Le attività accademiche attualmente sono ben Studio ed analisi del Cloud Computing -7- Stumpo Elvio
Capitolo 1 Architetture di calcolo distribuito
al di sotto delle loro effettive potenzialità, questo perché gli scienziati devono confrontarsi
con una vasta quantità di dati provenienti non solo dal web, ma anche da un numero
crescente di strumenti e sensori.
L’utilizzo del cloud computing permetterà agli scienziati di fruire di un sostanziale aumento
dei dati d’ingresso per le loro simulazioni, che forniranno risultati con un’accuratezza mai
raggiunta. Questo perché il cloud computing può essere impiegato per gestire carichi di
lavoro già esistenti, ma anche per quelli emergenti, altamente scalabili e basati su grandi
quantità di dati.
Considerate le numerose applicazioni del cloud, fornire una definizione univoca che lo
caratterizzi al meglio risulta essere un’operazione estremamente difficile. Una sua possibile
definizione è comparsa sul ACM Computer Communication Review ”Le nubi sono grandi
contenitori di risorse virtuali di facile utilizzo ed accesso (come lo posso essere vari software
ma anche l’hardware, le piattaforme di sviluppo e/o di servizio). Queste risorse possono
essere dinamicamente riconfigurate per adattarsi ad un carico di lavoro variabile (scalabilità)
lasciando spazio anche ad un'utilizzazione ottimale di risorse. Questo contenitore di risorse è
impiegato tipicamente secondo il modello pay-for-use (pagare per usare) nel quale tutto è
garantito dal provider dell’infrastruttura”.
Un errore che spesso si compie è quello di confondere il cloud computing con altri tipi di
architetture di calcolo distribuito, primo fra tutti il grid computing. La confusione tra il cloud
computing e le altre architetture è giustificata dalla non remota possibilità che il cloud si
comporti, a volte, come un grid e mostri alcune caratteristiche tipiche di altri generi di reti.
Dagli studi compiuti su questa architettura traspare che il cloud computing può essere a tutti
gli effetti definito come la vera e naturale evoluzione del modello grid computing, anche se
le tipologie delle reti sono estremamente diverse tra loro. Come per le reti a griglia, la
progettazione e la creazione di una rete cloud è un’operazione di non facile realizzazione. I
sistemi cloud migliori, ad esempio, dispongono di una piccola infrastruttura centralizzata, ma
a volte ne sono addirittura privi o possono persino appoggiarsi ad un qualsiasi sistema, anche
esterno, come le reti peer-to-peer o Skype. La maggior parte delle infrastrutture basate sulla
nube forniscono agli utenti servizi affidabili in funzione del livello di virtualizzazione richiesto.
I servizi sono accessibili in
qualsiasi parte del mondo, questo
perché il sistema cloud è visto
come un singolo punto d’accesso
che permette di raggiungere una
rete talmente grande da
contenere le risorse necessarie
per tutti gli utenti della nube. Le
offerte commerciali basate sul
cloud computing forniscono ai
loro clienti, servizi di qualità e
Fig.1-4. Rappresentazione della comunicazione standard tra i soprattutto adatti al livello
computer e la rete cloud
Studio ed analisi del Cloud Computing -8- Stumpo Elvio
Capitolo 1 Architetture di calcolo distribuito
virtuale che l’utente sceglie di utilizzare. I sistemi di tipo open - source che utilizzano il cloud
computing rendono critico lo sviluppo dello stesso perché attualmente non esistono ancora
degli standard di regolamentazione unici.
Il grande pregio di questo tipo di tecnologia è che gli utenti finali possono avere accesso a
grandi risorse di qualsiasi tipo (calcolo, memorizzazione etc.) in maniera del tutto virtuale,
quindi, abbattendo completamente tutti i costi delle infrastrutture fisse (acquisto,
mantenimento, potenziamento etc.). L’utente finale, infatti, pagherà l’uso delle risorse
virtuali solo all’atto del loro effettivo utilizzo. Alcuni provider del cloud computing sono
Amazon, Google e Yahoo e, ultimamente, anche Microsoft con Azure. Amazon ha giocato un
ruolo chiave nella conoscenza e nello sviluppo del cloud computing compiendo una
modernizzazione dei suoi centri di calcolo. I suoi sviluppatori, infatti, avevano trovato una
nuova architettura di tipo cloud che ha dato luogo a significativi miglioramenti in termini
d’efficienza interna ed, inoltre, ha offerto ai propri clienti l’accesso ai sistemi di Amazon Web
Services da impiegare per scopi di calcolo di tipo non avanzato. Il 2007 è stato l’anno
dell’aumento delle attività finalizzate all’architettura a nube, infatti sia Google, sia IBM, che
un discreto numero di università decisero di investire grandi risorse per la ricerca e lo
sviluppo e, nel giro di poco tempo, il cloud cominciò a guadagnare popolarità presso la
stampa, fino ad arrivare nel 2008, anno in cui diventa un argomento di discussione tanto da
essere presente in numerosi eventi.
