Piattaforme per Big Data: Cloudera - Elaborato finale in Basi di Dati - Ingegneria Informatica
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Elaborato finale in
Basi di Dati
Piattaforme per Big Data: Cloudera
Anno Accademico
2014/2015
Candidato:
Sellitto Raffaele
N46000895
1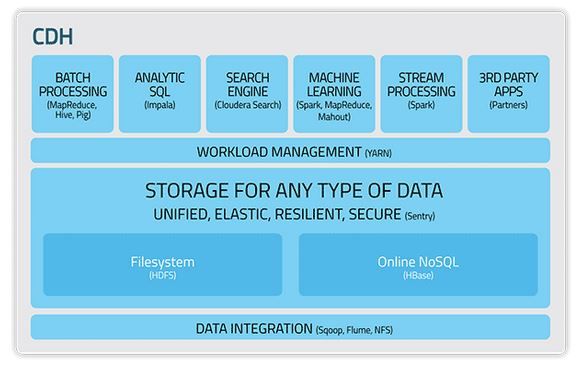
Ai miei cari,
Ai miei amici,
ed alla mia famiglia Erasmus...
2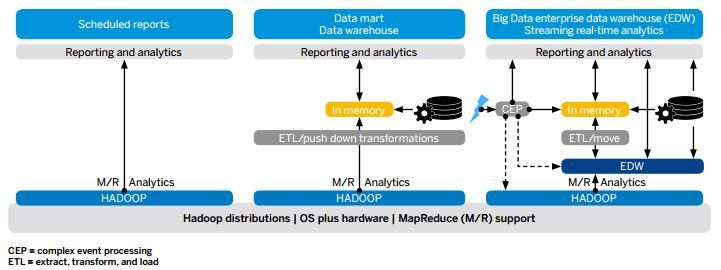
Indice
Indice………………………………………………………………………………………………...3
Introduzione……....………………………………………………………………………………...4
Capitolo 1: Big Data………………………………………………………………………………..6
1.1 Una definizione di Big Data…………………………………………………………………...6
1.2 Modelli dimensionali per una descrizione di Big Data……………………………………...8
1.3 Esempi di applicazione…………………………………………………………………........11
1.4 Breve storia dei Big Data…………………………………………………………………….12
1.5 Principali critiche e problemi…………………………………………………………………13
1.6 Big Data e Business Intelligence……………………………………………………………16
Capitolo 2: NoSQL………………………………………………………………………………..18
2.1 Le tecnologie NoSQL………………………………………………………………………...18
2.2 ACID e BASE………………………………………………………………………………….19
2.3 Alcuni esempi di DataBase NoSQL………………………………………………………...21
2.4 Soluzioni NoSQL per Big Data……………………………………………………………...22
Capitolo 3: Apache Hadoop……………………………………………………………………...24
3.1 Le origini: Google MapReduce e Google File System……………………………………24
3.2 Le caratteristiche fondamentali di Apache Hadoop……………………………………….25
3.3 MapReduce: Come funziona………………………………………………………………..26
3.4 HDFS: Come funziona……………………………………………………………………….29
3.5 Esempi di utilizzo……………………………………………………………………………..30
Capitolo 4: Cloudera………………………………………………………………………………31
4.1 La Cloudera Inc……………………………………………………………………………….31
4.2 La distribuzione Hadoop di Cloudera: CDH………………………………………………..32
4.3 Esempi di utlizzo di CDH…………………………………………………………………….34
4.4 L’alleanza con Teradata e SAP……………………………………………………………..35
4.5 La strategia di business di Cloudera: investire nell’opensource………………………..39
Conclusioni………………………………………………………………………………………...42
Bibliografia………………………………………………………………………………………....43
3
Introduzione
Questo elaborato intitolato “Piattaforme per Big Data: Cloudera” si pone l’obiettivo di
analizzare il concetto di Big Data e quali sono le principali soluzioni finalizzate alla
gestione di queste particolari collezioni di dati, soffermandosi in particolar modo sulla
soluzione proposta dalla “Cloudera Inc”, oggetto di questo elaborato.
Chiaramente, al fine di descrivere al meglio la soluzione CDH di Cloudera, è
doveroso introdurre e descrivere in maniera dettagliata il contesto nel quale è
necessario muoversi. Ci si soffermerà quindi su cosa sono i Big Data, cosa significa
gestirli, quali sono i principali vantaggi delle loro analisi, ed anche quali sono le
principali problematiche ed i principali rischi che possono caratterizzare il loro utilizzo.
Si procederà poi con una definizione di NoSQL ed a una piccola introduzione a quelle
che sono le principali tecnologie di questa categoria di sistemi. Tali tecnologie si sono
rivelate infatti fondamentali per la gestione di grosse moli di dati, le quali, spesso e
volentieri, si presentano in forma non strutturata o semistrutturata, sottolineando
l’inadeguatezza dei classici sistemi di gestione e persistenza dei dati per lo più
riconducibili a sistemi relazionali.
Si analizzerà poi quello che è uno delle più importanti piattaforme software dedite alla
gestione e alla manipolazione dell’informazione dei Big Data: si parlerà infatti di
Apache Hadoop, la quale forse è il prodotto più importante proposto
dall’organizzazione noprofict Apache Software, avendo trovato una vastissima
applicazione in tutti quei contesti dove è necessario elaborare grandi quantitivi di dati
in maniera efficiente.
4
Si introdurrà infine Cloudera parlando prima della società e dei suoi obiettivi, e poi
introducendo in maniera approfondita CDH (Cloudera Distribution of Hadoop),
piattaforma di Cloudera finalizzata alla gestione di Big Data, basata su Apache
Hadoop e quindi ad Hadoop fortemente legata. Si procederà poi con una descrizione
delle strategie di marketing dell’azienda soffermandosi anche sulle principali
partnership acquisite con aziende operanti nel settore dell’IT, e sui principali prodotti
risultanti da queste alleanze.
Oltre che effettuare una analisi descrittiva delle tecnologie citate, mi sono anche
soffermato con minuziosità ed interesse alla descrizione delle relative applicazioni.
Questo perchè una delle condizioni per le quali una tecnologia possa definirsi
interessante è che sia, da un punto di vista applicativo, utile ed efficiente.
