Docker: analisi sull'uso e sulla diffusione - AMS Tesi
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Alma Mater Studiorum · Università di
Bologna
SCUOLA DI SCIENZE
Corso di Laurea in Informatica
Docker: analisi sull’uso e sulla
diffusione
Tesi di Laurea in Informatica
Relatore: Presentata da:
Prof. Paolo Ciancarini Ciro,William,Giovanni Popolo
Correlatore:
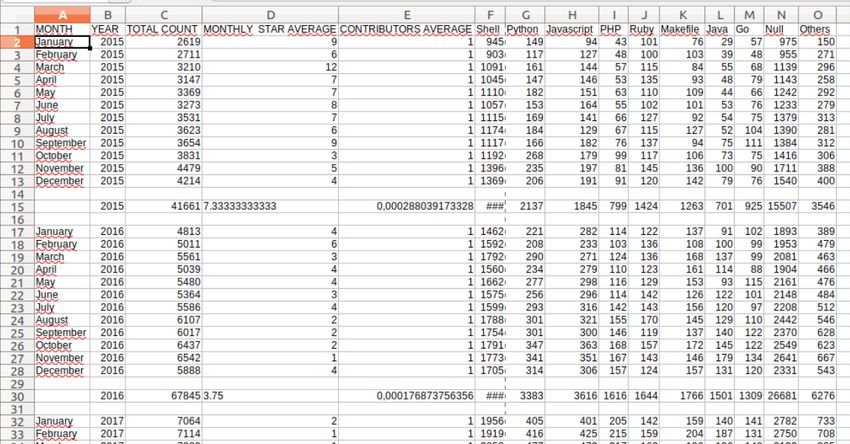
Dott. Francesco Poggi
MAR, 2018
Indice
1 Introduzione 1
1.1 Analisi dei risultati . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Ambienti di virtualizzazione 5
2.1 Ambiti della virtualizzazione . . . . . . . . . . . . . . . . . . . 5
2.2 Tecniche per la virtualizzazione . . . . . . . . . . . . . . . . . 7
2.3 Tecniche a confronto . . . . . . . . . . . . . . . . . . . . . . . 11
3 Docker: storia e caratteristiche principali 15
3.1 Virtualizzazione: dal giorno zero ad oggi . . . . . . . . . . . . 16
3.1.1 Docker Inc. : la storia . . . . . . . . . . . . . . . . . . 17
3.2 Caratteristiche dei container software . . . . . . . . . . . . . . 18
3.3 Elementi principali dell’architettura . . . . . . . . . . . . . . . 20
3.3.1 Docker Engine . . . . . . . . . . . . . . . . . . . . . . . 20
3.3.2 Ambiente e Filesystem . . . . . . . . . . . . . . . . . . 21
3.3.3 DockerFile . . . . . . . . . . . . . . . . . . . . . . . . 21
3.3.4 Docker Compose . . . . . . . . . . . . . . . . . . . . . 22
3.4 Dalla definizione all’esecuzione . . . . . . . . . . . . . . . . . . 24
3.5 Caratteristiche Docker . . . . . . . . . . . . . . . . . . . . . . 25
4 Creazione del dataset: github mining 29
4.1 Github . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.1.1 Breve storia . . . . . . . . . . . . . . . . . . . . . . . . 31
4.1.2 Api github . . . . . . . . . . . . . . . . . . . . . . . . . 31
i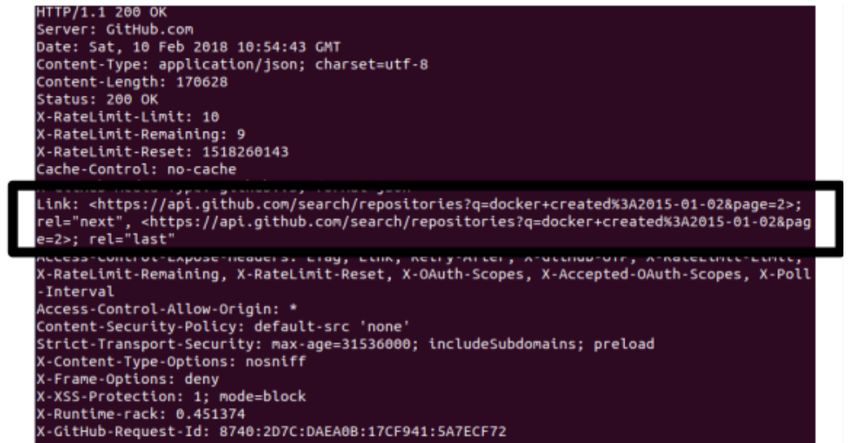
ii INDICE
4.1.3 Limitazioni . . . . . . . . . . . . . . . . . . . . . . . . 35
4.2 Tecnologie ausiliarie . . . . . . . . . . . . . . . . . . . . . . . . 35
4.2.1 Scraping e XPATH . . . . . . . . . . . . . . . . . . . . 36