Nell’agosto 2008 gli esperti del settore hanno osservato che le organizzazioni stavano
cambiando hardware e software per utilizzarne altri, orientati verso modelli di servizio e che
in questo ambito l’impiego del clouding avrebbe dato luogo ad una crescita così
sorprendente da essere drammatica per tutte le altre aree dell’IT.
1.2.1-Problematiche d’impiego
Attualmente la nube attraversa numerosi confini di vario tipo e può essere definita come
"l'ultima forma di globalizzazione". E come tale è soggetta a problemi complessi di tipo
geopolitico. I provider, infatti, devono soddisfare una miriade di ambienti diversi e regolare i
vari servizi in funzione dei continui cambiamenti del mercato globale. Le diverse richieste di
sicurezza da impiegare nella nube risultano fortemente basate sul territorio geografico
d’impiego, e quindi sul tipo di utenti.
Gartner, analista di tecnologia e consulente d’azienda, ha elencato sette problemi di
sicurezza sui quali si dovrebbe discutere con le aziende che forniscono il cloud computer:
1) Individuazione dell’utente privilegiato: colui che è in grado di accedere a tutte le
risorse della rete cloud.
2) Comprovata serietà: verifica dell’effettiva serietà dei produttori del servizio anche
mediante l’impiego di società specializzate, eventualmente anche esterne al
fornitore della rete.
3) Ubicazione dei dati: conoscenza del luogo ove viene allocato lo spazio di memoria e
se queste località godano di un adeguato servizio di sorveglianza territoriale.
Studio ed analisi del Cloud Computing -9- Stumpo ElvioCapitolo 1 Architetture di calcolo distribuito
4) Crittografia: garanzia che la cifratura sia disponibile a tutti i livelli e che tale
crittografia sia fornita da esperti del ramo.
5) Recupero dati: l’iter da seguire dalla rete e/o dalle aziende in caso di perdita di dati.
6) Controllo investigativo: conoscenza della possibilità della nube di essere impiegata
per controllare le attività legali o illegali degli utenti.
7) Autosufficienza: conoscenza di quanto accada alla nube qualora la società che
fornisce il servizio fallisca.
1.2.2-Componenti
Volendo formalizzare gli elementi che formano una qualsiasi rete cloud si sono definiti i
seguenti componenti:
Client
Cloud client: consiste nell’hardware (dispositivi di qualsiasi
Services
tipo connessi a internet) e nel software (un qualsiasi browser
Application
come google crome firefox ecc.) di cui il sistema cloud
Platform
necessita per funzionare correttamente.
Storage
Cloud services: consiste nei servizi web: un sistema software Infrastructure
Fig.1-5. Componenti
progettato per sostenere interazioni di tipo machine-to- fondamentali del cloud
machine di interoperabilità su una rete. Questi software
possono essere ottenuti da un’altra nube il cui scopo principale è quello di calcolare
componenti software, software per servizi, o informazioni sugli utenti finali (identità,
integrazione, pagamenti, mappature, ricerca, etc).
Cloud application: architetture software, che eliminano il bisogno di installare e
gestire le procedure client sul computer dell’utente, alleviando così il carico di
manutenzione del software, delle operazione in corso, etc. (Facebook, Google Apps,
Salesforce, Microsoft Servizi On-line).
Cloud platform: è un servizio che consegna una piattaforma di calcolo e/o pile di
soluzioni utilizzando una serie di domande da rivolgere all’utente senza che
quest’ultimo debba avere una conoscenza profonda degli strati del software (Ajax
(Caspio), Python Django (Google App Engine), Ruby on Rails (Heroku), Web hosting
(Mosso), Proprietary (Azure, Force.com)).
Cloud storage: comporta la capacità di memorizzazione dei dati come un servizio
offerto dalla rete (calcolati per gigabyte per mese) (Database, Synchronisation Web
Service).
Cloud infrastructure: il servizio che mette a disposizione reti di computer virtuali
(Grid computing (Sun Grid), Compute (Amazon Elastic Compute Cloud), Blue Cloud
(IBM), Azure (Microsoft)).