5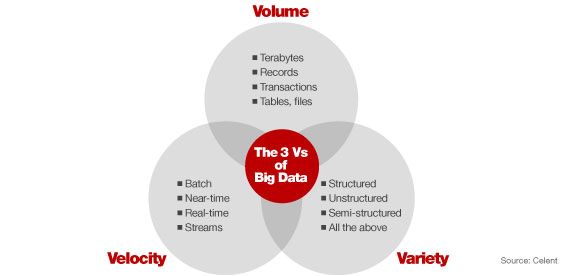
Capitolo 1: Big Data
1.1 Una definizione di Big Data.
Negli ultimi anni sempre più rilevanza ha assunto il concetto di Big Data, soprattutto
in contesti aziendali dove l’informazione è vista come una delle risorse fondamentali.
Un Big Data può essere definito in maniera generica come una gigantesca collezione
di informazioni, ed il concetto può essere esteso andando ad inglobare le tecnologie
legate alla loro gestione. Tali tecnologie sono finalizzate alla gestione degli enormi
quantitativi di dati che contraddistinguono queste collezioni, le cui dimensioni si
aggirano nell’ordine degli zettabyte (uno zettabyte corrisponde a 1021 byte, ossia un
triliardo di byte).
In particolar modo, è importante constatare in cosa differisce un Big Data da un
classico DataBase. Se in un DataBase è possibile infatti andare a rappresentare
anche una vastissima collezione di informazioni in maniera strutturata (ossia
seguendo specifici modelli logici di rappresentazione), ciò che contraddistingue un
Big Data è in prima forma la sua grandezza, in quanto la sua mole di informazioni
costituenti è di molti ordini superiore a quella ospitata da un classico DB, ed è per
questo che tipicamente i dati di un Big Data sono distribuiti su un elevato numero di
computer.
Questa differenza risiede nel fatto che, mentre i DataBase sono progettati e costruiti
con l’intento di ospitare specifiche informazioni, i Big Data sono il risultato della
6
creazione volontaria o meno1 di un gigantesco numero di dati prodotti da un
altrettanto grande numero di editori (che possono essere persone o macchine).
La diffusione del concetto di “Big Data” è legata infatti alla diffusione del WEB, il
quale è probabilmente la tencologia che più di tutte non solo ha offerto la possibilità
di accedere a vastissimi contenuti informativi, ma ha anche offerto la possibilità a
miliardi di persone (e computer) di diventare editori di informazioni di qualisasi
tipologia (testuale o multimediale).
In secondo luogo, seconda caratteristica fondamentale di un Big Data è l’elevatissima
eterogeneità dell’informazione inglobata. Infatti un Big Data può essere costituito da
informazioni proveniente da tantissime fonti differenti, e quindi può essere
caratterizzato dalla possibilità di presentarsi in forma strutturata, semistrutturata o
non strutturata (quindi dalla possibilità di non seguire alcun modello logico di
rappresentazione dell’informazione).
Si prenda ad esempio in considerazione l’informazione prodotta da un social network,
i quali sono probabilmente i principali alimentatori dei Big Data oggi esistenti. Il solo
Facebook produce un quantitativo informativo superiore a mezzo petabyte per
giorno. Ebbene, anche se l’informazione rappresentata da un post è presentata in
forma strutturata, l’informazone vera, ossia quella che riguarda l’utente, corrisponde
all’informazione testuale (nel campo testo) del post, quindi corrispondente ad
informazione non strutturata.
1
Più che involontaria la creazione del dato, può essere involontaria la creazione di queste specifiche collezione
di dati, che possono essere viste come l’agglomerato dei dati prodotti quotidianamente da utenti e computer.
Ma, negli ultimi anni, molte aziende stanno provvedendo a raccogliere e collezionare volontariamente grandi
moli di dati, archiviandole anche in maniera non strutturata visto che le moderne tecnologie permettono una loro
gestione ed analisi.
7Un Big Data è quindi una gigantesca collezione di dati eterogenei, prodotti da
tantissime sorgenti differenti, e caratterizzati dalla possibilità di presentarsi in forma
non strutturata, sicuramente distribuita.
1.2 Modelli dimensionali per la descrizione di un Big Data.
Quali sono le dimensioni descrittive nei confronti delle quali è necessario andare ad
esprimere le caratteristiche costitutive di un Big Data?
Il problema fu affrontato nel 2001 da Doug Laney, analista per la società
internazionale MetaGroup2, operante nel settore dell’Information Technology.
Laney sviluppò un modello descrittivo caratterizzato da tre dimensioni fondamentali:
il famoso modello delle 3V.
2
La MetaGroup verrà poi acquisita dalla Gartner.
8Le dimensioni in questione sono:
Volume
, con cui ci si riferisce alla caratteristica forse fondamentale di un Big Data
dato che il nome stesso fa riferimento al quantitativo di dati costituenti. La principale
caratteristica di un Big Data è infatti il suo ordine di grandezza, sempre al limite di
quella che è la portata delle tecnologie disponibili per la gestione e manipolazione
dell’informazione.
Varietà
, la quale va a sottolineare non solo l’eterogenerità dei dati inclusi nella
collezione che compone un Big Data, ma anche la potenziale eterogeneità dei Big
Data stessi, che possono appartenere a categorie differenti. In generale un analista
deve conoscere il contesto nel quale un Big Data si è sviluppato, al fine di una
estrapolazione ottimale dell’informazione.
Velocità
, la quale si riferisce sia alla velocità con la quale l’informazione costituente il
Big Data viene generata, sia alla velocità dei sistemi che gestiscono ed analizzano
tali moli informative, le quali devono reagire in maniera rapida, dato che con il
passare del tempo una informazione può diventare sempre meno interessante, fino a
diventare potenzialmente dannosa.
9Col passare del tempo, tuttavia, questo modello si è rivelato per lo più inadeguato per
la descrizione di tutte le caratteristiche di un Big Data. Sebbene la Gartner sia
sostanzialmente fedele al loro modello classico descrittivo, altre società operanti nel
settore dell’IT hanno apportato migliorie a tale modello, suggerendo nuove
caratteristiche, quali:
Variabilità
, la quale sottolinea la possibilità che l’informazione rappresentata da un
Big Data possa essere soggetta a modifiche. In altre parole, questa dimensione
inquadra la problematica dell’inconsistenza.
Veridicità
, la quale rappresenta l’accuratezza dell’informazione inclusa. Anche questa
caratteristica va opportunamente considerata nel processo di analisi
dell’informazione di un Big Data.
10Complessità
, la quale rappresenta il grado di complessità dei processi di gestione del
Big Data, fortemente dipendenti dal numero di fonti, dalle tipologie di dati e dal
numero dei dati stessi che costituiscono il Big Data.
1.3 Esempi di applicazione.
E’ interessante citare alcuni esempi di applicazione ed utilizzo dei Big Data, anche
solo per sottolinearne le potenzialità.