4.3 Implementazione script . . . . . . . . . . . . . . . . . . . . . . 37
4.3.1 Il repository ’statisticsfromgithub’ . . . . . . . . . . . . 39
4.3.2 Uso del tool per personalizzare le ricerche . . . . . . . 40
4.4 Progettazione script . . . . . . . . . . . . . . . . . . . . . . . . 43
4.4.1 Scelta informazioni da analizzare . . . . . . . . . . . . 45
4.4.2 Studio per una ricerca automatica . . . . . . . . . . . . 46
5 Analisi 49
5.1 Uso linguaggi . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.2 Feedback per repository . . . . . . . . . . . . . . . . . . . . . 55
5.3 Attività legate ai repository . . . . . . . . . . . . . . . . . . . 58
5.4 Categorizzazione dell’uso di container docker . . . . . . . . . 65
Conclusioni 73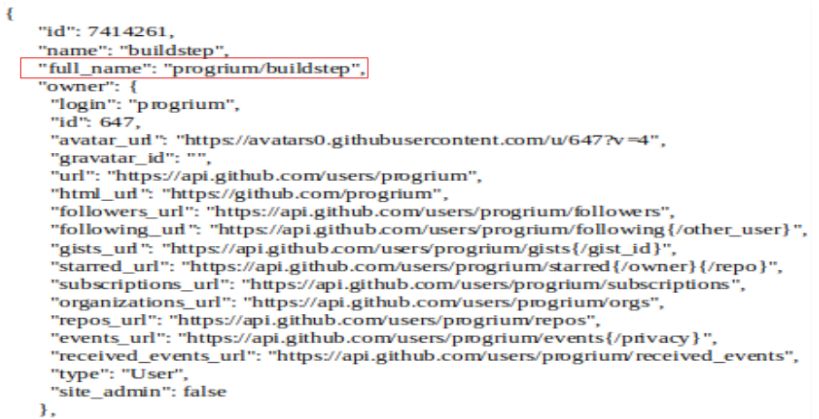
Elenco delle figure
2.1 Esempio di Hypervisor Type 1 . . . . . . . . . . . . . . . . . . 8
2.2 Esempio di Hypervisor Type 2 . . . . . . . . . . . . . . . . . . 9
2.3 Virtualizzazione Hardware . . . . . . . . . . . . . . . . . . . . 10
2.4 Virtualizzazione System-Level . . . . . . . . . . . . . . . . . . 11
2.5 Virtualizzazione Hardware vs System-Level . . . . . . . . . . . 12
3.1 Architettura Docker . . . . . . . . . . . . . . . . . . . . . . . 20
3.2 Esempio di DockerFile . . . . . . . . . . . . . . . . . . . . . . 22
3.3 Esempio di Docker-Compose . . . . . . . . . . . . . . . . . . . 23
4.1 esempio lista JSON (pt.1) . . . . . . . . . . . . . . . . . . . . 33
4.2 esempio lista JSON (pt.2) . . . . . . . . . . . . . . . . . . . . 34
4.3 Esempio pagina github di un repository . . . . . . . . . . . . . 37
4.4 Architettura del software prodotto . . . . . . . . . . . . . . . 39
4.5 Esempio di risultato per l’esecuzione del tool . . . . . . . . . 41
4.6 intestazione del file ’impl url’ . . . . . . . . . . . . . . . . . . 42
4.7 lista repository analizzati . . . . . . . . . . . . . . . . . . . . 44
4.8 Esempio di informazioni interessanti di un progetto . . . . . . 46
4.9 Esempio di risposta ad api con campo -I . . . . . . . . . . . . 47
5.1 diffusione uso linguaggi . . . . . . . . . . . . . . . . . . . . . 51