Studio ed analisi del Cloud Computing - 10 - Stumpo ElvioCapitolo 1 Architetture di calcolo distribuito
1.2.3-Architettura
Analizzando la rete a nube a livello funzionale osserviamo che l’architettura del cloud
computing è un sistema
software finalizzato alla
realizzazione di nubi di
calcolo, comprensive
sia di hardware
(virtuale) che di
software, disegnati da
un “architetto” che
tipicamente lavora per
garantire la completa
integrazione tra le
diverse nubi. Il sistema
cloud comporta
componenti multipli
Fig.1-6. Descrizione degli elementi caratteristici che compongono una classica che comunicano l'un
architettura cloud l'altro su interfacce di
programmazione, di
solito mediante web services.
Questo approccio ricorda da vicino la filosofia Unix: avere programmi multipli che lavorano
bene insieme su interfacce universali. La complessità è controllata ed i sistemi risultanti sono
più maneggevoli dei sistemi di tipo monolitico. Definiamo, infine, le entità fondamentali
presenti nell’ambiente dell’architettura a nube:
Cloud Provider: è l’entità che possiede e gestisce le risorse delle reti cloud assegnando
sia le risorse di calcolo che i servizi per ogni utente; inoltre, possiede ed implementa
sistemi di calcolo di “cloud live” per distribuire servizi a terze parti. Di solito questo
richiede risorse significative ed esperienza nella costruzione di centri di calcolo.
Nonostante tutto, alcune grosse organizzazioni hanno notato che il possedere un
provider cloud porta all’azienda che ne fa un uso esclusivo numerosi benefici in termini
di efficienza, soprattutto nella gestione dei casi di picchi di carico. Questi benefici sono
controbilanciati da una notevole complessità, sia di tipo economico (acquisto,
mantenimento e aggiornamento delle macchine) che prettamente architetturale. Una
delle prime grandi aziende a superare gli ostacoli iniziali è stata Amazon che nel 2002 ha
basato il suo Amazon Web Services su architetture di tipo cloud.
Cloud User: è il fruitore della nube. Un problema rilevante per questa entità è la “privacy
dell’utente” che potrebbe essere violata. Una possibile soluzione è la creazione di
comunità che garantiscano i diritti degli utenti.
Cloud Vendor: è l’entità che vende prodotti e servizi che facilitano l’uso, l'adozione e
l'uso di nube di calcolo.
Studio ed analisi del Cloud Computing - 11 - Stumpo ElvioCapitolo 2 Analisi sulle offerte cloud
Capitolo 2 Analisi sulle offerte cloud
L’architettura a nube è stata per molti colossi informatici il candidato migliore per la
risoluzione di alcuni problemi generati dall’elaborazione di dati su vasta scala. Tale speranza
ha portato lo stanziamento di risorse di ogni tipo, soprattutto di ordine economico, atte allo
studio e, successivamente, alla realizzazione di un’architettura a nube che rispondesse il più
possibile alle richieste degli investitori. Attualmente sul mercato sono presenti diverse
aziende che offrono servizi cloud: da colossi come Amazon, IBM, Google, Microsoft, fino a
realtà cloud offerte da società minori come la GoGrid.
2.1-GoGrid
L’architettura GoGrid è basata su un’infrastruttura a nube che offre un servizio di hosting e
mette a disposizione macchine virtuali di tipo Linux e Windows, in cui di default sono già
preinstallati programmi come IIS, Java,
C#, Apache, PHP, Microsoft SQL Server,
e MySQL. Gli elaboratori virtuali (o
immagini server) sono gestiti tramite un
pannello di controllo multi-sistema 2 che
permette con estrema facilità il
settaggio della macchina come singolo
server o come componente di un
cluster.
GoGrid, attualmente, mette a
disposizione due tipi distinti di hardware
Fig.2-1. Schema rappresentativo dell’architettura GoGrid (virtuali) – Fig. 2.2.
RAM CPU Storage Space L’utilizzo dei primi 10 GB di
spazio disco sono
4GB 3 Xeon 240GB completamente gratis per ogni
account. Alcune delle
8GB 6 Xeon 480 GB
caratteristiche hardware sono
Fig.2-2. Elenco delle possibili configurazioni disponibili in GoGrid. fisse (RAM e CPU) mentre lo
spazio di immagazzinamento
dati risulta essere altamente scalabile (senza nessun limite d’assegnamento o d’impiego) e
completamente a disposizione delle reti cloud sia di tipo Windows che di tipo Linux. GoGrid
permette anche l’espansione della memoria di massa anche dopo la costruzione della nube.
