CLUSTERING DI DOCUMENTI XML BASATO SU SELF-ORGANIZING MAPS
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
UNIVERSITA’ DEGLI STUDI DI SIENA
FACOLTA’ DI INGEGNERIA
Corso di Laurea Specialistica In Ingegneria Informatica
CLUSTERING DI DOCUMENTI XML
BASATO SU SELF-ORGANIZING MAPS
Relatore:
Dott. Franco Scarselli
Correlatore:
Dr. Markus Hagenbuchner
Tesi di Laurea di:
Francesca Trentini
Anno Accademico 2004 – 2005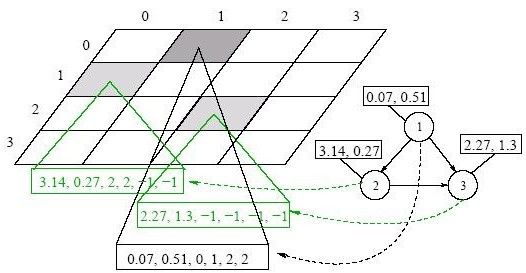
Indice
1 Introduzione 2
2 Self Organizing Maps 12
2.1 Mappe del cervello . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2 Apprendimento Competitivo . . . . . . . . . . . . . . . . . . . 13
2.3 SOM Standard . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.4 Una mappa di vettori binari . . . . . . . . . . . . . . . . . . . 20
2.5 Aspetti multipli di una SOM . . . . . . . . . . . . . . . . . . . 22
3 Algoritmi ricorsivi per l’elaborazione di strutture grafiche 24
3.1 Reti neurali ricorsive . . . . . . . . . . . . . . . . . . . . . . . 26
3.2 Dalle reti ricorsive alle SOM per strutture . . . . . . . . . . . 29
3.3 Apprendimento non supervisionato con SOM-SD . . . . . . . . 29
3.4 Un Modello di Mnode . . . . . . . . . . . . . . . . . . . . . . . 32
3.5 Algoritmo di apprendimento per Mnode . . . . . . . . . . . . . 34
3.6 Apprendimento non supervisionato con Contextual-SOM . . . 38
4 Risultati 40
4.1 Il Data Set . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.2 Introduzione agli approcci basati su feature . . . . . . . . . . . 41
4.3 Risultati K-Means . . . . . . . . . . . . . . . . . . . . . . . . 42
4.4 Misure delle Performance per algoritmi SOM-like . . . . . . . 44
4.5 Risultati Standard-SOM . . . . . . . . . . . . . . . . . . . . . 49
4.6 Estrazione di informazioni dalla collezione di documenti . . . . 54
4.7 Risultati SOM-SD . . . . . . . . . . . . . . . . . . . . . . . . 64
4.8 Risultati Contextual-SOM . . . . . . . . . . . . . . . . . . . . 76
5 Conclusioni e Sviluppi Futuri 81
Bibliografia 85
1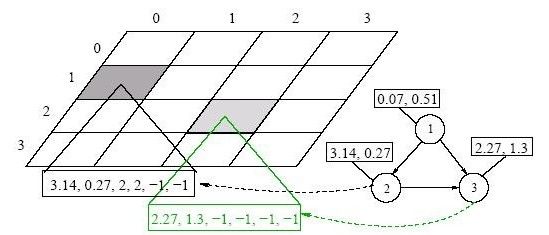
Capitolo 1
Introduzione
Le radici dell’Artificial Life possono essere rinvenute negli automi cellulari di
John Von Neumann e Arthur W. Burks. Nelle parole di Burks [33], che fu il
continuatore della sua opera, Von Neuman si chiedeva:
Quale tipo di organizzazione logica è sufficiente ad un automa per ripro-
durre se stesso? Questa domanda non è precisa ed ammette sia una risposta
banale che una interessante. Von Neuman aveva in mente il fenomeno natu-
rale dell’autoriproduzione quando la pose, ma non tentò di simulare l’autori-
produzione di un sistema naturale a livello genetico e biochimico. Egli voleva
astrarre dal problema naturale dell’autoriproduzione la sua forma logica.
Il formalismo che permise la realizzazione di un tale sistema, fu proposto
da un suo collega, Stan Ulam, con il nome di Automa Cellulare [34]. Un
automa cellulare è semplicemente un sistema che può avere un numero finito
di stati ed il cui stato è determinato dallo stato di altri automi che lo circon-
dano. Il comportamento degli automi cellulari diventa interessante proprio
perché formano una rete di interazioni, il cui comportamento globale, nel
tempo, non è prevedibile; anche se le leggi che governano i passaggi di stato
per ogni singolo automa sono semplici e ben determinate. Lo stato di ogni
automa di questa rete, in ogni istante di tempo, è determinato dallo stato
posseduto, nell’istante precedente, dagli automi che lo circondano. Con gli
automi cellulari, Von Neumann impostò un sistema capace di autoreplicar-
si e stabilı̀ che, qualunque sistema capace di fare ciò, doveva fare uso delle
informazioni contenute nella sua descrizione in due modi fondamentalmente
differenti: sia interpretando, che non interpretando. Interpretate le informa-
zioni dovevano tradursi in azioni da compiere per realizzare il replicante, non
interpretate dovevano essere soltanto copiate, perché sarebbero state l’analo-
ga descrizione per il replicante. Quando, in seguito, si scoprı̀ la struttura ed
il funzionamento del DNA emerse che erano proprio i modi in cui la cellula fa
uso delle informazioni contenute in esso durante i suoi processi di trascrizione
2
e traduzione da una parte e replicazione dall’altra.
Fino agli anni ottanta possiamo dire che l’unico filone di ricerca sull’ar-
tificial life è stato questo degli automi cellulari. In seguito si è avuto quel-
l’interesse convergente in questo campo da vari ambiti. Proprio per unificare
gli sforzi e fare il punto della situazione, nel settembre del 1987 si è tenuta
a Santa Fe la prima conferenza sull’Artificial Life: International Conference
on the Simulation and Synthesis of Living Systems (che è considerata l’atto
di nascita ufficiale di questa nuova scienza), organizzata da Chris Langton
del Santa Fe Institute. Ad essa parteciparono non solo scienziati che, con
vari approcci, lavoravano alla costruzione di robot, o scienziati cognitivi, ma
anche filosofi, chimici e biologi. In seguito si è tentato di definire meglio le
competenze dell’ Artificial Life e di formalizzarne i confini e gli ambiti. Si
sono avute altre conferenze negli Stati Uniti ed in Europa, oltre a sempre più
frequenti pubblicazioni.
Oggi possiamo distinguere due grossi filoni che si intrecciano tra loro:
quello della robotica e quello delle simulazioni.
Un altro tipo di distinzione che si può fare, che è in realtà molto più pro-
fonda e destinata ad approfondirsi, è tra gli approcci che potremmo definire
top-down, quali quelli della tradizione cognitiva o dell’Intelligenza Artificiale,
e quelli bottom-up nel quale troviamo connessionismo (in particolare il filone
degli agenti situati) e automi cellulari.
Vi sono, ovviamente, anche molti tentativi di integrare le due strategie.