5.2 dati che popolano grafico di figura 5.1 . . . . . . . . . . . . . 52
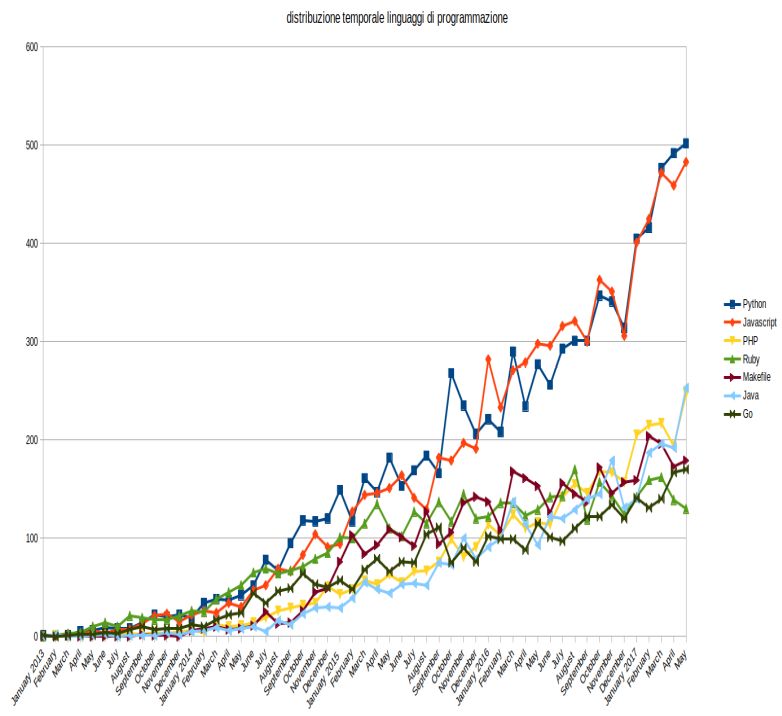
5.3 uso linguaggi dal 2013 al 2017 . . . . . . . . . . . . . . . . . . 53
5.4 calo feedback community . . . . . . . . . . . . . . . . . . . . 55
iii
iv ELENCO DELLE FIGURE
5.5 dati che popolano grafico di figura 5.4 . . . . . . . . . . . . . 56
5.6 andamento media stelle dal 2013 al 2017 . . . . . . . . . . . . 57
5.7 andamento attività per repository . . . . . . . . . . . . . . . 59
5.8 dati che popolano grafico di figura 5.7 . . . . . . . . . . . . . 60
5.9 media commit dal 2013 al 2015 . . . . . . . . . . . . . . . . . 61
5.10 media commit 2016/2017 . . . . . . . . . . . . . . . . . . . . 62
5.11 repository non più attivi dal 2013 al 2015 . . . . . . . . . . . 63
5.12 dati che popolano grafico di figura 5.11 . . . . . . . . . . . . . 65
5.13 percentuale categorie in base al numero repository . . . . . . 68
5.14 percentuale categorie dettagliate in base al numero repository 69
Capitolo 1
Introduzione
Questa tesi studia i docker, una delle principali e più recenti tecnologie di
virtualizzazione per automatizzare il deployment di applicazioni all’interno
di container software. L’obiettivo di questo lavoro è analizzare la diffusione e
caratterizzare l’uso dei docker attraverso l’analisi dei progetti della piattafor-
ma github. Con la parola docker si intende un container software generato
dalla piattaforma docker. Docker è una piattaforma che sfrutta una vir-
tualizzazione del livello sistema operativo, per rispondere in modo efficiente,
usando un ambiente leggero ed isolato, a problemi quali dipendenze software,
versioning e altri problemi legati al software deployment. Un container e in-
vece un ambiente con proprie dipendenze, librerie e file di configurazione;
quindi un container è un pacchetto che consiste in un’applicazione, la quale
viene eseguita dal sistema operativo che crea un ambiente isolato rispetto a
tutti gli altri processi e vi installa librerie e configurazioni indicate.