Come già espresso, i più grandi Big Data odierni sono identificabili nei social network,
i quali ospitano una grandissima raccolta di informazioni di natura più o meno
personale (la tematica della privacy è trattata nel paragrafo 1.5 dedicato alle critiche
e problemi).
Ed è proprio su questa mole di informazioni personali che molte aziende hanno
trovato la propria fonte di guadagno. Basti pensare a Google, la quale, offrendo una
vastissima suite di servizi completamente gratuiti (quali Gmail, Youtube, il social
Google+, e molti altri), è riuscita probabilmente a costruire uno dei più grandi Big
Data della storia (anche se Google non rilascia dati in merito). Grazie a questa
raccolta di informazioni dei propri utenti, Google riesce ad offrire pubblicità mirate ad
ogni singolo user, ricavando, di fatto, oltre il 90% degli introiti dalla pubblicità.
Altro interessante esempio applicativo è legato al settore metereologico, infatti è
grazie ad una gigantesca collezione di informazioni che il “Centro di Analisi degli
Uragani degli Stati Uniti d’America” prova a stimare l’intensità ed i percorsi degli
uragani che periodicamente si abbattono sugli Stati Uniti. Tali informazioni
provengono da telecamere, sensori e rilevatori disposti su larga scala geografica.
11Concludo citando il “Google Flu Trends” ed il “Street Bump”, due progetti interessanti:
il primo portato avanti da Google, che ha provato a stimare la portata di epidemie di
influenza abbattutesi negli Stati Uniti monitorando le query effettuate sull’omonimo
motore di ricerca in specifici archi temporali, ed il secondo invece portato avanti dalla
municipalità di Boston, la quale ha creato una applicazione smartphone che, facendo
utilizzo dell’accellerometro, era in grado di segnalare la potenziale presenza di buche
nel manto stradale della città.
In particolare mi riferirò a questi ultimi due esempi per introdurre potenziali
problematiche che contraddistinguono l’utilizzo dei Big Data (paragrafo 1.5).
1.4 Breve Storia dei Big Data.
E’ doveroso sottolineare che esistono i Big Data da quando esiste informazione e le
sue tecniche di gestione. Tuttavia è difficile identificare quando sia nato il concetto di
Big Data, almeno associato al significato cui corrisponde oggi, questo a causa
dell’intrinseca natura generica che costituisce il termine.
Il termine Big Data nacque con ogni probabilità nel 1990 quando John Mashey, che
all’epoca lavorava per la Silicon Graphics (una società operante nel settore della
Computer Grafica) utilizzò questo termine in una serie di slide presentative al fine di
sottolineare l’enorme mole di nuovi tipi di dati che la sua società si sarebbe trovata ad
affrontare, e le nuove tecnologie derivate dalla loro gestione.
12Con il passare del tempo il termine divenne sempre più di dominio pubblico. Nel ‘97,
in una conferenza dell’IEEE, Micheal Cox e David Ellswoth utilizzarono il termine per
identificare la problematica della distribuzione di grandi quantità di dati.
Dal ‘98 in poi sembra che il termine abbia acquisito la connotazione cui oggi siamo
soliti attribuirgli, come è possibile constatare nei seguenti testi: “How much
information is there in the world?” di Micheal Lesk, “Big Data… and the Next Wave of
Infrastress” di John R. Masey, “The Size and Growth of the Interner” di K.G. Koffman,
“How much information” di Peter Lyman. Questi sono solo alcuni dei testi pubblicati
tra il 1998 ed il 2000 che fanno utilizzo del termine Big Data con la moderna
concezione.
E’ infine il 2001 quando Doug Laney pubblica il noto articolo “3D Data Management”
introducendo il noto Modello delle 3V per andare a descrivere le dimensioni
caratterizzanti di un Big Data.
1.5 Principali critiche e problemi.
La principale critica posta nei confronti dello sfruttamento dei Big Data riguarda
sostanzialmente la privacy. Se Google, Facebook, Amazon e altre aziende si limitano
ad utilizzare l’enorme patrimonio di informazioni personali raccolte dai propri utenti
con il solo fine di offrire pubblicità mirata per massimizzare gli introiti (non senza
sollevare polemiche), è anche vero che esistono organizzazioni che utilizzano queste
risorse con fini un po' più controversi. E’ noto che, ad esempio, i servizi segreti di vari
paesi fanno ricorso all’analisi di questi Big Data con il fine di applicare tecniche di
monitoraggio di massa (si veda il recente scandalo che ha coinvolto la National
Security Agency americana).
13La privacy, tuttavia, più che essere una problematica associabile ai Big Data ed alle
loro tecnologie di gestione, è più relativa a quelle che sono le loro modalità di utilizzo.
Sta infatti agli utilizzatori di una nuova tecnologia essere i più saggi possibile,
dovendo essere consapevoli della portata della tecnologia stessa e dei potenziali
effetti negativi imputabili ad un suo cattivo utilizzo.
Problematiche che invece affligono propriamente i Big Data sono relative ai metodi di
analisi, ossia alle modalità di estrapolazione dell’informazione da queste collezione di
dati.
Per introdurre il problema si faccia riferimento al già citato progetto “Google Flu
Trends”, che prevedeva di stimare la portata e la diffusione di epidemie di influenza
negli Stati Uniti monitorando le query sottoposte al motore di ricerca dagli utenti in
specifici archi temporali.
Per quattro anni Google fornì statistiche di diffusione dell’influenza dal contenuto del
tutto omologo a quello proposto dal Centro di Controllo delle Malattie statunitense
(ma in maniera più rapida ed economica). Questo fino al 2012, anno che fu
caratterizzato da una epidemia di influenza che ebbe una maggiore risonanza
mediatica, risultando quindi più spaventosa. Il risultato fu che molte più persone sane
cercarono su Google informazioni sui sintomi influenzali, portando Google a
sovrastimare di molto l’impatto reale della malattia e sottolineando quello che è forse
una delle principali problematiche che può assalire una collezione di infomazioni, per
quanto questa sia grande.
14La problematica principale fu che Google non fece ricorso allo studio di diretti
meccanismi di causalità (che sono molto difficili da estrapolare da una collezione di
informazioni), ma semplicemente si basò su una serie di pattern specifici di
correlazione di informazione: nel caso specifico correlando la ricerca di una specifica
query alla probabilità di essere ammalato di influenza.
Facendo uso della probabilità ci si imbatte tuttavia a quelli che sono i problemi più
caratterizzanti della statistica: il Sample Error (quando il campionamento random dei
valori di un sistema non è adeguatamente grande e/o significativo) ed il Sample Bias
(quando il campionamento dei valori non è puramente random).