Riguardo alla prima distinzione Rodney Brooks (che è uno dei più autorevoli
ricercatore nel campo della robotica) insiste sulla difficoltà di trasportare ap-
prendimenti e tecniche dalle simulazioni al mondo reale [35], ma fa riferimento
soprattutto a ricerche che utilizzano il classico procedimento dell’Intelligenza
artificiale. Al contrario suggerisce tecniche che utilizzano gli algoritmi ge-
netici perché si abbiano apprendimenti trasferibili dal simulato al reale. Un
automa deve apprendere ad agire in un ambiente e, in linea di principio,
non fa molta differenza se questo ambiente è reale o simulato. L’ambiente
simulato, però, non deve essere stato progettato in modo da rendere il più
semplice possibile la vita all’automa. Questa semplificazione spesso finisce
per rendere ancora più difficile operare in tale ambiente. Ciò è legato al
fatto che quello che è riportato dai sensori, nella vita reale, è sempre molto
incerto. Quell’imprecisione che, a prima vista, sembrerebbe un problema, in
realtà porta ad apprendimenti più flessibili in partenza; fa si che non si crei-
no conflitti di precedenza artificiali come in alcune simulazioni e soprattutto
porta in maniera più naturale a prendere il punto di vista del robot, invece
di fornirgli la propria visione dell’ambiente. Questa è appunto la posizione
fondamentale del filone che va sotto il nome di agenti situati.
Per quanto riguarda l’apprendimento, possiamo distinguere un apprendi-
3
mento genetico ed uno individuale, proprio come negli esseri viventi reali.
In genere oggi si tende ad utilizzare o l’uno o l’altro, ma con un uso
integrato di entrambe le forme di apprendimento si potrà fare, tra l’altro,
ulteriore chiarezza su una questione che nel passato ha riempito molte pagi-
ne: quanta parte del comportamento di un organismo è attribuibile al suo
patrimonio genetico e quanto all’apprendimento nella sua vita. La questione
ormai ha raggiunto un sufficiente grado di chiarezza con il riconoscimento
del contributo integrato di entrambe le componenti, ma si ripropone ogni
volta la proporzione e, soprattutto, la natura delle predisposizioni genetiche
quando si parla di comportamenti o di attività mentali.
Nelle simulazioni che si fanno in questo campo, si utilizzano in genere al-
ternativamente strategie che possiamo considerare ispirate all’apprendimento
in vita (tramite backpropagation principalmente, ma anche con l’apprendi-
mento competitivo, con la regola di Hopfield, o comunque apprendimenti
basati sulla modifica dei valori delle connessioni tra neuroni); oppure all’ap-
prendimento su base genetica, che si compie di generazione in generazione
(algoritmi genetici).
Ultimamente si sta diffondendo enormemente soprattutto l’uso di que-
sta ultima strategia. Ciò è logico, se si considera, al di là di un’analisi più
circostanziata, che, in questa fase iniziale, potrebbe essere una buona stra-
tegia, quella di lasciare sviluppare le specie più adatte ai vari scopi che si
propongono i diversi ricercatori. E’ comunque auspicabile che si arrivi presto
all’utilizzo complementare di ambedue la strategie come fa notare [36]:
”vi è un intreccio costante fin dalla embriogenesi del sistema nervoso tra
conoscenze
provenienti dall’esterno e
conoscenze
contenute nel codice
genetico, e non si può ignorare il ruolo di nessuna di queste due fonti se si
vuole capire in che modo si sviluppa, funziona, apprende e raggiunga certe
prestazioni il cervello di un certo individuo o di una certa specie.”
Gli algoritmi genetici consistono fondamentalmente in varie tecniche, che
portano alla selezione degli algoritmi che danno (in base ad un determina-
to criterio) i risultati migliori ed alla ricombinazione casuale di alcune loro
porzioni e/o alla mutazione di alcune loro parti.
In genere si parte con una certa popolazione di automi che hanno leggere
differenze tra loro e si fanno agire in un ambiente per un certo numero di cicli.
In seguito quelli che si saranno comportati meglio avranno la possibilità di
riprodursi. Cioè si prenderà, ad esempio, il venti per cento della popolazione
che si è comportato nel modo migliore e da questi, con mutazioni casuali
e ricombinazioni, si otterrà anche il restante ottanta per cento di automi;
con questa nuova popolazione si farà un altra sessione di cicli, al termine
dei quali, si ripeterà lo stesso procedimento. All’interno di questo schema
4generale, le effettive realizzazioni degli algoritmi possono essere molto diverse:
da programmi in vari linguaggi, a valori di connessioni di reti neurali.
L’apprendimento ontogenetico, invece, può utilizzare varie strategie per
la modifica delle connessioni, sia con un supervisore che senza.
Nell’apprendimento supervisionato, lo sperimentatore (o una memoria
di tipo statico), in caso di risposta diversa da quella ritenuta più opportu-
na, fornisce la risposta desiderata, mentre nelle strategie di apprendimento
non supervisionato, è la rete stessa che propone le risposte e modifica le
connessioni.
Anche se abbiamo diversi tipi di reti che possono apprendere (che si ri-
fanno a tutte le principali teorie dell’apprendimento comportamentiste: dalla
legge dell’effetto di Thorndike, a quella della contiguità temporale di Gu-
thrie), quelle che effettivamente si sono rivelate adatte, a far apprendere
ad un automa senza supervisore un certo compito, sono quelle basate sulla
backpropagation e sull’apprendimento competitivo.
Bisogna considerare che, in questi primi tentativi di realizzare automi in
grado di modificare il proprio comportamento in modo da ottimizzare un
certo risultato, l’importanza che hanno i metodi di apprendimento effettiva-
mente utilizzati è molto relativa. Infatti possiamo ottenere risultati piuttosto
simili, sia utilizzando una strategia filogenetica, come gli algoritmi genetici,
che una ontogenetica, come la modifica delle connessioni in base al risultato
delle azioni. Quello che effettivamente si sta sperimentando, non sono tanto
queste teorie parziali dall’apprendimento, quanto proprio la strategia globale
di organizzazione del proprio comportamento da parte di questi sistemi.
Queste limitazioni vengono però superate se si aggiunge almeno un altro
strato tra quello di ingresso e quello di uscita. Una rete a tre o più strati
può classificare in qualunque modo si voglia, si dimostra infatti essere un
interpolatore universale. Ma una regola per la modifica dei coefficienti di
connessione, in questi casi in cui gli strati sono più di due, è stata propo-
sta solo nel 1986 in [37] da Rumelhart, Hinton e Williams. La regola è la
celeberrima error backpropagation, consistente, appunto, nella propagazione
dell’errore a ritroso. Vengono prima modificati i coefficienti delle connessioni
tra il penultimo e l’ultimo strato e poi si risale, di strato in strato, fino a
modificare quelli delle connessioni tra il primo ed il secondo strato.
Data la possibilità di far apprendere ad una rete a tre o più strati qua-
lunque tipo di associazione, o criterio di categorizzazione, oggi reti di questo
tipo sono molto usate nei campi più disparati.
Un difetto di queste reti è l’enorme mole di calcoli che devono essere fatti,
in fase di apprendimento, dopo la presentazione di ogni stimolo, prima che
la rete converga verso un valore dei coefficienti relativamente definitivo. Tra
l’altro non è detto che questi valori siano i migliori possibili in assoluto, po-
5trebbe trattarsi, infatti, di un minimo locale. In altre parole la regola della
backpropagation è fatta in modo da far diminuire, dopo ogni iterazione, la
differenza che, a livello di connessioni, si ha tra l’uscita prodotta e quella
voluta; ma ciò non garantisce che si ottengano i valori migliori in assoluto.
Questo progressivo approssimarsi a dei valori delle connessioni che ottimizza-
no l’errore, potrebbero portare a delle connessioni che non danno il migliore
compromesso possibile in modo da ottenere, in tutti i casi memorizzati fino
a quel momento, la migliore combinazione possibile di risposte.