Il lavoro che ho svolto si è concentrato prima sul capire cos’è docker e sul
concetto di container, successivamente sono andato ad analizzare l’uso e la
diffusione della tecnologia. Per poter capire docker e il concetto di contai-
ner in primo luogo mi sono concentrato sullo studio della virtualizzazione, in
particolare sui motivi che hanno portato alla nascita ed alla rapida diffusione
di tale tecnologia, alle varie tecniche disponibili per attuare una virtualizza-
zione come la virtualizzazione hardware o la virtualizzazione ‘ system-level
1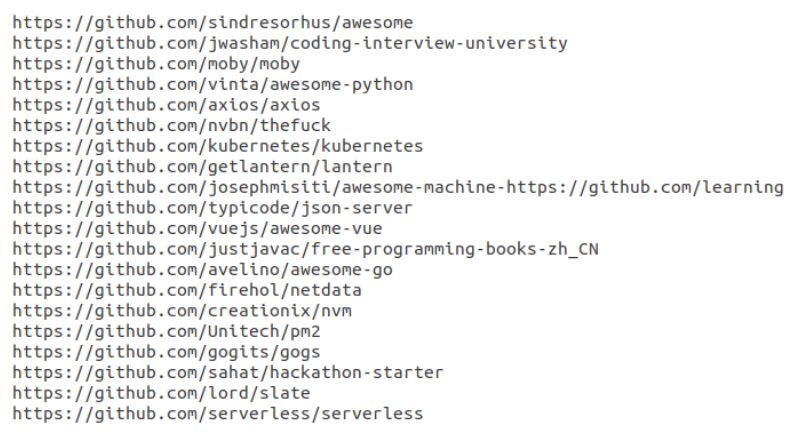
2 1. Introduzione
’, e a un confronto tra le tecniche evidenziandone le differenze.Il passo suc-
cessivo è stato analizzare le tecnologie e le caratteristiche della piattaforma
docker. Dopo aver studiato la storia della compagnia Docker Inc. che ha
sviluppato la piattaforma, ho analizzato le principali motivazioni che hanno
portato allo sviluppo di questa nuova tecnologia (ad esempio l’inferno delle
dipendenze, la documentazione imprecisa, il codice obsoleto o i problemi di
portabilità) e gli elementi principali dell’architettura docker (docker-engine,
filesystem e ambiente usato, dockerfile e docker-compose). Successivamente,
ho confrontato l’approccio proposto basato su docker con quelli delle prin-
cipali tecnologie di virtualizzazione esistenti. Una volta fatto questo quadro
completo sulla piattaforma mi sono concentrato sull’analisi dei progetti che
usano la tecnologia docker caricati sulla piattaforma github. A questo scopo
ho sviluppato un’applicazione per filtrare fra i 79 milioni di progetti quelli
che fanno uso di docker, e fare mining delle principali informazioni ad essi
relative. Github per non sovraccaricare i propri server di richieste da parte
di utenti limita a questi ultimi l’uso delle api, in termini di tempo con il
rate-limit e di risultati con la paginazione. Oltre ad uno studio della docu-
mentazione di github ho effettuato uno studio sulla piattaforma, usandola e
sfogliando alcuni repository interessanti per la mia analisi. Per popolare il
dataset da andare ad analizzare ho progettato un algoritmo che interrogasse
il sistema di github tramite l’uso delle api REST, rispettando le limitazioni
da esso imposte. In particolare l’algoritmo non si limita ad analizzare tutti
gli elementi della lista JSON ma anche tutte le pagine html ad essi riferite.
Il programma da me progettato una volta analizzati tutti gli elementi della
lista appena citata e le relative pagine html elabora i dati raccolti e stila
una serie di statistiche per poi andare a stamparle in un foglio di calcolo.
Successiva alla realizzazione dello script è stata la sua esecuzione e il relativo
studio dei risultati. In totale per l’analisi sono stati analizzati circa 200000
repository e solo per l’esecuzione del programma ci sono voluti ben 5 giorni.