2
L'API Client di GoGrid sono gestite tramite tecnologia REST simile alla interfaccia query. Le
invocazioni dei metodi di GoGrid sono fatte attraverso Internet spedendo richieste di HTTP GET o
HTTP POST direttamente al Server GoGrid API REST il quale, a sua volta, risponde mediante la
medesima procedura.
Studio ed analisi del Cloud Computing - 12 - Stumpo ElvioCapitolo 2 Analisi sulle offerte cloud
Un’altra caratteristica della rete completamente personalizzabile è l’elasticità. Infatti
l’utente, qualora volesse, può scegliere, in maniera del tutto autonoma, il tipo di soluzione di
rete (software e hardware) da adottare nella propria nube, impiegando reti preesistenti o
creandone di ibride. La rete cloud offerta da GoGrid garantisce, inoltre, persistenza nello
stoccaggio dei dati. Questo vuol dire che l’hard disk virtuale, associato ad ogni account, non
perderà i dati critici durante un riavvio improvviso del server o di un nodo. Se,
accidentalmente, il server o un nodo della rete smettesse improvvisamente di funzionare, i
dati rimarrebbero intatti e sarebbero disponibili solamente quando l’elemento danneggiato
non fosse ripristinato o sostituito. Ad ogni cliente di GoGrid è assegnata una sua squadra di
esperti che seguono l’utente in caso di necessità. L’associazione team tecnico – cliente è
rigida, nel senso che ogni volta che l’utente ha bisogno di supporto, tratterà sempre con la
stessa squadra di esperti di cloud, i quali sono in possesso di tutte le informazioni del cliente,
della rete ad esso associata e della sua eventuale evoluzione. Il servizio di assistenza tecnica
è del tutto gratuito e sempre disponibile. In definitiva, le società che scelgono GoGrid come
cloud provider sono sempre seguite da esperti del settore e possono creare rapidamente
soluzioni di tipo hosting su provider di calcolo a nube che sono scalabili, affidabili, facili da
maneggiare ed economici.
2.2-IBM Blue Cloud
2.2.1-Cenni sull’organizzazione della nube
Il progetto Blue Cloud, forte della
grande esperienza di IBM nell’ambito
del calcolo intensivo, si basa su open
standard e software open source
supportati da servizi, tecnologie e
software IBM. Il cuore del Blue Cloud
è il BladeCenter vale a dire i sistemi di
cluster di server adibiti alle reti a
nube. Blue Cloud, inoltre, usa,
virtualizzazione di sistemi operativi
Fig.2-3. Schema riassuntivo dell’architettura Blue Cloud Linux con Xen e PowerVM, in
combinazione con lo schedulatore per
carichi paralleli Hadoop. Blue Cloud è supportato dal software IBM Tivoli per la gestione
dinamica dei server. Viene impiegato anche Google MapReduce per l’assegnazione e
l’esecuzione di vari task su cluster di macchine.
Il progetto cloud dell’IBM, nonostante la fortissima dipendenza (software, ma soprattutto
hardware) con l’azienda che lo ha creato, prevede anche la stretta collaborazione con varie
istituzioni, tra le quali sono presenti le università che impiegano l’architettura a nube per
accelerare i loro progetti e le iniziative di ricerca. Molto interessanti sono gli ambienti di
cloud computing di tipo accademico della Carnegie Mellon University, la Qatar University, la
Texas A&M University, la University of Pretoria e l'HEALTH Alliance.
Studio ed analisi del Cloud Computing - 13 - Stumpo ElvioCapitolo 2 Analisi sulle offerte cloud
2.2.2-Carnegie Mellon University, Qatar University, Texas A&M University (Qatar)
La stretta collaborazione tra queste tre università, tutte nel Qatar, ha dato origine ad un
progetto che si prefigge di portare il cloud computing in Medio Oriente. Le università
potranno avvalersi anche di collaborazioni esterne, come gruppi di esperti, ricercatori e,
addirittura, semplici clienti IBM per sviluppare una soluzione cloud in grado di contribuire a
risolvere varie tipologie di problemi.
Il Qatar Cloud Computing Center (è l’organismo costituito dalla sinergia delle tre università
prima citate) ha tra i suoi scopi principali la ricerca e lo sviluppo del data mining, della
modellizzazione scientifica e della simulazione, della biologia computazionale, della
modellizzazione finanziaria e del modello previsionale. Sono stati inoltre identificati cinque
progetti di applicazione pilota sui quali concentrarsi:
• modellizzazione sismica ed esplorazione per la ricerca di gas e petrolio
• soluzioni operative di produzione integrate per i settori petrolifero e del gas
• motore di ricerca web in lingua araba
• test e migrazione di varie applicazioni utilizzando i metodi di programmazione
Hadoop/MapReduce
• creazione di un percorso di formazione sul cloud computing presso le università.