Questo pericolo è particolarmente concreto nel caso di utilizzo di que-
ste reti nel modo più naturale, detto on line, cioè quando le modifiche alle
connessioni sono apportate dopo ogni iterazione. L’altro metodo (batch) pre-
vede, invece, il solo calcolo delle variazioni dei coefficienti, finché non è stato
presentato l’intero set di rappresentazioni che la rete deve apprendere, è solo
a questo punto che le connessioni vengono effettivamente modificate.
Sono state proposte anche delle modifiche alla regola di Rumelhart, Hin-
ton e Williams che permettono una convergenza più veloce, con un minor
numero di iterazioni, come la quickpropagation [38], ma non è ancora stato
risolto il problema di evitare di cadere nei minimi locali.
Nello stesso anno in cui è stata trovata una regola di apprendimento per
le reti a più strati è stata pubblicata anche una raccolta di articoli sulle
reti neurali [39]. In essa è presentata come un fatto avvenuto la nascita
di un nuovo paradigma di ricerca basato sulle possibilità dell’elaborazione
subsimbolica e parallela.
Sia per la pubblicazione di questa antologia che per la backpropagation,
dopo il 1986 c’è stata una grande ripresa degli studi e pubblicazioni sulle
reti neurali. Nello stesso tempo, si sono moltiplicate anche le utilizzazioni
pratiche delle reti (in particolare proprio della backpropagation). Esse si uti-
lizzano oggi nell’interpretazione di segnali radar e sonar, nel riconoscimento
della voce, nel riconoscimento della scrittura naturale, nella visione artificiale,
nella robotica, per risolvere vari problemi di ottimizzazione.
Vi sono anche altre soluzioni, al problema di modificare le connessioni di
reti multistrato in modo tale che si abbia apprendimento. Tali reti utilizzano
vari tipi di apprendimento competitivo ed hanno appunto in comune il fatto
di aumentare i valori dei coefficienti di connessione eccitatori associati alle
linee che, dallo strato immediatamente inferiore, inviano segnali alle unità che
hanno vinto la competizione [40]. Queste reti hanno connessioni eccitatorie
con le unità dello strato superiore e connessioni di tipo inibitorio tra unità
che appartengono allo stesso strato.
Le più utilizzate realizzazioni di questo principio, prevedono uno dei
seguenti criteri per la propagazione del segnale:
61. La strategia con più vincitori. Si fa una media delle somme pesate
degli ingressi ad ogni neurone ed emettono un’uscita solo quelle che in
cui essa è superiore alla media.
2. La strategia Winner Takes All. In questo caso emette un’uscita
solo l’unità che ha la più alta somma pesata degli ingressi.
3. Le strategie a bolla. In queste si immaginano i neuroni disposti su
una griglia, in modo tale che ci siano vicinanze e distanze tra i vari
elementi. Le unità che si considerano vincenti sono tutte quelle che si
trovano in un opportuno intorno spaziale di quella che ha ottenuto la
più alta somma pesata degli ingressi. La prima è stata proposta da
Kohonen, ma in seguito egli stesso ed altri ne hanno proposte molte
diverse versioni.
In seguito vengono modificati i coefficienti delle unità vincitrici o, in alcuni
casi, anche di quelle che non hanno vinto la competizione.
Parallelamente a queste linee di ricerca, lo studio delle possibilità delle
reti neurali, si è sviluppato in altre direzioni. Oltre a reti a strati, in cui uno
strato ha funzioni di input ed un altro di output, ce ne sono molti altri tipi
composti da un solo strato ed altri aventi architetture più complesse.
Tradizionalmente quando si parla di apprendimento automatico lo si in-
tende riferito a dati rappresentati in un qualche spazio vettoriale, tuttavia
in un ampio numero di contesti applicativi i problemi vengono modellati in
maniera molto più naturale se possiamo a far ricorso a strutture grafiche.
L’interazione tra milioni di molecole che rende possibile la vita di un or-
ganismo, le relazioni tra individui che formano la società, le fluttuazioni dei
mercati, che generano o distruggono ricchezza nell’arco di minuti, la diffu-
sione delle malattie in una comunità, l’architettura delle reti di calcolatori...
potremmo continuare per pagine e pagine elencando innumerevoli esempi di
problemi apparentemente scorrelati, che sono oggetto di studio da parte di
discipline tanto diverse tra di loro; tuttavia riflettendo con maggiore atten-
zione si può cogliere una caratteristica che accomuna scenari tanto diversi: la
possibilità di modellare tale problemi in termini di grafi. Naturalmente, da
caso a caso, la natura dei nodi, degli archi e la semantica delle relazioni tra
oggetti verrà adattata al contesto specifico in cui ci troviamo. Per esempio
nel grafo delle relazioni sociali gli individui potrebbero essere rappresentati
come nodi tra i cui si instaura una connessione se due persone si conoscono
oppure, volendo modellare la rete elettrica di una nazione, avremo una strut-
tura i cui nodi saranno generatori, trasformatori e sottostazioni connessi da
archi qualora esista fisicamente una linea di trasmissione ad alto voltaggio
7che li congiunge. Pescando alcuni dei tanti possibili esempi di sistemi che
possono essere facilmente pensati in termini di grafo possiamo citare:
• il Web (con le pagine e gli hyperlink);
• Internet (con computer, sottoreti e router collegati tra loro);
• la rete metabolica all’interno di una cellula;
• le reti formate dalle relazioni economiche e dalle operazioni finanziarie;
• la rete formata dagli articoli scientifici collegati tra di loro dalle cita-
zioni;
• la rete sottostante il linguaggio (dove i nodi sono parole e i collegamenti
le co-occorrenze significative nel testo o le relazioni semantiche);
• la modalità di diffusione dell’HIV tra soggetti;
• la rete sociale costituita dagli attori e dai film in cui hanno recitato;
• la rete delle rotte aeree commerciali.
• le catene alimentari.
Questi ed altri temi sono stati oggetto di studio da parte di numerosi grup-
pi di ricerca indipendenti costituiti in particolare da chimici, fisici, informati-
ci, sociologi, biologi, medici, economisti che, lavorando ognuno all’interno del
proprio specifico campo, hanno scoperto come i modelli grafici adottati per
studiare problemi tanto diversi presentassero proprietà sorprendentemente
affini.
Disporre di strumenti adeguati al fine di fare apprendimento automatico
su domini strutturati è stato l’obiettivo di gran parte della ricerca nel settore
a partire dai primi anni novanta. Inizialmente l’attenzione dei ricercatori
si è rivolta verso una particolare categoria di struttura grafica, ovvero la
sequenza. Nel caso di sequenze (o per meglio dire di serie storiche) i nodi
contengono i valori delle variabili considerate prese in un certo istante di tem-
po e gli archi, tipicamente diretti, colgono la relazione di causalità (definendo
successore e predecessore rispetto ad un riferimento temporale). In tempi più
recenti, l’attenzione si è spostata verso strutture grafiche propriamente dette,
in particolare alberi, che ben si adattavano a modellare relazioni gerarchiche
tra entità.
Nella sua accezione più ampia, l’elaborazione adattiva di dati strutturati,
si è negli ultimi anni dotata di strumenti adeguati a modellare relazioni tra
8entità di natura anche non gerarchica. Dunque se eseguiamo attentamente gli
ultimi quindici anni di evoluzione di apprendimento automatico su strutture,
noteremo un progressivo aumento della complessità dei problemi trattati e
dei modelli adottati con conseguente rilassamento dei vincoli posti alle classi
dei modelli apprendibili. Vediamo passare davanti a noi prima le sequenze
temporali poi le varie categorie di alberi infine, ancora attraverso la rimozione
dei limiti imposti, classi sempre più generiche di grafi.
