Statistica & Informatica - A.A. 2020-21 CDL CTF - Moodle@Units
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
CDL CTF Statistica & Informatica gbarbati@units.it A.A. 2020-21

Correlazione Indice di Correlazione (variabili su scala di misura numerica) Se si rilevano due caratteri in una popolazione su scala numerica e si è interessati a studiare l’associazione tra i due caratteri, la rappresentazione grafica usuale è lo scatter plot (diagramma cartesiano): Distribuzione su un campione di 252 maschi delle dimensioni del polso e del collo: si ipotizza che l’ampiezza del collo sia circa due volte quella del polso. Vogliamo definire un indice che quantifichi numericamente la associazione lineare tra due variabili su scala quantitativa.

Correlazione COEFFICIENTE DI CORRELAZIONE: Il coefficiente di correlazione tra X e Y si definisce come il rapporto tra la covarianza di X e Y divisa per il prodotto tra le rispettive deviazioni standard: Covx, y rX ,Y sx s y -1 < r < 1 ; non dipende dalla scala di misura di X e Y. r -> 1 : le due variabili sono associate positivamente, vanno nella stessa direzione; r -> -1 le due variabili sono associate negativamente, vanno in direzioni opposte; r -> 0 le due variabili non sono associate.
Correlazione Interpretare il coefficiente di correlazione : L’interpretazione del coefficiente di correlazione dipende fondamentalmente dalle caratteristiche della ricerca. Come regola di pratica utilità possono essere utili i seguenti suggerimenti (che valgono anche per il segno negativo): Esistono 2 versioni principali del coefficiente di correlazione: Pearson e Spearman. Il coefficiente di Spearman è da utilizzare quando una o entrambe le variabili sono asimmetriche oppure hanno una scala di misura discreta con pochi valori possibili (ad esempio dei punteggi ad un test) ed è più “robusto” quando vi siano dei valori anomali/estremi nella distribuzione delle variabili da correlare.
Correlazione Problema Inferenziale: come decidere se la correlazione è "significativamente diversa da zero"? Approccio: Prendere le parti dell'avvocato del diavolo…. partire dalla ipotesi nulla che la coppia di variabili sia non correlata (rXY = 0) e verificare se è sufficientemente screditata dai dati. ⇓ Per verificare se l'ipotesi nulla è screditata, si ha bisogno di una “distribuzione di riferimento” : la distribuzione di probabilità della statistica di test se fosse vera H0.
Correlazione La statistica di test che viene calcolata sui dati è una V.A. che si comporta (se fosse vera l’ipotesi nulla) come una t di Student con «n-2» gradi di libertà. La distribuzione t di Student è molto simile alla gaussiana. Ma cambia di forma in relazione alla numerosità n del campione: tende ad avvicinarsi alla distribuzione normale standard N(0,1), al crescere di n. Per n>30 le due distribuzioni sono indistinguibili. Per «gradi di libertà» della distribuzione si intende appunto questa dipendenza della forma della distribuzione dalla dimensione campionaria.
Correlazione Distribuzione di probabilità se fosse vera H0: non c’è correlazione fra le due variabili Sulla base della dimensione campionaria, ci saranno delle costanti t che delimiteranno le regioni di accettazione e di rifiuto della ipotesi nulla. Il software ci darà in output il valore della statistica di test ed il corrispondente «p-value»: Si «rigetta» H0 se il valore osservato di t è troppo poco probabile (se H0 fosse vera): p
Introduzione alla Retta di Regressione, con richiamo sulla parte di inferenza: Quando si studia una relazione causale tra due variabili quantitative, occorre definire: - una variabile esplicativa o indipendente o CAUSA - una variabile dipendente o risposta cioè un EFFETTO Consideriamo le seguenti coppie di variabili: - X= Peso; Y= Tasso di colesterolo; - X= Età (nei bambini tra 0 e 12 anni); Y= Statura (nei bambini tra 0 e 12 anni) - X= Dose di un farmaco; Y= "livello" di malattia/ tempo di guarigione. Quali sono le cause e quali gli effetti ? Si cerca di stimare una relazione tra X e Y tramite una funzione matematica: Y=f(X) In matematica, una funzione è una relazione tra due insiemi, che ad ogni elemento del primo insieme fa corrispondere uno e un solo elemento del secondo insieme.