2.2.3-University of Pretoria (Sud Africa)
Il Computational Intelligence Research Group, presso la University of Pretoria, utilizzerà il
cloud computing per la ricerca medica di futura generazione. Attraverso questa iniziativa, gli
studenti troveranno i modi per rallentare l'avanzamento di malattie gravi studiando le
percentuali di assorbimento dei farmaci e il ripiegamento della struttura proteica del DNA
una volta introdotto un certo tipo di farmaco. La soluzione cloud computing consentirà
anche di gestire meglio i progetti e i carichi di lavoro. In passato, non si disponeva di sistemi
dedicati alla gestione dei progetti di ricerca, e si doveva inoltre raccogliere manualmente i
risultati dei dati relativi agli esperimenti a causa della scarsa disponibilità di applicazioni per
la gestione delle informazioni.
I tempi di ricerca ora si sono ridotti da settimane a giorni e le diverse variazioni dei test di
ricerca sono disponibili nella soluzione cloud per trarne risultati utili dal punto di vista
statistico.
2.2.4-The Higher Education Alliance for Leadership Through Health (Africa
Orientale)
L'HEALTH Alliance, è un consorzio di sette università, che lavora con IBM ed esperti del
settore per ampliare le offerte formative attraverso laboratori informatici virtuali in modo
tale da consentire agli studenti l'accesso remoto. Tramite questo cloud, gli studenti
dell'Alliance potranno accedere ai materiali informatici formativi più avanzati, selezionare
applicazioni software e risorse informatiche e di storage senza dover sostenere spese di
manutenzione e alimentazione di ambienti informatici.
L'HEALTH Alliance, si dedica, tra le altre cose, a promuovere l'uso strategico della tecnologia
per impieghi inerenti alla sanità pubblica, prevedendo di insediare un Public Healthcare
Studio ed analisi del Cloud Computing - 14 - Stumpo ElvioCapitolo 2 Analisi sulle offerte cloud
Center of Excellence in grado di fornire assistenza sanitaria e servizi formativi facilmente
disponibili ai paesi dell'Africa sub-sahariana.
2.3-Google App Engine
Visto lo sviluppo della rete a nube, anche Google offre, ormai, da diversi mesi il suo nuovo
prodotto cloud: Google App Engine (GAE). GAE è
stato studiato come il metodo da seguire per
creare applicazioni web (HTTP-driven) da
ospitare sui web server di Google. A differenza di
EC2, e GoGrid, GAE scende nel campo delle
piattaforme cloud fornendo un framework di
tecnologie rigide, con le quali creare applicazioni
senza preoccuparsi della loro architettura e dei
picchi di traffico e carico. Il software è realmente
open source, infatti nelle pagine dedicate alla
cloud di Google si trova tutto, ivi compresi i listati
Fig.2-4. Confronto schematico tra GAE e una dei sorgenti (Python).
tipica rete cloud
2.3.1-Le risorse
La prima caratteristica della rete che si riscontra è la mancata scalabilità hardware della rete
stessa. Per ogni account, infatti, il Google App Engine associa solo una CPU 3 di tipo mono-
core. Attualmente non è prevista la possibilità dell’impiego di architetture multi-core tipiche
del cloud. Nonostante questa grossa limitazione che rende la rete abbastanza rigida, le sue
caratteristiche sono tutte monitorate, come: il carico della CPU, la banda trasmissiva
impiegata, le risorse realmente impiegate per ogni singola applicazione. Un dettagliato
pannello di controllo, infatti, riporta un lungo elenco di voci che indicano i consumi effettivi
(in continuo aggiornamento).
Un’ulteriore caratteristica che discosta GAE dalle comuni reti cloud è la completa mancanza
di virtualizzazione di sistemi operativi di ogni tipo; esso, infatti, permette la sola esecuzione
di codice Python, eventualmente associato ad un framework proprietario o ad una versione
alleggerita di Django. Per usufruire della rete GAE e, quindi, iniziare a sviluppare le
applicazioni, è necessario scaricare l'ambiente di sviluppo, che ricreerà le stesse condizioni
tecniche di GAE sulla propria macchina locale; l'SDK contiene, infatti, un web server, un
database, le strutture per recuperare indirizzi HTTP(s), quelle per l'invio di email e per la
manipolazione d’immagini.
3
Ad ogni singola CPU è associato un processore Intel con clock pari a 1.2 GHz con architettura X86
(32-bit).