In altre parole un Big Data, per quanto grande, non è mai rappresentativo di tutte le
informazioni reali, ed una sua sovrastimazione può rivelarsi pericolosamente troppo
ottimistica, facendo in modo che una sua analisi porti a risultati sbagliati.
Stesso discorso per il progetto “Street Bump” della municipalità di Boston. L’obiettivo
era quello di pubblicare una applicazione smartphone in grado di segnalare, facendo
utilizzo dell’accellerometro, la potenziale presenza di una buca nel manto stradale
cittadino. Un sistema centrale avrebbe poi elaborato le informazioni, riportando su
una mappa i punti dove la probabilità di presenza di una voragine era maggiore.
Il risultato fu che il sistema “Street Bump” riportava solo informazioni che
coinvolgevano i distretti cittadini abitati da una popolazione più giovane
(evidentemente avvezzi all’utilizzo di uno smartphone), costringendo la municipalità a
continuare con il monitoraggio classico delle strade. Il problema, anche in questo
caso, fu di Sample Bias, in quanto andava considerato che non tutte le tipologie di
persone sarebbero state disposte ad abbracciare allo stesso modo il progetto.
151.6 Big Data e Business Intelligence
Con Business Intelligence si intende l’insieme di processi aziendali (e le tecnologie
correlate) finalizzati al raccoglimento ed all’analisi di specifiche collezioni di dati al
fine di trarne ulteriori informazioni. Le tecniche di Business Intelligence fanno uso di
statistica descrittiva3 basata su collezioni di dati limitate e di modelli logici
rappresentativi puliti e semplici.
Le tecniche di gestione dei Big Data, invece, solitamente fanno utilizzo di nozioni di
statistica inferenziale4 e studio di sistemi non lineari al fine di estrarre leggi ed
informazioni dall’enorme mole di dati di un Big Data.
Sebbene siano tecnologie differenti, molte sono le aziende che, negli ultimi anni,
hanno investito in parallelo su queste tecniche e tecnologie, puntando su quelle che
potrebbero essere interessanti applicazioni ibride delle tecniche di Business
Intelligence sui Big Data.
In generale, l’approccio delle aziende è raccogliere e conservare quanto più
contenuto informativo possibile, al fine di individuarne un potenziale valore. Il
principale utilizzo di tali tecnologie consiste nell’analisi delle informazioni raccolte dai
propri clienti, facendo in modo che le informazioni risultanti vengano utilizzate con il
fine di individuare nuovi potenziali clienti (espandendo il proprio mercato) e di
3
Statistica Descrittiva: Branca della statistica che si concentra nell’estrapolazione delle caratteristiche
descrittive di un sistema attraverso il calcolo di specifici indici statistici come valori medi, indici di variabilità,
ecc… , sui i propri valori o su un campionamento dei valor del sistemai.
4
Statistica Inferenziale: Branca della statistica che implementa tecniche di induzione di caratteristiche di un
sistema da suo campionamento di valori.
16migliorare il livello di soddisfazione dei clienti già acquisiti, delineando nuove strategie
per il miglioramento dei propri standard qualitativi.
17Capitolo 2: NoSQL
2.1 Le tecnologie NoSQL.
In genere, quando si parla di DataBase, si è soliti fare riferimento ad i DataBase
relazionali (ossia strutturati seguendo il modello logico relazionale per la
rappresentazione dei dati). E si è soliti inoltre sottintendere che la manipolazione dei
dati inclusi nel DB sarà possibile comunicando con il “Data Base Management
System” attraverso un linguaggio di tipo dichiarativo chiamato SQL (Structured Query
Language). Applicando SQL si invocheranno quindi le transazioni di stato del DB,
che portano ad una modifica (o lettura) dei dati della collezione.Tuttavia va osservato
che i DB relazionali sono solo una delle tante possibilità offerte dal ricco panorama
delle tipolgie di DataBase esistenti. In realtà, ci sono molte alternative alla tipologia
relazionale.
Era il 1998 quando Carlo Strozzi, un informatico che stava lavorando allo sviluppo di
una nuova piattaforma per le Base di Dati, introdusse per la prima volta il termine
NoSQL, andando a sottolineare l’incompatibilità della propria piattaforma in sviluppo
con questo linguaggio, pur essendo un DB di tipo relazionale.
Con il tempo il termine NoSQL ha assunto una connotazione più ampia andando a
rappresentare tutte le tipologie di DataBase alternative a quelle tradizionali.
E’ opportuno precisare che NoSQL è un acronimo di Not Only SQL, in quanto i
movimenti che supportano questo tipo di tecnologia non cercano di ostacolare
l’applicazione dei DB relazionali: essi si limitano semplicemente ad osservare che
18una universale applicazione di DB relazionali risulterebbe essere un’ inutile forzatura,
quando in realtà esistono contesti dove l’ applicazione di una differente tipologia di
DB potrebbe essere più ottimale.
2.2 ACID e BASE.
La sostanziale differenza tra DB classici e NoSQL è rimarcabile nella caratteristica
che non tutti i DB NoSQL rispettano quelle che sono le proprietà fondamentali delle
transazioni dei DB relazionali. Queste proprietà sono definite ACID, che stanno per:
Atomicity
, ossia esecuzione totale di una transazione sul DB. Una modifica, quindi, o
viene applicata nella sua interezza o non viene applicata.
Consistency
, in quanto il DB deve sempre trovarsi in uno stato consistente
(rispettando i vincoli di integrità) prima e dopo una transazione.
Isolation
, perchè ogni transazione deve essere indipendente dalle altre.
19Durability
, perchè una volta che una transazione richiede un Commit Work, questo
deve essere applicato. In altre parole, le modifiche apportate non devono essere più
perse.
Tuttavia risulta essere difficile garantire sui sistemi distribuiti i precendenti vincoli,
essendo particolarmente rigorosi. Si è quindi arrivati a sviluppare nuovi vincoli
transazionali che sono stati denominati BASE facendo gioco sulla scala dei valori
acidibasici del PH.
I DataBase BASE sono più flessibili rispetto alle classiche tipologie che adottano
transazioni ACID. BASE è infatti acronimo di:
Basically Available
, che significa che il DB non può generalmente garantire la
disponibilità di consulta o modifica di ogni dato. Vi sarà una risposta ad ogni richiesta,
ma le risposte possono anche essere di fallimento di consulta.