Regressione Il termine ‘regressione’ è stato introdotto da Sir Francis Galton, antropologo inglese, nell’articolo “Regression towards mediocrity in hereditary stature” pubblicato nel Journal of the Anthropological Institute nel 1885. ‘Regressione’ si riferiva alla tendenza dei figli ad avere altezze più prossime alla media rispetto ai genitori. Galton voleva verificare se la statura dei figli potesse essere prevista sulla base di quella dei genitori. Ed esprimere questa corrispondenza in una legge matematica. Raccolse dei dati sull'altezza dei genitori (=X) e dei loro figli (=Y), e notò che padri alti avevano figli alti, ma più bassi dei rispettivi genitori, mentre padri bassi avevano figli bassi, ma tendenzialmente più alti dei loro padri. Galton chiamò questo fenomeno «regressione alla mediocrità», e il termine regressione venne poi applicato a tutte le analisi di questo tipo. a= intercetta della retta Y a X = pendenza angolare
Regressione Effetto della variazione del coefficiente Effetto della variazione del coefficiente a Il problema statistico è quello di determinare (stimare) i valori di a e , detti 'coefficienti di regressione', a partire dai valori di X e di Y osservati su un campione. Il metodo più comunemente usato per stimare i coefficienti di regressione è definito: metodo dei minimi quadrati (least squares). Il metodo consiste nel minimizzare rispetto alle incognite a e gli scarti al quadrato tra i valori osservati di Y e i valori 'teorici' di Y, cioè quelli che ci aspetteremmo di ottenere calcolandoli dai valori assunti da X, tramite l'equazione di regressione.
Regressione n min yi yˆ i 2 a ,b i 1 yˆ i a xi Si ottiene cosi’ l'equazione di una retta che "interpola" (=passa attraverso) la nuvola di punti osservati, in modo tale che la distanza media dei punti da questa retta sia minima.
Regressione
Esempio: valori di emoglobina ed età in 20 donne: Soggetto Hb (g/dl) età Hb 18 1 11.1 20 2 10.7 22 3 12.4 25 16 4 14 28 5 13.1 28 6 10.5 31 14 7 9.6 32 8 12.5 35 9 13.5 38 12 10 13.9 40 11 15.1 45 12 13.9 49 10 13 16.2 54 14 16.3 55 15 16.8 57 8 18 28 38 48 58 68 78 16 17.1 60 17 16.6 62 età 18 16.9 63 19 15.7 65 Vogliamo prevedere i valori di emoglobina al 20 16.5 67 crescere della età.
Retta di regressione: E(Hb)=a+*Età=8.24+0.13*Età Output di R: GLOSSARIO: 1. «E»= valore atteso della emoglobina al crescere dell’età; 2. quale è il significato dell’errore standard che viene riportato sui coefficienti ? 3. Test di ipotesi associato ai coefficienti di regressione…?
Regressione Retta di regressione: E(Hb)=a+*Età=8.24+0.13*Età Output di R: Il test di ipotesi viene effettuato su ogni coefficiente stimato per vedere se è significativamente diverso da zero: H0: beta=0 H1: beta≠0
DISEGNI DELLO STUDIO & MISURE DI RISCHIO
Stima di una misura di rischio (RCTs/studio osservazionale caso-controllo/coorte) MALATI SANI Totale ESPOSTI a b a+b NON ESPOSTI c d c+d Totale a+c b+d N Come quantificare l’associazione fra il fattore di esposizione e l’outcome ?