Studio ed analisi del Cloud Computing - 15 - Stumpo ElvioCapitolo 2 Analisi sulle offerte cloud
2.3.2-I componenti fondamentali
Per poter controllare il consumo effettivo di risorse, GAE mette a disposizione tutta una serie
di servizi che le applicazioni possono sfruttare:
• Il Datastore: database un po’ particolare denominato BigTable, formato da una
piattaforma distribuita operante sul file system proprietario, GFS. Ha un linguaggio
simile a SQL con delle limitazioni a carattere operativo chiamato GQL. Nonostante le
limitazioni, comunque, è consentito un uso standard abbastanza vasto del database
da parte delle applicazioni.
• Google Accounts: è una API che permette di avere automaticamente un sistema di
login per le applicazioni, basato sugli accounts Google. Potrebbe essere un problema
di sicurezza basare l’identificazione dell’utente solo sull’impiego dell’account, ma
considerato che non esiste una versione business di GAE, il problema passa in
secondo piano.
• URL Fetch: le applicazioni possono accedere all'esterno, recuperando il contenuto di
URLs remoti sfruttando API basate sulla stessa infrastruttura che Google usa per altri
suoi prodotti. E' comunque possibile usare le librerie standard di Python se non si
vuole usufruire dell’infrastruttura Google (e dei suoi limiti).
• Mail: usata per inviare email con o senza allegati anche verso l’"admins" delle
applicazioni.
• Memcache: è uno storage di tipo “in-memory key-value”. Permette di inserire in
cache strutture, valori, risultati di query complesse e rendere, quindi, il recupero
degli stessi più veloce.
• Image Manipulation: permette di ridimensionare, ruotare ed effettuare operazioni
basilari su immagini in formato JPEG e PNG. Ogni richiesta HTTP ha 30 secondi di
tempo per essere evasa, l'SDK permette anche il deploy delle applicazioni per
svilupparle in locale, fino al momento dello spostamento sui server di Google,
riducendo al minino il carico della rete.
• Sandbox: . è un ambiente sicuro, affidabile, indipendente dall’hardware, dal sistema
operativo e dalla ubicazione fisica del sistema di servizio di web in cui vengono
conservate le richieste di rete dei vari utenti. Questo metodo garantisce accessi
sicuri, contemporanei e multipli alla rete GAE.
Studio ed analisi del Cloud Computing - 16 - Stumpo ElvioCapitolo 2 Analisi sulle offerte cloud
2.3.3-Costi per l’impiego della rete GEA
Ogni operazione (richiesta) sottoposta all’GAE, sia in entrata che in uscita, consuma un certo
livello di risorse addizionali che vengono addebitate sul proprio account.
Quota gratis predefinita Quota a pagam ento predefinita
Risorsa Lim ite Frequenza Lim ite Frequenza
quotidiano m assim a quotidiano m assim a
R
1,300,000 43,000,000 30,000
Richieste 7,400 richieste/minuto
I richieste richieste richieste/minuto
C Larghezza di banda uscente max 1,046 740
H
10 gigabytes 56 megabytes/minuto
(fatturabile, incluso Http) gigabytes megabytes/minuto
I
E Larghezza di banda entrante max 1,046 740
10 gigabytes 56 megabytes/minuto
S (fatturabile, incluso Http) gigabytes megabytes/minuto
T max 1,729
E Tempo di CPU (fatturabile) 46 ore-CPU 15 minuti CPU/minuto 72 minuti CPU/minuto
ore-CPU
10,000,000 57,000 140,000,000 129,000
D
Chiamate di API Datastore
chiamate chiamate/minuto chiamate chiamate/minuto
A
T
Stored Data (fatturabile) 1 gigabyte nessuna nessun limite max nessuna
A 153
S Dati inviati all'API 12 gigabytes 68 megabytes/minuto 72 gigabytes
megabytes/minuto
T
659 1,484
O Dati ricevuti dall'API 115 gigabytes 695 gigabytes
R megabytes/minuto megabytes/minuto
E
Tempo di CPU di Datastore 60 ore-CPU 20 minuti CPU/minuto 1,200 ore-CPU 50 minuti CPU/minuto
1,700,000 4,900
Chiamate API mail 7,000 chiamate 32 chiamate/minuto
chiamate chiamate/minuto
Destinatari email max 7,400,000 5,100
E (fatturabili)
2,000 destinatari 8 destinatari/minuto
destinatari destinatari/minuto
M Email Admins 5,000 email 24 email/minuto 3,000,000 email 9,700 email/minuto
A
Invio messaggi Body Data 60 megabytes 340 kilobytes/minuto 29 gigabytes 84 megabytes/minuto
I