Soft state
, che significa che il DB potrebbe non trovarsi sempre in uno stato
consistente e rigoroso. I DB possono essere infatti sottoposti a cambiamento di stato
anche in archi temporali in cui non sono applicate transazioni (per effetto della
Eventual consistency), e quindi vanno sempre considerati in un stato “soft”, non
rigoroso.
Eventual consistency
, che significa che lo stato del DB diventa alla fine consistente.
Questo sottolinea che a fine di ogni transazione non viene controllato lo stato di
consistenza del DataBase: la consistenza della Base di Dati viene controllata
successivamente, dopo N transazioni applicate, in un arco temporale in cui magari
20non sono applicate transazioni. Questa flessibilità sulla gestione della consistenza è
causa del Soft State.
2.3 Alcuni esempi di DataBase NoSQL.
Esistono tantissime tipologie di DB che implementano logiche NoSQL. Quelle che
seguono sono soltanto degli esempi che illustrano delle logiche alternative di
rappresentazione e gestione dei dati.
Un primo esempio sono le Basi di Dati orientate al documento. In questa tipologia di
DataBase i record5 vengono visti come un insieme di campi. Sul numero e grandezza
dei campi non vi è però alcun vincolo per ciascun record6 , il che permette una
maggiore flessibilità rispetto al modello relazionale.
Un esempio di DataBase appartentente a questa tipologia è Apache Solr, il cui
sviluppo è portato avanti da Apache Software, la stessa software house che sviluppa
Apache Hadoop.
Altra tipologia sono i DataBase a grafo. Questi DB fanno ricorso alla teoria dei grafi
per andare a rappresentare ed archiviare l’informazione. In tali DataBase i record
vengono visti come i nodi del grafo cui corrisponde il DB. Ogni nodo è caratterizzato
da una serie di campi che qualificano il record specifico. Gli archi del grafo
corrispondono alle proprietà di relazione che legano i vari record.
5
record: unità informativa rappresentata nel DataBase. E’, tipicamente, costituito da vari campi.
6
a differenza del modello relazionale, dove cada record di una relazione è caratterizzato dallo stesso numero di
campi della stessa lunghezza.
21Un esempio di DataBase appartentente a questa tipologia è il noto DB Open Source
Neo4j, sviluppato dalla Neo Technology.
Ultima tipologia che cito sono i DB orientati agli oggetti, che fanno ricorso ai concetti
di classi ed oggetti introdotti dai linguaggi di programmazione object oriented. Molto
simili per gestione ai DB relazionali, sostituiscono il concetto di Tabella con quello di
Classe ed il concetto di record con quello di oggetto.
I DB ad oggetti, sebbene non molto utilizzati, detengono il record di implementazione
del DB più grande della storia. Infatti il DB dello
Stanford Linear Accelerator Center
della Stanford University ha una grandezza superiore a 1000 TB, ed è un DB
orientato agli oggetti.
2.4 Soluzioni NoSQL per Big Data.
Le tecnologie offerte da NoSQL si sono rivelate particolarmente preziose per quanto
riguarda la gestione e l’analisi dei Big Data. Questo perchè le tecnologie di gestione
di un DB tradizionale sono effettivamente inadatte alla gestione di una gigantesca
mole di dati non strutturati (che tipicamente costituiscono un Big Data), rendendo di
fatto più adatte le tecnologie NoSQL, più flessibili e quindi più scalabili.
Se si ha infatti l’esigenza di prelevare informazione da un Big Data, i dati prelevati
saranno quasi sicuramente non strutturati o semistrutturati. L’adozione di DB NoSQL
risulta quindi essere più agevole, permettendo di salvare i dati evitando una loro
strutturazione, la quale risulterebbe eccessivamente costosa (sia in termini di risorse
che di tempo) considerando la mole di dati che è necessario gestire. Un’ adozione di
22una soluzione NoSQL risulta essere quindi la migliore scelta in termini di costi, tempi
e performance.
Apache Hadoop fa costante utilizzo dei DB NoSQL. Queste sono infatti l’unica
tecnologia che permette la diffusione di una grande mole di dati (e processi) su
migliaia di server con un buon comportamento in termini prestazionali.
23Capitolo 3: Apache Hadooop
3.1 Le origini: Google MapReduce e Google File System.
La prima azienda operante nel settore informatico che decise di affrontare il problema
della gestione ed elaborazione dei dati su ampia scala fu Google che, nel 2000, iniziò
a sviluppare tecnologie che permettessero l’elaborazione distribuita di grosse mole di
dati.
Per Google, che all’epoca aveva 3 anni, la problematica era fondamentale, dato che
un motore di ricerca ha come ambizioso compito l’indicizzazione del web. Tale
problematica comporta la manipolazione di un numero elevatissimo di informazioni
che devono essere gestite in qualche modo.
Gli ingegneri Google arrivarono a sviluppare due soluzioni proprietarie che vennero
denominate Google MapReduce e Google File System. Il Google File System è un
File System7 finalizzato alla gestione e al salvataggio di file su cluster8 di server,
mentre il il MapReduce implementava tecnologie finalizzate alla computazione
distribuita.
Tali tecnologie si rivelarono fondamentali per il corretto funzionamento del motore di
ricerca, venendo utilizzate tutt’oggi in versione aggiornata. Inoltre destarono anche
l’interesse della comunità OpenSource, dalla quale ha avuto origine Apache
7
File System: Componente software che implementa logiche di gestione ed archiviazione dei file su memorie di
vario tipo.
8
Cluster: In inglese “grappolo”, indica un insieme di computer tra loro connessi.
24Hadoop, che si presenta come la versione opensource di queste tecnologie
proprietarie Google.
3.2 Le caratteristiche fondamentali di Apache Hadoop.
Apache Hadoop, che ha visto la sua nascita nel 2006, è un Framework9 scritto
prevalentemente10 in Java, finalizzato all’archiviazione e alla computazione distribuita
di grande mole di dati. E’ sviluppato da Apache Software, organizzazione noprofict
dedita allo sviluppo opensource.
Hadoop deve il suo nome a Doug Cutting, uno dei suoi principali creatori, il quale
suggerì di chiamarlo come il giocattolo preferito di suo figlio, un elefante peluche. Un
elefantino è ancora adesso logo rappresentativo del progetto.
9
Framework: Implementazione logica di un Design Pattern.
10
Piccole parti di Hadoop sono scritte in C.
25Apache Hadoop può essere visto come composto dai seguenti moduli fondamentali:
Hadoop Common
, che è un set di librerie e codici finalizzati ad una facile
implementazione ed utilizzo delle utility di Hadoop.