La parte di storia in cui si inserisce anche il presente contributo è sta-
ta determinata dal contributo di ricercatori in diversi sottocampi affini tra
cui tanto per citarne alcuni in ordine sparso troviamo la predizione di serie
storiche, la inductive logic programming, e la computer vision, senza con-
tare il fondamentale apporto dovuto a ricercatori la cui formazione si può
inquadrare nell’ambito dello studio dei sistemi dinamici non lineari.
Proprio da quest’ultimo settore ci arrivano tra il 1997 ed il 1998 i fon-
damentali lavori di Frasconi, Gori, Sperduti, e Starita ([25], [24]) sulle reti
neurali ricorsive.
Nelle reti neurali ricorsive si associa un insieme di stati ai nodi del gra-
fo, a questo punto gli stati vengono dinamicamente aggiornati in base alle
relazioni topologiche esistenti tra nodi, infine le uscite della funzione verran-
no calcolate usando le codifiche memorizzate negli stati. Sfortunatamente le
reti ricorsive possono elaborare unicamente grafi diretti e aciclici e possono
applicarsi solo al problema focalizzato sul grafo, cioè τ (G, n) deve essere in
realtà indipendente da n.
Nel 2005 sono usciti due articoli [44], [45] sono usciti due articoli in cui si
mostra come adattare le reti ricorsive per elaborare anche alcuni grafi ciclici
e per problemi focalizzati sui nodi, ma questo solo passando attraverso un
riprocessamento degli ingressi. Altri approcci al problema sono basati sulle
catene di Markov, come viene fatto nei lavori di Brin e Page [42] e Kleinberg
[43], in questo caso si calcola la firma caratteristica di ogni nodo del grafo
applicando iterativamente la matrice delle probabilità di transizione tra i
vari nodi fino ad arrivare a convergenza. Recentemente Gori, Hagenbuchner,
Scarselli e Tsoi hanno proposto un nuovo modello chiamato graph neural
network che combina ed estende sia l’approccio orientato alle reti ricorsive
che quello basato sulle catene di Markov. Il nuovo framework è molto più
generale e permette di apprendere funzioni τ (G, n) di qualunque tipo su
qualsiasi tipo di grafo (diretto, indiretto, ciclico...) senza effettuare alcun tipo
di pre-elaborazione sugli ingressi. Una graph neural network è caratterizzata
da due funzioni f e g, la funzione di transizione f viene utilizzata per calcolare
lo stato di un nodo del grafo in dipendenza da eventuali etichette associate
al nodo stesso e ai suoi diretti vicini e allo stato dei nodi vicini, mentre g
restituisce una uscita dipendente dallo stato del nodo a cui si applica e dalla
9sua etichetta. Affinchè l’uscita prodotta da g sia consistente occorre prima
iterare la funzione f finchè gli stati dei nodi non convergono ad un valore,
perchè questo sia possibile la f dovrà essere una contrazione (in tal caso il
teorema del punto fisso di Banach ci assicura che il sistema converge verso un
punto e che questo è unico). Sia f che g saranno funzioni con dei parametri
liberi che (potrebbero essere anche entrambi reti neurali) in modo che la
funzione τ (G, n) (che quindi dipende da f e da g) possa essere appresa da
esempi.
A differenza di quel che è stato tradizionalmente fatto con le reti neurali
ricorsive, le graph neural network possono applicarsi a grafi reali che mo-
dellano reti complesse e possono presentare qualunque topologia. In questo
nuovo scenario ci troviamo a lasciare progressivamente un terreno in cui le
strutture trattate potevano essere considerate, con una buona approssima-
zione, dei random graph, e ci avventuriamo in un mondo in cui la regola
diventano i grafi scale-free ovvero di reti in cui, indipendentemente dalla
grandezza del grafo considerato, la distribuzione di probabilità dell’ordine di
ogni suo nodo si mantiene invariata e si può approssimare ad una power-law.
Dovrebbe apparire evidente come non sia affatto scontato che apprendere su
queste strutture sia analogo ad apprendere sui random graph, al momento
non esistono, che io sappia, studi sistematici sull’argomento. Ci troviamo
su un terreno in buona parte inesplorato in cui si aprono diversi interessanti
questioni, ad esempio occorrerà studiare metodologie per poter formulare i
problemi in contesti in cui le relazioni tra oggetti assumono un valore ine-
dito e definire linee guida per il progettista/sperimentatore che si trovi a
dover opportunamente costruire gli insiemi di esempi su cui far apprendere
le graph neural network, inoltre dovremo considerare gli effetti che può avere
sull’addestramento la presenza degli hub, ovvero di nodi con un alto numero
di connessioni col resto del grafo, e più in generale il fatto che la connettività
segua una power-law.
Sul fronte dell’apprendimento non supervisionato è stato proposto nel
2003 il primo modello completamente non supervisionato per elaborare grafi
aciclici diretti non etichettati attraverso un’estensione delle originali Self Or-
ganizing Map. Il modello proposto chiamato self organizing map for adaptive
processing of stuctured data (SOM-SD) [27]. L’estensione si ottiene attraver-
so la procedura di ”srotolamento”analoga a quella adottata nelle reti neurali
ricorrenti e ricorsive con i neuroni replicati nella rete srotolata che consistono
in un intera SOM. Questo approccio rende possibile la scoperta delle somi-
glianze tra oggetti compresi vettori di dati numerici e strutture. Le capacità
del modello sono analizzate in dettaglio utilizzando un ampio data set che
include immagini codificate come grafi aciclici diretti etichettati. I risultati
sperimentali hanno mostrato chiaramente che il modello proposto è capace di
10sfruttare sia l’informazione contenuta nelle etichette abbinate ad ogni nodo
che l’informazione contenuta nella topologia del grafo.
Nei lavori successivi gli autori hanno rimosso uno dei maggiori ostacoli
delle SOM-SD includendo anche le informazioni contestuali relative ad un no-
do in un dominio di dati strutturati graficamente, in particolare la necessità
di elaborare i dati utilizzando più livelli di una self organizing map attra-
verso l’utilizzo di una sola mappa riducendo perciò la complessità computa-
zionale. Nelle Contextual Self-Organizing [28] viene reso possibile elaborare
direttamente grafi ciclici, non-diretti.
In questo lavoro di tesi vengono applicate self organizing map, SOM-
SD, CSOM-SD, al clustering di documenti XML. In particolare il capitolo
2 descrive i metodi classici di apprendimento competitivo e in particolare
l’algoritmo Self Organizing maps, il capitolo 3 descrive metodi ricorsivi per
l’elaborazione di strutture grafiche supervisionati (reti neurali ricorsive) e
non supervisionati (SOM-SD e CSOM-SD).
Il capitolo 4 presenta la valutazione sperimentale sul data set proposto su-
gli algoritmi analizzati, evidenziando le proprietà connesse all’estrapolazione
di informazione strutturata ed infine nel capitolo 5 riepiloghiamo le consi-
derazioni discusse nel resto del lavoro e, dopo aver evidenziato le criticità
peculiari del problema in esame e degli algoritmi adottati proponiamo ade-
guate modifiche sia in termini di modellazione del problema che di filtraggio
volte ad individuare un trade off ottimale tra accuratezza e prestazioni.