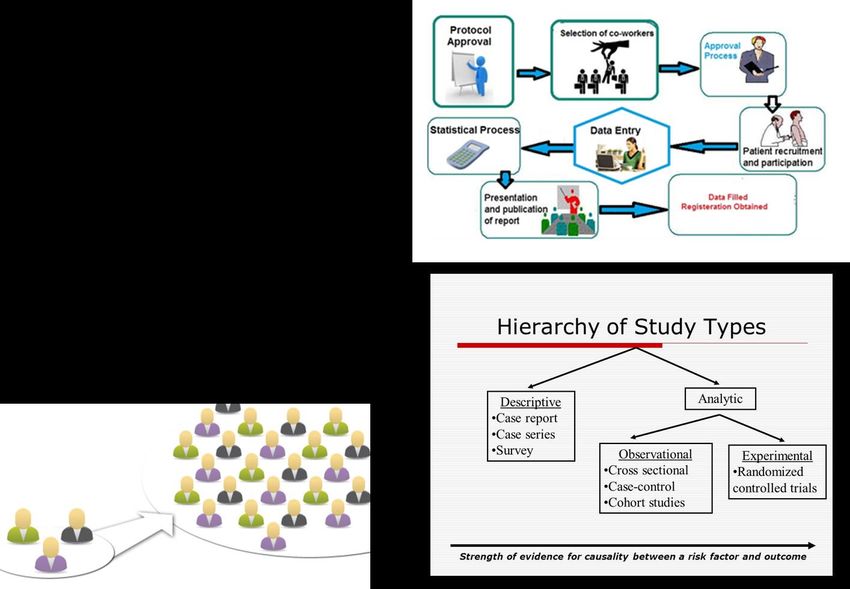
RCT: randomized controlled trial I gruppi di unità sperimentali a cui vengono assegnati i diversi trattamenti devono essere il più simili possibile, almeno negli aspetti più rilevanti per la sperimentazione… Soluzione (semplice) = randomizzazione
RCT RCT al “cuore” della implementazione di nuovi trattamenti: FASE I: “Sicurezza” di un principio farmacologico /trattamento. Piccoli campioni (20-80 pts). MTD= Massima Dose Tollerata su soggetti volontari sani/malati; cruciale il consenso informato. FASE II: “Esplorazione terapeutica” Campione di volontari con la malattia di interesse (100-300 pts). Valutazioni di farmaco-cinetica/dinamica, dose ottimale, frequenza delle dosi, protocolli di somministrazione, valutazione degli end-point di interesse. FASE III: “Efficacia comparativa” dimostrare/confermare l’efficacia di un trattamento e identificare eventuali effetti avversi nella pratica clinica (Campione “grande”: 500-3000 pts). FASE IV: “Sorveglianza Post-marketing” Studi osservazionali per identificare reazioni avverse meno frequenti (periodo più lungo); costo-efficacia nella popolazione “real world”. -> circa il 20% dei nuovi farmaci viene “integrato” da effetti collaterali in studi di fase IV; circa il 4% viene ritirato. Lasser KE et al., Timing of new black box warnings and withdrawals for prescription medications. JAMA. 2002; 287(17):2215–2220
Approfondimento TIPI DI RCT (FASE III) E=nuovo trattamento; C=standard Ipotesi «nulla» : (E-C)= =0 Ipotesi «alternativa»: (E-C)= ≠ ( eq Ipotesi «alternativa»: |E-C| ni Ipotesi «alternativa»: (E-C)= < ni E is “not (much) worse” than C
Ipotetica Tabella di contingenza a conclusione del Trial: MALATI SANI Totale TRATTATI a b a+b NON TRATTATI c d c+d Totale a+c b+d N Come quantificare l’associazione fra il trattamento e l’outcome ? (ipotizzando l’assenza di fattori di confondimento, analisi «univariata»)
Studi Osservazionali Studi Cross-sectional Studio osservazionale in cui l’esposizione e l’outcome sono determinati simultaneamente per ogni soggetto. Esposti Non esposti Dati raccolti nello stesso momento Malati Sani Malati Sani Utili per: - screening delle ipotesi sul quesito in studio, perché rapidi da realizzare; - valutazioni di prevalenza; - valutazioni di fattori associati all’outcome di interesse. Limiti: - Non c’è evidenza temporale di causa-effetto tra l’esposizione e l’outcome; - Outcomes prevalenti ma non incidenti, esclusi i soggetti deceduti prima dello studio: bias «long survivors»; - A causa della presenza di possibili confondenti bisogna valutare spiegazioni alternative alle associazioni osservate
Studi di coorte Retrospettivo Prospettico 2021 Esposti Non esposti 2012 2023 Malati Sani Malati Sani 2016 Si seguono nel tempo i soggetti esposti/non esposti per registrare l’incidenza dell’outcome di interesse. Utili quando: - C’è evidenza di una associazione tra esposizione ed outcome (es da precedenti studi cross-sectional); - L’intervallo temporale tra esposizione e outcome non è troppo lungo; - L’outcome non è troppo raro. Limiti: - Perdita al follow up; - A causa della presenza di possibili confondenti bisogna valutare spiegazioni alternative alle associazioni osservate; - Bias nella determinazione dell’outcome: non sono blinded!