Hadoop Distribuited File System (HDFS)
, il quale è la versione di Apache del Google
File System visto che ne riprende la logica di fondo. HDFS provvede infatti a
memorizzare i file segmentandoli e dividendoli su un cluster.
Hadoop YARN
, che implementa una piattaforma finalizzata al managing delle risorse
computazionali di un cluster.
Hadoop MapReduce
, che implementa il modello per l’elaborazione distribuita su
vasta scala dei dati.
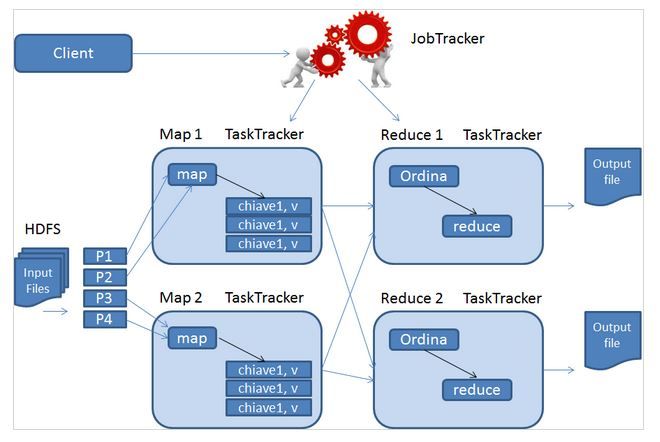
3.3 MapReduce: Come funziona.
“Divide et Impera
Il MapReduce lavora seguendo il paradigma ”11 . Infatti l’approccio
consiste, considerata una specifica operazione da effettuare, nello scindere tale
operazione in una sequenza di operazioni più semplici, in modo che le elaborazioni
associate possano essere delegate a vari computer costituenti un cluster ed
eseguite in parallelo. Una volta completata l’elaborazione, i risultati verranno poi uniti
generando il risultato finale.
11
Divide et Impera
: Approccio secondo il quale un problema va scisso in una sequenza di problemi minori che
poi vanno singolarmente affrontati.
26In particolare, il MapReduce fa utilizzo delle importanti funzioni Map() e Reduce()
della programmazione funzionale12 . Il comportamento di Map() e Reduce() può
essere definito in maniera generica come segue:
Map()
: Funzione che richiede come parametri di input una funzione ed una lista di
elementi. Riporta come output una lista di elementi che sono il risultato
dell’applicazione della funzione di input su ciascun elemento della lista passatale.
Reduce()
: Funzione che richiede come parametri di input una funzione ed una lista di
elementi. Riporta come output un solo elemento, ottenuto applicando alla lista la
funzione passatale come input.
Il MapReduce segue questi specifici step applicativi:
1. Da HDFS viene letta la serie di dati in input (il file) che è necessario elaborare.
2. Si applica su tali dati la funzione Map() ottenendo una serie di coppie
(chiave/valore).
3. Le coppie prodotte vengono raccolte ed ordinate per chiave. I valori associati
alla stessa chiave vengono raggruppati nel risultato (chiave/
valore1,valore2,...,valoreN).
4. Si applica poi la funzione Reduce() al risultato precedente, ottenendo il
risultato che è l’output dell’operazione di elaborazione.
5. Si salvano i risultati su HDFS.
12
La programmazione funzionale (talvolta programmazione orientata alle espressioni) è un tipo particolare di
pardigma di programmazione. Secondo questo paradigma i codici devono essere costituiti da una serie di
espressioni (insieme di operandi e valori) e le funzioni vengono viste come oggetti.
27Ma come ed a chi viene assegnata la responsabilità di esecuzione degli step
precedenti?
Il cluster di server può essere visto come un insieme di nodi connessi. I nodi possono
essere o Compute Nodes, se sono TaskTracker ossia semplici esecutori di task,
oppure Master Nodes, se invece fungono da JobTracker, ossia da nodi destinati a
gestire i nodi adiacenti attivandoli, disattivandoli ed indicando loro le operazioni da
effettuare.
Per ogni cluster tipicamente vi è un solo JobTracker, mentre i TaskTracker sono
sempre in funzione applicando gli step applicativi precedentemente descritti.
Il JobTracker sostanzialmente opera nella modalità seguente: una volta che un client
esplicita la necessità di eseguire una specifica operazione, questo attiva una serie di
TaskTracker in dipendenza alla loro vicinanza sui nodi HDFS che ospitano i file da
elaborare (fase di Map). I TaskTracker estraggono i i dati che devono elaborare,
applicano il Map() ed infine notificano al JobTracker il completamento del loro lavoro.
28Il JobTracker avvia a questo punto la fase di Reduce, in cui i TaskTracker ordinano i
risultati per chiave, li aggregano, eseguono la funzione Reduce(), e salvano il
risultato in vari file su HDFS.
Il funzionamento di MapReduce è certamente sofisticato, ma la sua potenza al
contrario è facilmente intuibile: questa risiede nel fatto che, essendo un Framework
(quindi una collezione di classi astratte), sta all’utilizzatore implementare le funzioni
Map() e Reduce(), e definire quali sono i file di input ed output.
In questo modo è possibile utilizzare MapReduce per eseguire in parallelo qualsiasi
tipologia di calcolo.
3.4 HDFS: Come funziona.
L’ Hadoop Distribuited File System è invece caratterizzato da un meccanismo di
funzionamento molto intuitivo. Come detto, l’HDFS permette l’archiviazione di file in
un cluster di computer che vengono visti come una sola unità di memorizzazione.
Un cluster può essere visto come composto da un insieme di nodi, dove ogni
computer è un nodo. I nodi possono essere di tipo DataNode, se destinati
semplicemente a conservare dati, oppure NameNode, se invece sono destinati a
finalità di managing dei nodi del cluster.
I NameNode hanno inoltre responsabilità di creazione, distruzione, modifica e lettura
dei file. Quando un file, ad esempio, deve essere creato questo viene diviso in
segmenti di 64 o 128 MB, i quali vengono poi distribuiti tra i vari DataNode del
29cluster, anche in maniera ridondante al fine di prevenire perdita di informazione
causata da guasti o malfunzionamenti.
I NameNode sanno poi come riassemblare i vari segmenti, ricomponendo il file per la
lettura.
3.5 Esempi di utilizzo.
Hadoop ha trovato vasta applicazione. Molte sono infatti le aziende che, attratte dalla
possibilità di poter processare in maniera efficiente grosse moli di dati, ne fanno
utilizzo. Le più rinomate sono sicuramente Yahoo e Facebook.