Tra le statistiche stilate ci sono: numero repository, media stelle mensile,
media partecipanti per repository, numero di repository creati per ogni lin-
1.1 Analisi dei risultati 3 guaggio, media commit mensile e media commit per numero di repository. Con il seguente programma sarà inoltre possibile personalizzare la propria ricerca infatti è implementato per accettare vari argomenti tra cui la parola chiave, che nel caso della mia analisi sarà settata a docker, oltre alla parola chiave è possibile inserire l’anno in cui far iniziare la ricerca e l’anno in cui far terminare la ricerca, che nella mia analisi saranno 2013 e 2017. Sarà inoltre possibile inserire il percorso riguardante la directory nella quale lavorare. 1.1 Analisi dei risultati Una volta terminata l’esecuzione ho potuto visionare i risultati riguar- danti le statistiche stilate e ho potuto organizzarli in grafici, per andare a sottolineare alcuni aspetti che ho trovato interessanti, soprattutto per quanto riguarda i linguaggi utilizzati, le stelle e i commit. Alcune statistiche sono risultate alla fine poco interessanti, come la media dei partecipanti ad un re- pository, quindi ho deciso di oscurarle nei grafici ma comunque faranno parte delle statistiche raccolte nel foglio di calcolo. Per concludere l’analisi mi sono focalizzato su alcuni repository che usano docker per capire a che scopo lo fanno e come docker rende il raggiungimento di tale scopo migliore rispetto ad un’ altra tecnologia. Ho quindi visionato e studiato circa 50 repository, manualmente, per cercare di carpire gli usi che vengono fatti di docker da parte degli utenti della community. Dopo questo faticoso lavoro sono riuscito ad individuare degli usi tipici che vengono fatti di docker e sono cosı̀ potuto andare a categorizzare tali usi come: soluzione alle dipendenze, ambiente di test, gestore container, composizione container, estensione docker. Inoltre ho anche individuato il fatto che molti progetti che fanno uso di docker rica- dano in varie categorie delle appena citate e che alcune categorie consistano nello stesso uso di docker da parte dell’utente ma con un fine diverso, sarà il caso di soluzione alle dipendenze e ambiente di test. Concludo la tesi con una discussione finale sull’ analisi e sul lavoro svolto. In particolare la tesi è articolata come segue:
4 1. Introduzione
• Capitolo 2: introduce la virtualizzazione, descrive le tecniche per
attuarla e le confronta.
• Capitolo 3: presenta la storia riguardante la nascita e lo sviluppo della
virtualizzazione e della piattaforma docker, descrive le motivazioni che
portano alla nascita della piattaforma, le principali caratteristiche e i
principali elementi dell’architettura della piattaforma.
• Capitolo 4: introduce gli strumenti adoperati per l’analisi tra cui
github, le api che mette a disposizione e le limitazioni su esse, lo
scraping e il linguaggio xpath, descrive la progettazione del program-
ma usato per svolgere l’analisi, dall’implementazione all’esecuzione alla
personalizzazione.
• Capitolo 5: descrive l’analisi effettuata, i risultati raccolti sotto forma
di grafici, una categorizzazione dell’uso di docker.
• Conclusioni: descrive una discussione sull’analisi effettuata e sulle più
interessanti osservazioni emerse.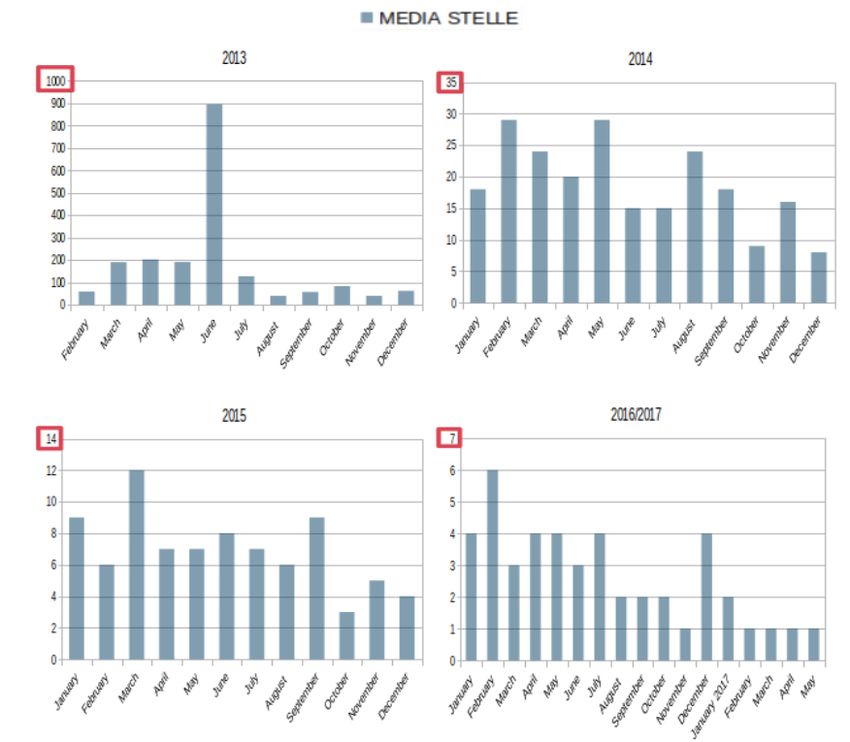
Capitolo 2
Ambienti di virtualizzazione