L Invio allegati 2,000 allegati 8 allegati/minuto 2,900,000 allegati 8,100 allegati/minuto
300
Invio dati allegati 100 megabytes 560 kilobytes/minuto 100 gigabytes
megabytes/minuto
F Chiamate UrlFetch API 657,000 chiamate
3,000 46,000,000 32,000
chiamate/minuto chiamate chiamate/minuto
U E
740
R T Invio dati all'UrlFetch 4 gigabytes 22 megabytes/minuto 1,046 gigabytes
megabytes/minuto
L C 740
H Ricezione dati dall'UrlFetch 4 gigabytes 22 megabytes/minuto 1,046 gigabytes
megabytes/minuto
M Chiamate all'API 4,800 45,000,000 31,000
A 864,000 chiamate
N Manipolazione d'immagini chiamate/minuto chiamate chiamate/minuto
I 400
I Invio dati all'API 1 gigabytes 5 megabytes/minuto 560 gigabytes
P megabytes/minuto
M
U
A 300
L
G
A
Ricezione dati dall'API 5 gigabytes 28 megabytes/minuto 427 gigabytes
E
megabytes/minuto
T
I 2,500,000 14,000 47,000,000 32,000
O Esecuzione trasformazione
N
trasf ormazioni trasf ormazioni/minuto trasf ormazioni trasf ormazioni/minuto
M 48,000 108,000
E Chiamate all'API Memcache 8,600,000 96,000,000
M chiamate/minuto chiamate/minuto
C 128
A Dati inviati all'API 10 gigabytes 56 megabytes/minuto 60 gigabytes
megabytes/minuto
C
H 284 640
E
Data ricevuti dall'API 50 gigabytes 315 gigabytes
megabytes/minuto megabytes/minuto
Fig.2-5. Tabella riassuntiva delle caratteristiche offerte e monitorizzate da GAE
L’idea fondo è all’incirca la stessa dei cellulari prepagati. Esistono due tipi di “abbonamento”
o profilo quello “Free” (o gratis) e quello “Billing” (o a pagamento). Il profilo gratis è
associato per default ad ogni account.
Se le risorse consumate dall’utente sono inferiori a quelle previste per il profilo free l’utente
non paga nulla, altrimenti, se supera il limite, va in “burst” e cambia automaticamente
profilo e passa a quello billing. Chiaramente esiste un metodo per controllare la tariffazione
Studio ed analisi del Cloud Computing - 17 - Stumpo ElvioCapitolo 2 Analisi sulle offerte cloud delle risorse addizionali ed è accessibile anche all’utente: Google Checkout. Esso indirizza l’utente al Max Daily Budget il quale può configurare e controllare le somme stanziate per le singole risorse addizionali che l’utente è disposto “ad acquistare” ogni giorno. Configurando il Max Daily Budget su valori ben precisi, si ottiene un tetto massimo di spesa. Raggiunto tale valore, le applicazioni vengono bloccate. Anche in questo caso vale il paradigma “pay-for use” vale a dire che è addebitata solo la risorsa che effettivamente viene consumata. 2.3.4-Ulteriori dettagli Un sistema rigido come la Rete GAE comporta anche diversi limiti. Non si tratta, infatti, di un prodotto completamente nuovo: la piattaforma, infatti, è la stessa alla base di molti attuali servizi di casa Google, come Google Earth, Google Sites, o Google Finance e al suo interno integra una serie di applicazioni e funzionalità che Google utilizza già da tempo in tutto il mondo. Google ha comunque espresso la volontà di migliorare le potenzialità del proprio servizio cloud. Attualmente Google è in continua ricerca di soci validi per il progetto cloud, aziende del settore interessate (si è appena associata ad Salesforce), o singoli utenti e/o sviluppatori disposti a testare ed eventualmente migliorare i servizi forniti dalla rete. Il sistema GAE è ancora in fase di studio ed è offerto a tutti nella versione previous release che permette ai team tecnici un continuo testing real-time del prodotto e quindi l’individuazione delle carenze dell’architettura stessa. 2.4-EC2 Amazon Elastic Compute Cloud (noto anche come "EC2") è un servizio web che permette ai clienti di noleggiare computer su cui eseguire le proprie applicazioni informatiche. EC2 consente, tramite un processo completamente scalabile, la realizzazione di applicazioni web, fornendo servizi di interfaccia attraverso cui i clienti possono richiedere un numero arbitrario di macchine virtuali, vale a dire istanze del server su cui si può caricare qualsiasi tipo di software. Amazon Elastic Compute Cloud, inoltre, ha la capacità di ridimensionare il proprio carico di lavoro in nubi di calcolo. L’obiettivo del cloud di