11Capitolo 2
Self Organizing Maps
Le Self Organizing Maps (SOM)[3] appartengono alla classe dei metodi di
apprendimento non supervisionato. Le SOM sono solitamente utilizzate per
la riduzione delle dimensioni di data set, possono identificare clusters locali
nel data set e organizarli globalmente. Le SOM si comportano come reti neu-
rali artificiali, le celle delle quali si specializzano per vari pattern di input o
classi di input attraverso un processo di apprendimento non supervisionato.
Nella versione basilare delle SOM solamente una cella od un gruppo di celle
viene attivato dall’input corrente. La locazione spaziale o le coordinate di
una cella nella rete corrispondono ad un particolare dominio di pattern di
input. La Self Organizing Map è considerata una alternativa alle più tradi-
zionali reti neurali artificiali. Il processo di apprendimento sembra avvenire
in maniera molto naturale e i processi adattivi che incontriamo all’interno
della mappa presentano forti analogismi con quello che avviene all’interno del
cervello. Quindi vi sono sufficienti giustificazioni per chiamare queste mappe
reti neurali proprio come le loro tradizionali rivali. Le SOM consistono di
alcuni moduli di una mappa. Esse possono essere applicate a processi di pat-
tern recognition, processi di controllo, ed anche a processi con informazione
semantica.
2.1 Mappe del cervello
La neuropsicologia è la disciplina che studia le basi delle funzioni mentali.
Una delle prime proposte sulla localizzazione cerebrale delle facoltà mentali
risale al lavoro del fisiologo tedesco Franz Joseph Gall (1758-1828). Gall e i
suoi seguaci identificarono 37 facoltà mentali e morali che credevano essere
rappresentate sulla superficie esterna del cranio nella forma di una mappa.
Ovviamente questa mappa non aveva alcun fondamento scientifico e molte
12delle facoltà individuate (come ad esempio l’immortalità, la benevolenza, o la speranza) fanno oggi sorridere. Il metodo neurologico classico nasce invece nella seconda metà del XIX secolo dallo studio dei disturbi del linguaggio pro- dotti da una lesione celebrale. Alcuni grandi neurologi dell’epoca tentarono di stabilire una connessione tra lesioni di aree specifiche del cervello e disturbi afasici. Questo portò alle prime proposte di modelli anatomo-funzionali in cui il linguaggio veniva suddiviso in componenti separate che venivano associate a parti anatomiche distinte del cervello. A partire dal secolo scorso tramite uno strumento di indagine che è quello della dissociazione, cioè l’osservazione che un paziente mostra un danno selettivo ad una particolare componenen- te del sistema cognitivo, fu possibile dimostrare la suddivisione del cervello in moduli, cioè la presenza di sistemi specifici che corrispondono solamente a stimoli di una particolare classe. Le funzioni neurali del cervello umano sono state infine studiate nei particolari tramite l’utilizzo di tecniche di scan- sione computerizzata e visualizzazione dell’attività celebrale. Due principali metodi sono la Tomografia ad emissione di positroni (o PET,positron Emis- sion Topography) e la Risonanza magnetica funzionale (o fMRI, Functional Magnetic Resonance Imaging). I principi di funzionamento di queste due tecniche sono diversi, ma entrambe si basano sul fatto che quando un gruppo di neuroni aumenta la sua attività si verifica un maggior afflusso di sangue, che trasporta ossigeno e glucosio ai tessuti celebrali. In altre parole, l’entità del flusso sanguigno in una data zona del cervello riflette l’entità dell’attività neurale. Sottoponendo quindi un individuo sano a PET o fMRI, è possibi- le quindi stabilire quali parti del cervello si attivano maggiormente durante l’esecuzione di un determinato compito. Da qui è stato possibile capire che il cervello è diviso in mappe corrispondenti ad un area funzionale ma a sua volta ogni neurone all’interno della mappa ha una determinata funzione. Per esempio nell’area del linguaggio, i neuroni sono attivati in accordo alla ca- tegoria ed alla semantica delle parole. Artificial Self Organizing Maps e le mappe del cervello sembrano avere in comune molte caratteristiche. 2.2 Apprendimento Competitivo L’idea base che sta dietro l’apprendimento competitivo, descritte completa- mente in [4] è la seguente: si prende in considerazione una sequenza di vettori di input χ = χ(t) dove t è un numero intero positivo, ed un insieme di vettori di referenza mi (t) : mi ∈
con il corrente input; il vettore di referenza in questione verrà aggiornato in
modo tale da avvicinarsi al corrente χ(t). Se i vettori vengono comparati in
base ad una qualche misura di distanza d(x, mi ), gli aggiornamenti degli mi
deve essere tale che, se i = c è l’indice del vettore di referenza con la miglior
corrispondenza, allora d(x, mc ) viene decrementato mentre tutti gli altri vet-
tori di referenza mi ,dove i 6= c, vengono lasciati inalterati. In questo modo
differenti vettori di referenza tendono a specializzarsi su differenti domini di
input χ.
Una delle applicazioni più importanti dell’apprendimento competitivo è il
processo di quantizzazione vettoriale per la compressione dei dati. Questo
processo può essere utilizzato sia per la memorizzazione sia per la trasmissio-
ne di immagini e di dati sul parlato. L’idea è di classificare un insieme od una
distribuzione di vettori in input χ in M categorie, e quindi rappresentare un
vettore semplicemente attraverso la classe in cui esso rientra. Normalmente le
classi sono definite da un insieme di M vettori prototipi e la classe corrispon-
dente ad un certo vettore in input viene individuata determinando il vettore
prototipo più vicino, in termini dell’usuale metrica euclidea. Lo spazio di
input viene suddiviso in regioni poliedriche in base al vettore prototipo che
risulta più vicino e i confini di tali regioni sono piani perpedicolari alle linee
che congiungono coppie di vettori prototipo. Questo processo determina la
divisione dello spazio di input in tasselli, dando origine alla tassellazione di
Voronoi o tassellazione di Dirichlet.
La formalizzazione di questo procedimento in termini di apprendimento com-
petitivo è immediata. La regola che viene utilizzata per la scelta del codebook
(anche detto prototipo o vettore di referenza) vincitore è la seguente:
kχ(t) − mc (t)k = mini kχ(t) − mi (t)k (2.1)
Mentre la regola di aggiornamento dei codebook si basa sulla discesa del
gradiente ed ha la seguente forma:
(
mc (t + 1) = mc (t) + α(t)[χ(t) − mc (t)]
(2.2)
mi (t + 1) = mi (t)per i 6= c
dove α(t) è una funzione monotona, decrescente compresa nel range (0,1).
Questa è la descrizione analitica decrescente più semplice dell’apprendimento
competitivo, in generale può essere utilizzata qualsiasi metrica non necessa-
riamente quella euclidea. Nel caso venga utilizzata la metrica euclidea il
precedente algoritmo prende il nome di K-means [5]. Più precisamente l’al-
goritmo è composto da i seguenti passi:
141. Vengono scelti in maniera random M vettori che rappresentano il grup-
po iniziale di centroidi dal data set.
2. Ogni vettore di input viene assegnato al gruppo che ha il vettore di
centroidi più vicino.
3. Quando tutti i vettori di input sono stati assegnati viene ricalcolata la
posizione degli M centroidi come il baricentro dei cluster risultanti dal
precedente step.