Nel seguente capitolo sarà introdotto il concetto di virtualizzazione in con-
comitanza con l’introduzione dei problemi che hanno portato alla necessità
di una qualche tecnica di virtualizzazione. Oltre al concetto di virtualizza-
zione sarà introdotto quello di hypervisor, componente fondamentale quando
si parla di virtualizzazione e soprattutto di tecniche di virtualizzazione, e
dei due tipi di hypervisor diffusi ai giorni nostri. Successivamente saranno
introdotte e confrontate le principali tecniche per attuare una virtualizzazio-
ne e saranno sottolineati vantaggi e svantaggi a cui una diversa tecnica di
virtualizzazione può condurre.
2.1 Ambiti della virtualizzazione
Per avere una panoramica generale sulla virtualizzazione vado ad intro-
durre alcuni dei principali motivi che portano al bisogno di questa tecnica, tra
questi ci sono: affidabilità del sistema operativo e dei servizi, alti costi di ma-
nutenzione hardware, impossibilità di eseguire applicazioni legacy, mancanza
di sicurezza dati in caso di guasti, difficoltà nello scalare le risorse. Ognu-
no di questi problemi viene risolto o limitato dalla virtualizzazione in modo
efficacie, tanto che al giorno d’oggi è una delle pratiche più usate in ambito
56 2. Ambienti di virtualizzazione
test o server. Per quanto riguarda i problemi citati prima la virtualizzazione
offre delle soluzioni semplici ed efficaci :
• Affidabilità: l’uso della virtualizzazione limita l’inaffidabilità del si-
stema operativo e/o dei servizi infatti è possibile configurare una mac-
china virtuale affinché esegua solo pochi servizi, che non vadano in
conflitto tra loro, ed in caso di problemi sarà compromesso solo l’uso di
quella macchina virtuale e non di altri sistemi(altre macchine virtuali,
sistema host).
• Manutenibilità: i costi legati alla manutenzione dell’hardware ven-
gono ridotti tramite l’uso della virtualizzazione, in quanto è possibile
eseguire più sistemi operativi contemporaneamente su una sola mac-
china fisica, ciò significa che il bisogno di nuovo hardware si riduce,
riducendo notevolmente i costi. Oltre ad una riduzione dei costi rela-
tivi a nuovo hardware la virtualizzazione garantisce una riduzione dei
costi derivanti dall’hardware stesso, quali: energia elettrica e spazio e
manutenzione.
• Compatibilità: la virtualizzazione rende possibile l’esecuzione di ap-
plicazioni legacy. Molte applicazioni funzionano solo su hardware ob-
soleto, per permettere il loro funzionamento su un hardware recente
o semplicemente non supportato c’è bisogno di una migrazione della
stessa applicazione verso un’architettura attuale, con relativi costi di
porting e debug. Con l’uso della virtualizzazione sarà possibile ripro-
durre qualsiasi hardware, eliminando il problema dell’impossibilità di
eseguire un’applicazione non supportata da una certa architettura e
inoltre eliminando i costi di porting e debug.
• Sicurezza: l’uso della virtualizzazione garantisce maggiore sicurezza
dei dati in caso di guasti. Eseguire il backup di una macchina virtuale,
a differenza dell’eseguirlo di una macchina fisica, è una compito che
richiede poco impegno sia per quanto riguarda il tempo che le risor-
se impiegate. Anche ripristinare una macchina virtuale, a differenza2.2 Tecniche per la virtualizzazione 7
del ripristinare una macchina fisica , richiederà un impegno basso,un
disaster recovery può essere immediato.