Yahoo, in particolar modo, ha investito molto nel progetto Hadoop aiutando Apache
Software nello sviluppo. Yahoo necessitava infatti di dover competere con Google, il
quale nel settore era chiaramente avvantaggiato.
Anche Facebook ha adottato questa tecnologia, trovando una maniera efficiente di
gestire la sempre più grande mole di dati che tutti i suoi utenti quotidianamente
producono (circa mezzo petabyte per giorno).
Ulteriore applicazione interessante proviene dagli Stati Uniti d’America. Il governo
federale americano ha infatti utilizzato Hadoop per realizzare un servizio di ricerca
che permettesse di recuperare in maniera efficiente informazione dagli oltre 500 siti
governativi americani esistenti.
30Capitolo 4: Cloudera
4.1 La Cloudera Inc.
Era il 2008 quando vide nascita la Cloudera Inc, società operante nel settore
dell’Information Technology con sede a Palo Alto, California. La Cloudera sarebbe
stata presto destinata ad attirare l’attenzione dei media: era infatti il 2009 quando si
guadagnò una menzione da parte del “The New York Times”, il quale riportò che tre
importanti ingegneri quali Christophe Bisciglia, Amr Awadallah e Jeff Hammerbacher
(rispettivamente da Google, Yahoo e Facebook) si erano uniti alla società. Seguirà
poi Doug Cutting, già citato perchè uno dei creatori di Apache Hadoop, unitosi al
team Cloudera poco più tardi.
Considerando l’esperienza maturata da Google, Yahoo e Facebook nel settore delle
gestione di grosse moli di dati e anche l’esperienza di Cutting, cocreatore di Hadoop,
è chiaro come queste figure professionali furono risorsa fondamentale per Cloudera,
la quale si era posta un interessante obiettivo: diventare azienda leader nel settore
delle piattaforme di gestione dei Big Data.
Questo mercato, secondo Cloudera, deve ancora raggiungere la sua piena
espansione, ma ha la possibilità di raggiungere un potenziale valore di 20 miliardi di
dollari.
E’ chiaro quindi perchè, negli ultimi anni, molti sono stati gli investitori che hanno
puntato su Cloudera, tra i quali probabilmente il più rinomato è la Intel Corporation,
che ha sovvenzionato la società effettuando un investimento di ben 740 milioni di
31dollari ed acquisendo un pacchetto azionario del 18%. Per Intel si tratta di un
investimento strategico visto che propone tipologie di processori appositamente
pensate per operare su cluster di server.
Ad oggi Coudera conta più di 300 clienti che utilizzano la soluzione a pagamento
Enterprise, che prende il nome di “Enterprise Data Hub”, la quale ha un costo che si
aggira tra i 5mila e 7mila dollari l’anno.
4.2 La distribuzione Hadoop di Cloudera: CDH.
Il prodotto più importante sviluppato da Cloudera è sicuramente CDH, acronimo di
Cloudera Distibution of Hadoop. Si tratta di una completa, testata, e popolare
distribuzione di Apache Hadoop curata da Cloudera.
Cloudera sostanzialmente ha creato un prodotto che affianca ad Apache Hadoop una
serie di componenti aggiuntive create adhoc per estendere le potenzialità di base
della piattaforma Apache.
32CDH, rispetto Hadoop, è caratterizzato dalle seguenti principali componenti
aggiuntive:
HBase
, che si pone come alternativa ad HDFS essendo un DB NoSQL distribuito,
scalabile ed orientato al collezionamento di grandi quantitativi di dati.
Impala
, che costituisce un potente engine SQL che permette l’utilizzo di questo
linguaggio per comunicare con Hadoop come se fosse un DB tradizionale.
Cloudera Search
, alternativa ad Impala, permette di comunicare con Hadoop non
facendo utilizzo di SQL, bensì facendo utilizzo di un classico sistema di ricerca
fulltext. Cloudera Search è basato su Apache Solr, noto DB orientato ai documenti,
molto utilizzato per implementare motori di ricerca.
Apache Spark
, engine per il processing su larga scala di dati. Questo si delinea come
una alternativa al MapReduce di Apache essendo un framework a questo
complementare.
33CDH è costituito per la maggior parte da codice OpenSource. Cloudera offre tuttavia
servizi di supporto ed assistenza che, con CDH, costituiscono la versione a
pagamento “Enterprise Data Hub”.
4.3 Esempi di utilizzo di CDH.
CDH sta trovando sempre una più frequente applicazione.
Un primo esempio di utilizzo proviene dalla Wayne Wheeles Sherpa Surfing che ha
utilizzato la distribuzione Hadoop di Cloudera per realizzare soluzioni di sicurezza per
reti DOD americane (Department Of Defence).
Altro interessante esempio di utilizzo viene da Montesanto, una società operante nel
settore delle biotecnologie per il settore agricolo, che ha utilizzato la soluzione di
ricerca fulltext “Cloudera Search” per ricercare all’interno delle proprie collezioni di
34dati alcune informazioni utili per tracciare la mutazione delle caratteristiche
descrittittive delle piante durante il loro ciclo di vita. A detta della società, questo
lavoro sarebbe stato impossibile facendo utilizzo del classico sistema di
interrogazioni tramite SQL.
4.4 L'alleanza con Teradata e SAP.
Nel settembre 2014 venne annunciata l'alleanza strategica di Cloudera con una nota
società operante nel settore della gestione ed analisi dei Data Warehouse13 per fini di
Business Intelligence: si tratta della Teradata Corporation.
Il prodotto principale di Teradata é il Teradata Integred Data Warehouse (TID): si
tratta della soluzione Data Warehouse prodotta da Teradata. L'alleanza delle due
società ha portato alla nascita del Teradata Unified Architecture, soluzione che
combina l'Enterprise Data Hub di Cloudera con il TID al fine di creare un unico
grande ecosistema di analisi. I vantaggi di questa soluzione sono deducibili andando
a sottolineare le differenze tra Data Warehouse (cuore delle soluzioni di Teradata) e
Big Data (cuore delle soluzioni Cloudera).
Un Data Warehouse, che nasce con lo specifico scopo di ospitare dati finalizzati ad
una loro analisi, é caratterizzato da un potenziale valore di interesse molto alto e da
una frequenza di aggiornamento dei dati alta. Al contrario, un Big Data può non
essere caratterizzato da un potenziale valore informativo definito quanto da una non
specifica frequenza di aggiornamento dei dati: il potenziale sta nella logica di analisi.
13
Data Warehouse: Archivio informatico contenente dati di una aziendaorganizzazione, ed orientato ad una
facile analisi dei dati costitenti per fini aziendalidecisionali.