La figura2.1 mostra il funzionamento dell’apprendimento competitivo. La
figura a mostra come ogni vettore di input venga assegnato ad il cluster piú
vicino, mentre la figura b mostra la parte di aggiornamento dell’algoritmo
competitivo. Con il simbolo ”x” si rappresentano i centroidi, con il simbolo
”.” si rappresentano gli input.
Figura 2.1: La figura a mostra come ogni vettore di input venga assegnato
ad il cluster piú vicino, mentre la figura b mostra la parte di aggiornamento
dell’algoritmo competitivo.
In seguito è nata l’idea di creare mappe globali dove è reso possibile avere
un ordinamento globale dei vettori di input. Ciò è stato realizzato nelle Self
Organizing Map descritte nel seguente paragrafo.
152.3 SOM Standard
La Self-Organizing Map è una struttura connessionistica i cui neuroni so-
no organizzati all’interno di un array di superficie mono-dimensionale o più
spesso bi-dimensionale (Figura 2.2). La mappa riceve in ingresso dei vet-
tori di input e, ad addestramento ultimato, è in grado di esibire sulla sua
superficie una compressione topologica di tutti i dati vettoriali acquisiti. In
tal modo similarità ed analogie (spaziali) dei vettori presentati in ingresso,
riceveranno medesimo trattamento dalla SOM che provvederà ad ordinarli
su intorni spaziali prossimi. Ad una prima analisi, la SOM svolge il ruolo di
clusterizzatore di dati d’ingresso, i quali vengono accomunati spazialmente in
base ad una qualche loro caratteristica più o meno soggiacente. Nelle migliori
delle ipotesi, ad ogni neurone della rete corrisponderebbe un cluster e cioè
un raggruppamento omogeneo dei dati di input, localizzati in quella zona per
un qualche criterio di similarità individuato dalla rete. Il processo di adde-
stramento (training process) coincide, quindi, con una fase di adattamento
spaziale che la SOM compie, tramite modifica dei propri coefficienti di con-
nessione, ad una presentazione di patterns vettoriali considerati segnale di
input. Come già detto, il processo di apprendimento è non-supervisionato,
ciò significa che non vi è definizione in anticipo sulla configurazione spa-
ziale cui perverrà la SOM. La variazione dei coefficienti di connessione, e
quindi la configurazione della mappa,dipenderà soprattutto dalle caratteri-
stiche statistiche del campione di dati che costituisce la base di conoscenza
su cui si informerà tutto il processo di apprendimento. Ogni qualvolta si
presenta un pattern di ingresso, viene infatti eseguito un matching tra quel
pattern (definito come un vettore a n-dimensioni) e tutte le unità neuronali
formanti la mappa bi-dimensionale (definite anch’esse in termini vettoriali a
n-dimensioni). Il criterio adottato per stimare la diversità tra i due vettori fa
capo alla nozione di distanza. La distanza in questione può essere calcolata
in vari modi, solitamente si considera la distanza euclidea. E’ importante no-
tare che questo calcolo è reso possibile dal fatto che i due vettori, quello che
rappresenta il pattern in ingresso e quello che rappresenta l’unità della map-
pa, contengono il medesimo numero di componenti. Si considera ora come
unità di uscita vincitrice quella in cui la distanza precedentemente calcolata
assume il minimo valore. L’algoritmo di Kohonen adotta la strategia della
bolla, ciò significa che non vi è una sola unità vincitrice, ma si considerano
vincitrici (si recuperano, cioè) anche tutte le altre unità di uscita che si tro-
vano entro una certo intorno dall’unità vincitrice principale. Tale intorno,
nella terminologia di Kohonen, è detto raggio della bolla.
Ciò che subirà quindi delle modifiche rispetto all’apprendimento compe-
titivo è la regola di aggiornamento dei codebook anche chiamati vettori di
16Figura 2.2: SOM 6 X 6
17referenza reference vector. Questi ultimi, infatti, non saranno più aggiornati
indipendentemente gli uni dagli altri. Esistono differenti metodi per permet-
tere ciò ma il concetto è sempre lo stesso: non verrà aggiornato solamente il
codebook vincente del corrente input ma anche gli altri codebook subiranno
delle modifiche diverse a seconda della loro posizione rispetto all’input e dal
tipo di algoritmo scelto, dipende quindi dall’input e dal raggio della bolla
scelto.
Nel seguito si trova la descrizione dell’algoritmo delle Self Organizing
Map. Ogni input di dati è un n-tupla di numeri reali; questo è rappresentato
come un vettore χ = [ξ1 , ξ2 , ..., ξn ]T ∈Dove t = 0, 1, 2, ... è un intero, hci è chiamata neighborhood function e
gioca un ruolo centrale nel processo di rilassamento. Questa funzione deve
essere decrescente e monotona per garantire la convergenza dell’algoritmo.
Le scelte più comuni per la neighborhood function sono le seguenti due:
1. Limit neighborhood relationship:
(
hci (t) = α(t) se i ∈ Nc
(2.6)
hci = 0 altrimenti
Dove Nc (t) è l’insieme dei vicini del nodo c, α(t) è il fattore di indice di
apprendimento. Entrambi decrescono, solitamente, monotonicamente
nel tempo.
2. Gaussian bell relationship:
krc − ri k
hci = α(t) ∗ exp( ) (2.7)
2 ∗ σ 2 (t)
Dove rc ∈Figura 2.3: Istantanea della fase di adattamento tra il vettore d’ingresso e
quello della mappa .
2.4 Una mappa di vettori binari
Consideriamo ora una semplice caso di mappatura tramite SOM di vettori
binari considerati input della rete. La figura 2.4 sintetizza la descrizione di
16 animali definiti in base l’assenza o la presenza di 13 differenti attributi.
Tutti i membri del data set sono stati presentati come input, in maniera
iterativa, ad una SOM di 10 x 10 neuroni soggetta al processo di adatta-
mento (come si è accennato in precedenza, l’adattamento spaziale ai pattern
d’ingresso è il compito primario di una rete SOM). L’inizializzazione della
mappa è stata definita in maniera random. Dopo 2000 cicli di presentazioni,
in cui il raggio della bolla e l’indice di apprendimento sono fatti decrescere,
ogni neurone diventa più o meno rappresentativo di una delle combinazioni
dei 13 attributi e quindi di uno dei 16 animali. La mappa ottenuta è mostrata
in Figura 2.5. La mappa mostra un ordine spaziale che in un certo modo ha
catturato le relazioni di famiglia essenziali tra i diversi animali. Ad esempio
le unità corrispondenti alla famiglia uccelli occupano la parte sinistra della
mappa, i predatori sono categorizzati verso destra e gli animali più pacifici
come la zebra, il cavallo e la mucca si trovano, invece, in alto al centro. All’in-
terno di ogni classe sono possibili ulteriori sottocategorie basati sul rapporto
di similarità tra coppie e terne di animali. Dall’esempio appena trattato,
20Figura 2.4: Animali e loro attributi codificati in maniera binaria (tratto da
[3]).
21Figura 2.5: Una SOM 10 x 10 addestrata tramite il data set della figura2.4.
All’interno della mappa è possibile discernere dei clusters formatisi in base
al rapporto di similarità dei pattern di ingresso (tratto da [3]).
si evince che la SOM provvede ad una quantizzazione vettoriale, nel senso
che il valore di ingresso fornito alla rete è uno spazio continuo e deve essere
discretizzato su una superficie bi-dimensionale. Se, quindi, gli ingressi del-
la rete sono vettori n-dimensionali x, la SOM opererà una rappresentazione
spaziale discreta e puntuale di tali dati multi-dimensionali, organizzandoli in
raggruppamenti omogenei con dimensionalità inferiore a quella d’inizio che
tuttavia presentano una coerenza topologica con i dati di ingresso in base
ai quali tali raggruppamenti sono stati realizzati. La rete deve fornire una
rappresentazione ottimale della discretizzazione dello spazio continuo dei da-
ti in input limitatamente però alla sua struttura fisica. Reti bi-dimensionali
permetteranno solo una visualizzazione della mappatura lungo due coordi-
nate, reti tridimensionali rappresenteranno il vettore discretizzato lungo tre
coordinate e cosı̀ via.