• Scalabilità e ottimizzazione risorse: la difficoltà nello scalare le
risorse è notevolmente limitata dall’uso della virtualizzazione. Aggiun-
gere o rimuovere delle risorse ad una macchina fisica può essere difficol-
toso, ciò comporta il dover mettere mano all’hardware della macchina in
modo opportuno. Con l’uso di una macchina virtuale questa difficoltà
è eliminata in quanto sarà possibile aggiungere o rimuovere risorse con
un semplice click, ovviamente limitatamente alle risorse della macchina
fisica che ospita la macchina virtuale in questione.
2.2 Tecniche per la virtualizzazione
La virtualizzazione è un meccanismo che permette di eseguire più siste-
mi operativi su una sola macchina contemporaneamente. È una tecnica che
nasce nei lontani anni ‘60 in IBM. Questa tecnica nell’ ultimo ventennio
ha avuto una forte ascesa e praticamente tutte le più grandi compagnie nel
campo informatico hanno investito ingenti capitali nello sviluppo della tec-
nologia. La virtualizzazione rappresenta un concetto chiave quando si parla
di Docker, ci sono diverse tecniche per la virtualizzazione ed essa è usata nei
più disparati ambiti oramai, dati i notevoli vantaggi a cui essa può portare.
Prima di stabilire quali siano le diverse tecniche per attuare virtualizzazione
bisogna introdurre il concetto di Virtual Machine Monitor (VMM) o
Hipervisor: può essere un software, un firmware o un hardware capace
di comunicare sia con il sistema operativo che con l’hardware di una mac-
china fisica. Gestisce l’allocazione delle risorse, come memoria o larghezza
di banda , tra la macchina fisica e le macchine virtuali permettendo cosı̀ la
coesione di più sistemi operativi contemporaneamente su una sola macchina
fisica. Il concetto di hypervisor nasce tra la fine degli anni ‘60 e l’inizio degli
anni ‘70 in IBM ma la maggior diffusione si ha intorno agli anni 2000 in8 2. Ambienti di virtualizzazione
concomitanza con la diffusione della virtualizzazione e delle varie tecniche di
virtualizzazione. Oggi si distinguono due tipi di hypervisor:
• Type 1 Hypervisor: lavora direttamente sul livello hardware della
macchina fisica e gestisce i sistemi operativi dei livelli più alti come
mostrato in figura 2.1. Risiedendo sul livello hardware questo tipo di
hypervisor è completamente indipendente dal sistema operativo. L’hy-
pervisor ha dimensioni molto ridotte e il suo compito principale è quello
di gestire la condivisione delle risorse hardware tra i sistemi operativi
ospiti. Il vantaggio principale di questo tipo di hypervisor è che se si
dovesse avere un guasto ad una macchina virtuale o a uno dei sistemi
operativi guest, tale guasto non viene propagato alle altre macchine vir-
tuali né al sistema operativo host. Microsoft Hyper-V, VMWare ESXi
Server, Citrix/Xen Sever sono tra le piattaforme che usano hypervisor
type 1 le più diffuse.
Figura 2.1: Esempio di Hypervisor Type 1
• Type 2 Hypervisor: questo tipo di hypervisor a differenza del pre-
cedente lavora un livello sopra il sistema operativo host e supporta la
presenza di altri sistemi operativi a livelli superiori. Il fatto che l’hy-
pervisor risieda sul sistema operativo host, come mostrato in figura 2.2,2.2 Tecniche per la virtualizzazione 9
rende l’hypervisor completamente dipendente da tale sistema. Se da un
lato adoperando questo tipo di hypervisor si ha un controllo maggiore,
risiedente nel sistema operativo host, dall’altro lato ciò comporta che
un guasto nel sistema operativo host si ripercuote nei sistemi operativi
guest. Tra le piattaforme più diffuse che usano hypervisor type 2 ci
sono VMWare Workstation,Microsoft Virtual PC, Oracle Virtual Box.