Amazon è quello di fornire applicazioni software sempre più semplici ed intuitive, sia dal lato utente che dal lato sviluppatore. Esso, infatti, fornisce il controllo completo delle risorse di elaborazione e consente di eseguire le istanze direttamente su Amazon. L’EC2 riduce il tempo richiesto per ottenere le istanze; tale condizione permette una rapida scalabilità delle capacità, sia verso l’alto che verso il basso, in funzione del comportamento dell’utilizzatore. Attualmente gli utenti possono creare, avviare e chiudere le istanze del server in maniera del tutto autonoma, da qui il termine "elastico”. Amazon.com prevede che EC2 sarà uno dei suoi numerosi servizi web, commercializzato con il termine Amazon Web Services (AWS); infatti EC2 è diventato disponibile al pubblico il 23 ottobre 2008 con il supporto per Microsoft Windows Server. Studio ed analisi del Cloud Computing - 18 - Stumpo Elvio
Capitolo 2 Analisi sulle offerte cloud
2.4.1-Funzionalità Amazon EC2
Amazon EC2 presenta un vero e proprio ambiente virtuale che consente di utilizzare le
interfacce di servizi web per lanciare le istanze sotto una varietà di sistemi operativi,
impiegando per ogni ambiente applicazioni specifiche.
Per utilizzare Amazon EC2, basta semplicemente:
• Creare un Amazon Machine Image (AMI), che contenga le applicazioni, le librerie, i
dati e le impostazioni di configurazione, o in alternativa, caricare una macchina
virtuale già pre-configurata per ottenere una AMI che sia immediatamente
funzionante.
• Caricare l'AMI in Amazon S3. EC2 fornisce gli strumenti che rendono semplice la
memorizzazione della stessa. Amazon S3 fornisce un sicuro, affidabile e veloce
“magazzino” per memorizzare le “immagini”.
• Utilizzare il servizio web di Amazon EC2 per la configurazione della sicurezza e
l’accesso alla rete.
• Scegliere il tipo di istanze da utilizzare, il sistema operativo che si desidera, poi farle
eseguire (lancio istanza - termino istanza); controllare il numero di istanze dell’AMI
utilizzando, se necessario, il servizio Web API o altri strumenti di gestione.
• Stabilire se si desidera eseguire le istanze in locazioni multiple (IP statico endpoints,
o l’attach persistent block storage).
• Pagare solo le risorse che si consumano effettivamente, come ad esempio, il tempo
o il trasferimento di dati.
2.4.2-Servizi highlights
Elasticità - Amazon EC2 consente di aumentare o diminuire la capacità di calcolo nel giro di
pochi minuti, non in ore o in giorni. È possibile utilizzare centinaia o addirittura migliaia di
server contemporaneamente. Questo perché tutto è sotto controllo mediante le API del
servizio Web. Le applicazione degli utenti si possono scalare in maniera del tutto automatica,
sia verso l’alto che verso il basso, a seconda delle esigenze.
Completamente controllata – L’utente ha il completo controllo delle sue istanze. Ha accesso
come root per ciascuna di esse, e può interagire con loro come si farebbe con qualsiasi
macchina. Le istanze possono essere riavviate in remoto usando le API del servizio web. Si
può anche ottenere un accesso alla console di uscita delle proprie istanze.
Flessibilità – L’utente può scegliere tra varie tipologie di istanze, ha a disposizione vari
sistemi operativi e pacchetti software. Amazon EC2 consente di selezionare una
configurazione di memoria, di CPU, e della migliore istanza di archiviazione possibile, in
funzione della scelta del sistema operativo e delle applicazioni. Ad esempio, la scelta di
sistemi operativi comprende numerose distribuzioni di Linux, di Microsoft Windows Server e
di OpenSolaris.
Integrazione - Amazon EC2 è progettato anche per l’utilizzo con altri Amazon Web Services.
Esso, infatti, lavora in collaborazione con Amazon Simple Storage Service (Amazon S3),
Amazon SimpleDB e Amazon Simple Queue Service (Amazon SQS) per fornire una soluzione
completa per il calcolo, l'elaborazione e l'archiviazione di ricerca in una vasta gamma di
applicazioni.
Studio ed analisi del Cloud Computing - 19 - Stumpo ElvioPuoi anche leggere

















