2.5 Aspetti multipli di una SOM
In questo paragrafo saranno considerate le proprietà e potenzialità di una
SOM per le sue possibili applicazioni. Le considerazioni qui sviluppate avran-
22no carattere propedeutico a quanto verrà detto in seguito, ma allo stesso
tempo sono da considerarsi sunto di quanto detto in precedenza.
1. La SOM può essere ritenuta un modello di apprendimento non-supervisionato.
Come tale risponde bene alla risoluzione di problemi quali:
• Clustering. Fornito un insieme di elementi in ingresso, questi
devono poter essere raggruppati in clusters (gruppi omogenei) ed
il compito della rete, dopo l’apprendimento, è individuare, per
ogni ingresso, il gruppo di appartenenza.
• Quantizzazione vettoriale. Il valore di ingresso fornito alla rete
è uno spazio continuo che deve essere discretizzato. Gli ingressi
della rete sono vettori n-dimensionali x, l’uscita è una rappre-
sentazione discreta dello spazio d’ingresso. La rete deve fornire
una rappresentazione ottimale della discretizzazione dello spazio
d’ingresso.
• Estrazioni delle caratteristiche. La SOM estrae delle caratte-
ristiche dall’ingresso iniziale, questo spesso implica una riduzione
della dimensionalità.
2. La SOM fornisce una adaptive and contextual knowledge representation.
I formalismi tradizionali per la rappresentazione della conoscenza - reti
semantiche, logica dei predicati, frames, eccetera - rimangono fissi nella
loro staticità e la loro relazione di referenza dei loro elementi è di natura
arbitraria e prevede l’intervento umano. Una rete SOM non solo è da
considerarsi come modelizzatore fuzzy, permette rappresentazioni più
granulari all’interno delle categorie, ma le categorie stesse sono create in
situ durante il processo di apprendimento e successivamente sottoposte
a gradience modelling.
3. La SOM è usata spesso utilizzata come dispositivo per analisi stati-
stiche. Una rete SOM, infatti, costituisce un metodo di riduzione
e proiezione delle dimensionalità, capace di mappare (e categorizza-
re) high-dimensional data space into low-dimensional space riuscendo
a preservare però le proprietà dinamiche e topologiche dello spazio
iniziale.
23Capitolo 3
Algoritmi ricorsivi per
l’elaborazione di strutture
grafiche
Prima di iniziare a descrivere le reti neurali ricorsive [22] [23] [24] [25] è ne-
cessario introdurre le proprietà dei grafi e la notazione usata.
• un grafo generico Y è costituito da una coppia (vert[Y ], edge[Y ]), dove
vert[Y ] indica l’insieme dei vertici o nodi che costituiscono il grafo, e
edge[Y ] rappresenta un insieme di relazioni binarie ordinate di elementi
di vert[Y ].
• un arco (v, w) è un elemento dell’insieme edge[Y ]. Un arco si dice non-
diretto se sono presenti in edge[Y ] entrambe le relazioni (v, w) e (w, v),
ciò significa che un grafo è non-diretto se lo sono tutti i suoi archi. se
le condizioni precedenti non sono valide si parla di arco e grafo diretti.
• due nodi v ∈ vert[Y ] e w ∈ vert[Y ] si dicono adiacenti se sono collegati
da un arco, cioè se (v, w) ∈ edge[Y ] oppure (w, v) ∈ edge[Y ] .
• Un n-cammino(o cammino di lunghezza n) in un grafo diretto Y dal
nodo v ∈ vert[Y ] al nodo w ∈ vert[Y ] indica una sequenza di nodi
v0 , ..., vn−1 che inizia con v = v0 e termina con w = vn−1 , tale che
(vi , vi+1 ) ∈ edge[Y ]. Tale grafo si dice aciclico se non contiene nessun
n-cammino in cui il nodo iniziale e quello finale coincidono.
Supponendo, adesso, che Y sia un grafo aciclico diretto (DAG), si possono
introdurre proprietà aggiuntive:
24• dati v ∈ vert[Y ] e w ∈ vert[Y ], w si dice padre di v se esiste l’arco
diretto (w, v) (chiaramente v viene denominato figlio di w). Si defini-
scono inoltre pa[v] l’insieme dei nodi padri di v e ch[v] l’insieme dei
nodi figli di w. Dall’uso ricorsivo di pa[v] e di ch[v], si ottiene l’in-
sieme degli antenati di v an[v] e l’insieme dei suoi discendenti de[v],
rispettivamente.
• viene definito in-degree di un nodo v il numero di padri di v e quindi
la cardinalità dell’insieme pa[v], mentre viene definito l’outdegree di v
come il numero di figli del nodo v e quindi la cardinalità dell’insieme
ch[v]. L’outdegree di un grafo Y corrisponde al massimo outdegree
associato ad i suoi nodi.
• un vertice s ∈ vert[Y ] è chiamato supersource di Y se ogni vertice in
Y può essere raggiunto da un cammino che ha inizio in s. Un grafo
aciclico diretto, in particolare, ha al massimo una supersource.
Un albero è un caso particolare di grafo diretto dove l’in-degree di tutti i nodi
è al massimo uno e la supersource è unica e coincide con la radice dell’albero.
Nel seguito viene fatta una ulteriore suddivisione dei grafi diretti a seconda
delle relazioni che si stabiliscono tra i vari nodi. Un DAG è detto posizio-
nale (e viene indicato con DPAG)se oltre ad essere un grafo aciclico diretto
esiste una funzione biettiva p: edge[Y ] ⇒ N + che associa una posizione a
ciascun arco uscente da v. Un caso particolare di DPAG è la classe dei grafi
DAG ordinati che vengono definiti come grafi diretti in cui sussiste una re-
lazione di ordine totale sugli archi uscenti da un nodo. Questo ordinamento
è imposto secondo convenzioni più o meno naturali o evidenti. Quindi nei
DOAG,differentemente che nei DPAG, gli archi uscenti da ogni nodo devono
essere posizionati in sequenza, senza che alcuna posizione venga lasciata vuo-
ta. Nei DPAG non è imposto questo limite. Un DAG viene definito limitato
quando si considera un grafo in cui è stato imposto un limite superiore al
grado di ingresso in-degree o di uscita out-degree di ogni nodo appartenente al
grafo in questione. La notazione che viene solitamente utilizzata per indicare
un insieme di DAG con limitato in-degree ed out-degree è la seguente:
](i,c) dove i ed c indicano rispettivamente il massimo in-degree ed il mas-
simo out-degree.
Per utilizzare questi grafi nei problemi di clustering e di classificazione è
necessario associare delle etichette (tuple di variabili) ai nodi del grafo. Una
struttura dati Y è quindi un DPAG i cui vertici sono etichettati da un sot-
toinsieme di variabili appartenenti allo stesso dominio; con l(Y ) denotiamo
l’insieme di tali variabili e con l(Yv ) l’etichetta associata al nodo v ∈ vert[Y ].