Studi caso-controllo Esposti Non esposti Esposti Non esposti Malati Sani CASI CONTROLLI Gli studi caso-controllo selezionano dei soggetti con l’outcome di interesse (CASI) e li confrontano a soggetti senza (CONTROLLI) Utili quando: - L’outcome è raro; - C’è una ragionevole evidenza di una esposizione nel passato; Limiti: - «Recall/Interviewer bias»: i casi possono essere più precisi nel riferire sulla (passata) esposizione; - Difficile la selezione di controlli adeguati; - Se si utilizzano procedure di «matching» da valutare la generalizzabilità dei risultati; - Confondenti : bisogna valutare spiegazioni alternative alle associazioni osservate
Misure di Rischio: ODDS RATIO Come si fa a quantificare l'associazione eventualmente riscontrata, ossia a quantificare il rischio cui sono soggetti gli individui esposti negli studi di tipo caso-controllo ?? 1. In uno studio di tipo caso-controllo si selezionano i casi 3. Per comprendere questa misura, occorre introdurre il (=individui affetti) e i controlli (=individui non affetti) e poi si concetto di "odds" (termine che non ha un accerta quanti fra i casi (e quanti fra i controlli) sono stati corrispondente in italiano; può essere reso con esposti alla presunta causa. "probabilità a favore"). Gli odds sono rappresentati dal rapporto fra il numero di 2. Il metodo da utilizzare per la misurazione dell'associazione in volte in cui l'evento si verifica (o si è verificato) e il uno studio retrospettivo è il calcolo del cosiddetto «odds ratio numero di volte in cui l'evento non si verifica (o si è (OR)» o «rapporto degli odds» o «rapporto incrociato». verificato).
Misure di Rischio: ODDS RATIO Gli odds si utilizzano nel mondo delle scommesse, perché consentono allo scommettitore di calcolare facilmente la somma da incassare in caso di vittoria. Ad esempio, la vittoria della nazionale italiana di calcio nella semifinale Italia-Francia ai mondiali del 1998 era data dai bookmakers a 4:1 "a sfavore". Questo equivale a dire che, su una scala da 1 a 5, le probabilità di sconfitta (p) dell'Italia erano considerate 4 volte più alte di quelle di una sua vittoria (1-p), e quindi la vittoria dell'Italia sarebbe stata pagata 4 volte la cifra scommessa [per i curiosi: vinse la Francia 4-3 ai rigori…]. Gli odds si possono trasformare in probabilità: secondo i bookmakers, l'Italia aveva 1 probabilità su 5 (p=0.2) di vincere e 4 probabilità su 5 di perdere (p=0.8). Nota che: (p di perdere) = (1-p di vincere) e viceversa. L’odds è un rapporto fra due probabilità la cui somma è 1
Misure di Rischio: ODDS RATIO - Come si interpreta l’OR? - Come si calcola un intervallo di confidenza intorno all’OR?