35In generale, comunque, combinando entrambe le soluzioni, é possibile garantire
nuove tipologie di analisi e nuovi contenuti informativi.
La partnership non si é limitata solo alla creazione di questo nuovo prodotto software:
questa si è concretizzata anche in un approccio di rivendita unificato, in quanto
Tearadata ora è autorizzata a rivendere prodotti Cloudera, fare uso delle info di
Cludera finalizzate al supporto, potendo inoltre rivendere ai propri clienti le soluzioni
di supporto offerte da Cloudera.
36Altra alleanza strategica che vale la pena citare é quella che Cloudera ha posto in
essere con la SAP SE, altra società operante nel settore dell' IT famosa per aver
proposto il DBMS relazionale di nome HANA.
HANA é un DBMS un pò particolare, in quanto è caratterizzato dall’ essere
inmemory
ecolumnoriented
.
inmemory
Per si intende che questo DBMS privilegia il salvataggio dei dati in
memoria centrale e non in quella di storage (che viene utilizzata solo per salvare i
dati a lungo termine). In questo modo viene garantita una maggiore velocità di
consulta dei dati, rendendo anche più veloce l'elaborazione compiuta dai software di
columnoriented
analisi che si poggiano su questa piattaforma. Per invece si intende
che il salvataggio delle tabelle avviene salvando sezioni della tabella per colonna e
non per riga, come invece é solito. In questo modo viene reso più agevole l'attività di
analisi che deve processare molti dati della stessa colonna insieme.
SAP HANA include anche una serie di tools che permettono di sviluppare applicativi
che si poggiano su HANA in maniera rapida ed agevole.
Il problema principale di HANA é che soffre sulla scalabilità: in quanto non risulta
essere adatto per la gestione di una grossa mole di dati. In particolare SAP sconsiglia
di utilizzare HANA se l'ordine dei dati da gestire supera quello dei petabyte. In questo
caso infatti é meglio passare ad altre soluzioni come il CDH di Cloudera.
Hadoop, dal canto suo, sebbene adatto a computare una grossa mole di dati, risulta
svolgere praticamente le sue funzioni in maniera isolata e fortemente differente dagli
strumenti Business Intelligence più utilizzati e già utilizzati in contesti aziendali.
37Da qui nasce l'esigenza di integrare le due piattaforme realizzando una soluzione
ibrida. Cloudera suggerisce a tutte le aziende di introdurre Hadoop e di affiancarlo a
quello che é il vecchio sistema di Business Intelligence basato sui Data Warehouse:
sarà poi responsabilità dei tools di comunicazione, appositamente creati, instaurare
una comunicazione.
I vantaggi sottolineati da Cloudera, derivati da un approccio combinato, sono:
Data Exploration
: possibilità di analizzare i dati di Hadoop attraverso i tools SAP, in
quanto i tools Sap possono richiedere dati ad Hadoop attraverso SQL.
Advanced Analytics
: possibilità di ottenere analisi in maniera ancora più avanzata
preprocessando i dati provenienti da Hadoop tramite i tools di MapReduce e poi
inserendo ed elaborando i dati in SAP HANA. In questo modo é possibile ottenere
analisi ancora più performanti.
Big Data Data Warehouse and streaming real time Analytics
: si tratta della soluzione
che vede Hadoop alimentatrice informativa del Data Warehouse su cui poi si basano
i processi di analisi. È possibile inoltre creare segnali che riportano informazioni in
base allo streaming di dati tra Hadoop e Data Warehouse, ottenendo sempre info
sullo stato attuale della collezione di informazioni.
38Queste alleanze si sono rivelate molto importanti in quanto delineano quelle che sono
le strategie di business di Cloudera, come è evidenziato nel paragrafo seguente.
4.5 La strategia di business di Cloudera: investire nell'opensource.
Cloudera ha quindi raggiunto un notevole successo ed una discreta notorietà,
acquisendo parecchi clienti e trovando molte società disposte ad investire nei propri
prodotti. Tutti i partner sono infatti uniti nella visione di un futuro dove i Big Data sono
destinati ad avere sempre maggiore rilevanza.
Tuttavia, sebbene Cloudera non abbia problemi a trovare allo stato attuale investitori,
molte sono le persone che guardano con diffidenza questa azienda, accusandola di
avere strategie di business poco chiare.
Poco dopo la notizia dell'investimento multimilionario da parte di Intel, Dan Woods,
redattore per Forbes, ha infatti accusato la società di non avere strategie chiare per
competere con le altre aziende intenzionate a farsi strada nel settore.
39In sostanza il pensiero di Woods può essere riassunto come segue: come può una
società, che basa i propri prodotti su software opensource e caratterizzata da una
logica opensource di base, riuscire a garantire un ritorno economico considerevole?
Ed in generale come può Cloudera costruire una soluzione enterprise a capo di un
ecosistema opensource che non controlla? E’ anche solo difficile individuare i
competitors di Cloudera, dato che non sarebbero propriamente le società operanti su
Hadoop, quanto le società fornitrici di soluzioni di Business Intelligence nell'intorno a
ecosistemi di Data Warehouse, le quali sono sostanzialmente artefici di tools di
analisi proprietari forniti in utilizzo con licenza. Tali aziende sono caratterizzate quindi
da una chiara strategia di ritorno economico.
Le strategie di Business di Cloudera, stando alle varie interviste rilasciate dai CEO
durante gli scorsi anni, in realtà è deducibile e può essere vista come una filosofia
alternativa a tutte quelle dei propri concorrenti.
La prima strategia di base consiste nel continuare ad instaurare alleanze e
partnership con molte altre aziende operanti nel settore dell'IT, al fine di estendere e
accrescere le proprie conoscenze e le funzionalitá e potenzialità dei propri prodotti
software, ed anche di accrescere il proprio numero di clienti, dato che le aziende
alleate suggeriscono e sponsorizzano i prodotti dei propri partner ai propri clienti. Si
veda ad esempio la partnership con Intel, con Teradata, con SAP e l'acquisizione di
molte piccole StartUp avvenute negli ultimi anni.
La seconda strategia consiste nel reinvestire risorse, codici e denaro in Hadoop.
L'investimento in questo progetto opensource, a detta di Cloudera, non é
controproducente in quanto Hadoop è il cuore pulsante di CDH ed averlo “in salute”
non può che portare solo benefici. In questo modo, inoltre, Cloudera si assicura di
40Puoi anche leggere

















