25Si dice quindi che, dato il grafo Y, il DAG ottenuto ignorando tutte le eti-
chette di Y è lo scheletro (scheleton) di Y e viene indicato con schel(Y ).
Viene cosı̀ definito lo spazio delle strutture dati γ ] , indicando con γ lo spazio
delle etichette e con ] la classe degli scheletri. Chiaramente due strutture dati
possono essere distinte tra loro perchè hanno un diverso scheletro o, se tale
distinzione non può essere fatta, perchè hanno etichette diverse ai nodi. La
classe dei dati strutturati definita su un dominio di etichette l(Y ) e scheletro
]
γ ] è indicato l(Y )γ . Un DAG vuoto è denotato attraverso il simbolo speciale
.
3.1 Reti neurali ricorsive
In questa sessione verrà descritto come avviene l’apprendimento supervisio-
nato nei domini strutturati attraverso le reti neurali. Questa descrizione
è utile in quanto aiuta a capire l’apprendimento non supervisionato nelle
SOM-SD in quanto il framework di calcolo utilizzato da queste ultime è es-
senzialmente lo stesso definito nelle reti neurali ricorsive.
Le reti neurali ricorsive rappresentano uno strumento di calcolo potente
per il trattamento di dati strutturati, tale da colmare il gap storico fra le
tecniche connessionistiche classiche, che trovano applicazione su dati scarsa-
mente organizzati, e una grande varietà di problemi reali, nei quali l’infor-
mazione si presenta ”naturalmente” codificata nelle relazioni che legano le
entità di base, specialmente nel campo della chimica [6], [8], [9], [10]. Le
proprietà teoriche delle reti neurali ricorsive sono state studiate [11] [12] [13]
[14] [15] [16] [17] e stanno emergendo molte applicazioni [23] [19] [20] [21]. Le
reti ricorsive elaborano informazione sotto forma di grafi ordinati, diretti ed
aciclici o , più semplicemente di alberi (ricorsivamente equivalenti). Ad ogni
istante di tempo l’etichetta di un nodo del grafo e gli stati calcolati dai figli
vengono dati in ingresso ad uan rete feedforward, in base ad una strategia
di addestramento simile a quella delle reti ricorrenti [30] [31] [32]. Tuttavia
se nelle reti ricorrenti l’elaborazione dei dati avviene in base al loro fluire
naturalmente sequenziale, le reti ricorsive seguono l’ordine parziale imposto
sui nodi del grafo e si srotolano nella dimensione spazio temporale ad esso
sottesa.
Le reti neurali ricorsive descritte in [7] sono reti neurali in grado di tra-
sformare un insieme di grafi etichettati in un insieme di vettori a valori reali.
Più precisamente la classe di funzioni che le reti neurali ricorsive realizzano
possono essere indicate nel seguente modo:
26Γ : I ] →
Figura 3.1: La figura mostra le due funzioni che costituiscono l’algoritmo di
apprendimento delle reti neurali ricorsive e lo scambio di informazione tra
esse. Vedremo in seguito come la funzione di codifica τ può essere applicata
nelle SOM-SD per la codifica dell’informazione dei grafi.
283.2 Dalle reti ricorsive alle SOM per struttu-
re
Il punto fondamentale dell’algoritmo di apprendimento SOM è l’apprendi-
mento della mappa delle feature.
M :I→A (3.5)
la quale, dato un vettore nello spazio continuo degli input I ritorna un
punto nello spazio discreto degli output A. Questo è ottenuto nelle SOM
associando ogni punto in A con un neurone differente. In più, la topologia
dello spazio di output A è tipicamente un arrangiamento di questo insieme
di neuroni come i nodi in un lattice 1 o 2 dimensionale. Dato un vettore
di input v, la SOM ritorna le coordinate all’interno di A del neurone con il
vettore di pesi più vicino. Perciò, l’insieme di neuroni produce una partizione
dello spazio degli input I. In tipiche applicazioni I = n ∈Figura 3.2: Esempi di DOAGs rappresentanti immagini. Le etichette non sono
visualizzate
30tagliata in [27].
Le Self Organazing Map introdotte da Kohonen sono reti neurali non
supervisionate adatte sia al clustering che alla visualizzazione. Può essere
considerato un algoritmo che mappa uno spazio ad alta dimensionalità in
uno spazio a bassa dimensionalità ,generalmente 2, che è chiamato mappa.
Questa proiezione partiziona i dati di input in cluster preservando la loro
topologia.Il suo più simile predecessore è l’algoritmo K-means, che opera
nello stesso modo dell’algoritmo SOM senza però preservare la topologia dei
dati di input e senza una facile visualizzazione. Questi approcci diventano
inadeguati quando abbiamo a che fare con strutture complesse. Infatti, gli
approcci basati su feature solitamente falliscono per la loro selezione a priori
delle feature, e la loro incapacità di rappresentare informazione strutturata.
Self Organazing Map possono clusterizzare DAGs (directed acyclic graphs)
e DAGs etichettati.
In questo capitolo verrà mostrato come l’equazione 3.5 viene generalizza-
(c)
ta per essere adattata al caso in cui I ≡ l(Y )] , cioè, lo spazio degli input
è un dominio strutturato con etichette in l(Y). In questo caso, deve essere
specificato come la funzione
(c)
M ] : l(Y )] →A (3.6)
è realizzata. Una possibilità è di ridefinire l’equazione (1) nel seguente modo:
(
] nilA se Y = ξ
M (Y ) = (3.7)
Mnode (l(Ys ), M ] (Y (1) ), ..., M ] (Y (c) )) altrimenti
dove s = source(Y ), Y (1) , ..., Y (c) sono i (eventualmente vuoti) sottografi
puntati dagli archi uscenti da s, N illA è un vettore con coordinate ”speciali”
nello spazio discreto di output A, e
cvolte
z }| {
Mnode : l(Y ) × A × ... × A → A (3.8)
è una SOM definita su un generico nodo, che prende come input l’etichetta
del nodo e la codifica dei sottografi Y (1) , ..., Y (c) in accordo con la mappa
M ] . Attraverso lo srotolamento della equazione ricorsiva 4.7, si può vedere
che M ] (Y )può essere calcolata applicando la funzione Mnode a partire dalle
foglie (cioè, i nodi con outdegree nullo),e procedendo con l’applicazione di
31Mnode dal basso verso l’alto, dai nodi frontiera fino alla supersource (radice) del grafo Y. Si può vedere come Mnode nell’equazione 4.7 ha lo stesso ruolo di τ nell’equazione 4.1, con la differenza che τ ritorna un vettore a valori reali rappresentante un descrittore ridotto del nodo, mentre Mnode ritorna le coordinate del neurone vincitore, il quale, per la capacità di riduzione dei dati delle SOM, continua ad essere un descrittore ridotto ,reduced descriptor del nodo. Un esempio di come il calcolo descritto sopra procede è mostrato nella Figura 3.3. 3.4 Un Modello di Mnode Nella precedente sezione è stato mostrato come il calcolo di M ] può essere fatto in maniera ricorsiva attraverso l’applicazione di Mnode ai nodi appar- tenenti alla struttura in input. Più precisamente lo schema ricorsivo per il grafo Y segue lo scheletro skel(y) del grafo. In questa sessione verranno dati i dettagli dell’implementazione sul della funzione Mnode . Verrà assunto che ogni etichetta in l(Y ) sia codificata in U ∈
Puoi anche leggere

















