Misure di Rischio: RISCHIO RELATIVO Come si fa a quantificare l'associazione eventualmente riscontrata, Diversamente da uno studio caso- ossia a quantificare il rischio cui sono soggetti gli individui esposti controllo, uno studio di coorte inizia negli studi di tipo coorte ?? suddividendo la popolazione in esposti e non esposti e poi osservando nel tempo quanti fra gli esposti (e quanti fra i non- esposti) si ammalano. Esiste una associazione fra allevamento dei vitelli in ricoveri chiusi (esposizione, o variabile indipendente) e la comparsa di polmonite (variabile dipendente)?? Si può calcolare il «rischio relativo (RR)»: il rapporto tra l'incidenza della malattia negli esposti e l'incidenza nei non esposti.
Misure di Rischio: RISCHIO RELATIVO - Come si interpreta RR? - Come si calcola un intervallo di confidenza intorno a RR?
Misure di Rischio: Interpretazione numerica L'interpretazione dei valori numerici è analoga sia che si tratti di valori di OR che di valori di RR. Entrambi possono assumere valori teorici compresi fra 0 e +infinito. È intuitivo che un valore =1 indica assenza di associazione tra malattia ed esposizione, in quanto: • per il rischio relativo: l'incidenza negli esposti è uguale all'incidenza nei non esposti; • per l’odds ratio: gli odds di esposizione nei casi sono uguali agli odds di esposizione nei controlli. Un valore 1 indica l'esistenza di una associazione positiva (il fattore può aumentare il rischio della malattia). Più i valori si discostano da 1, in un senso o nell'altro…, più l'associazione è forte.
Misure di Rischio: calcolo dell’intervallo di confidenza per RR Apgar score 7 Tot RR=[2/16]/[33/91]=0.345 Crescita fetale 2 14 16 Il rischio relativo di avere un basso score nel gruppo che presentava crescita simmetrica all’ecografia è il 35% rispetto al simmetrica (a) (b) (a+b) gruppo che presentava una crescita asimmetrica all’ecografia. Crescita fetale 33 58 91 asimmetrica (c) (d) (c+d) Per calcolare l’intervallo di confidenza di RR bisogna passare alla scala logaritmica: Tot 35 72 107 ෪ ~ log( ), (log ) log Lo score Apgar viene calcolato per valutare lo stato di salute di un neonato. I neonati con punteggio alla nascita inferiore a 4 sono gravemente depressi e 1 1 1 1 necessitano di intervento medico immediato, quelli con punteggio fra 4 e 6 sono ෪ log = − + − moderatamente "a rischio", bisognosi di assistenza, vigilanza e ripetizione del test + + ogni 5 minuti, i neonati con punteggio fra il 7 e il 10 sono considerati normali. 1 1 1 1 ෪ log = − + − = 0.676 log = log 0.345 = −1.065 2 16 33 91 log ± 1.96 ∗ log = −1.065 ± 1.96 ∗ 0.676 Notare che il 95% CI log 95% ∶ [−2.389; 0.259] RR 95% ∶ [exp(−2.389); exp(0.259)]=[0.091; 1.296] contiene 1… *Test di ipotesi su RR: Testare l’ipotesi nulla H0 : RR= 1 è equivalente ad effettuare un test di indipendenza in una tabella 2 × 2 (test Chi-quadrato). Nel nostro esempio, il Chi-quadrato ha un p value=0.08, quindi non c’è una evidenza sufficiente per rigettare l’ipotesi nulla.
Misure di Rischio: calcolo dell’intervallo di confidenza per OR Erosione Non erosione Tot OR=[32*127]/[118*17]=2.026 dentale dentale L’esposizione a 6+ ore di nuoto a settimana è circa due volte maggiore nel gruppo con erosione dello smalto dentale 6+ ore di nuoto 32 118 150 rispetto ai nuotatori senza erosione.
Puoi anche leggere

















