Figura 2.2: Esempio di Hypervisor Type 2
Era doveroso introdurre il concetto di hypervisor prima di parlare delle
tecniche di virtualizzazione, dato che le differenze tra le tecniche saranno
dovute anche alla presenza di questo componente. Le tecniche di virtua-
lizzazione più diffuse oggi sono la virtualizzazione del livello hardware e la
virtualizzazione del livello sistema operativo,con differenze sostanziali che
mostro di seguito:
• Virtualizzazione Hardware: consiste nell’emulare un certo hard-
ware ed installarvici un sistema operativo , quindi costruire una mac-
china virtuale, viene mostrato in figura2.3. I due sistemi operativi rie-
scono a coesistere contemporaneamente grazie al hypervisor, che può
essere sia di tipo 1 che di tipo 2, il quale si occupa di gestire l’alloca-
zione delle risorse ai vari sistemi operativi, isolare le diverse macchine10 2. Ambienti di virtualizzazione
virtuali e garantire la stabilità dei sistemi operativi, il tutto inserendo
un overhead. La virtualizzazione consente tra le altre cose di ridurre
il numero di macchine fisiche in funzione abbattendo i costi di energia
elettrica e di hardware. In genere bisogna attivare la possibilità di ave-
re una macchina virtuale nel BIOS della macchina fisica. La tecnica
di virtualizzazione del hardware è la più diffusa ma ci sono dei punti
deboli. Tra i software più diffusi che usano questa tecnica di virtualizza-
zione troviamo Virtual Box(Oracle), Android Studio(Google), Vmware
(Dell), Virtual PC (Microsoft) tutte con le loro precise caratteristiche
ma in generale per lo stesso scopo.
Figura 2.3: Virtualizzazione Hardware
• Virtualizzazione ‘System-Level’: sfrutta il concetto di container,
cioè un contenitore indipendente dal sistema operativo con proprie li-
brerie e configurazioni. Il sistema operativo ospitante crea uno spazio
isolato dal resto dei processi e ci esegue il container. Questa tecni-
ca, detta anche “containerizzazione”, come la precedente garantisce un
risparmio in termini di costi e un uso più efficiente delle risorse ma2.3 Tecniche a confronto 11
stavolta senza l’intervento di un VMM. Questo tipo di virtualizzazione
è molto usata in ambito di hosting virtuale dove è utile per allocare
risorse finite tra un elevato numero di utenti. Un altro tipico uso che si
fa di questa tecnica e da parte degli amministratori di sistema i quali
possono decidere di incapsulare i vari servizi di un server in vari con-
tenitori diversi su quel server, con il fine di rafforzare l’hardware del
server. Le differenze con la virtualizzazione hardware sono molteplici,
la più significativa è che mentre nella prima ogni sistema ha il suo ker-
nel e l’hypervisor gestisce le risorse, nella seconda il kernel è uno solo
ed è quello del sistema host apportando vantaggi significativi. In figura
2.4 mostro un esempio:
Figura 2.4: Virtualizzazione System-Level
2.3 Tecniche a confronto
Entrambe le tecniche, in base all’uso che se ne deve fare, possono avere
i propri vantaggi; installare un sistema operativo può essere un’operazione
lunga e faticosa,inoltre ogni livello dell’architettura introduce un overhead.12 2. Ambienti di virtualizzazione
Quindi se da un lato abbiamo due ( o più ) sistemi operativi e i sistemi vir-
tuali meno efficienti del sistema host, la possibilità di creare più macchine
virtuali ,limitatamente alle risorse fisiche disponibili. Dall’ altro lato abbia-
mo un sistema operativo incapsulato in un processo del nostro sistema host,
con il quale condivide il kernel, cancellando overhead introdotto dai livelli
hipervisor e OS host e eliminando difficoltà varie di installazione e gestione
di un sistema operativo. Un container racchiude in sè solo librerie richieste
dalla funzione che esso stesso deve svolgere, quindi le sue dimensioni sono
molto ridotte rispetto ad una macchina virtuale. Le dimensioni ridotte di un
container consentono l’esecuzione di un numero di container maggiore rispet-
to al numero di macchine virtuali eseguibili contemporaneamente a parità di
hardware fisico. In figura 2.5 mostro un confronto fra le due tecniche:
Figura 2.5: Virtualizzazione Hardware vs System-Level
Docker quindi è una piattaforma che utilizza una tecnologia di virtualiz-
zazione system level e la rende ‘user-friendly’ [1]. Un concetto fondamentale
quando si parla di docker, o di virtualizzazione in generale, è l’immagine.
Un’immagine è un file che contiene l’istantanea di un contenitore, o di un
intero sistema operativo. Sia un contenitore che una macchina virtuale sono2.3 Tecniche a confronto 13 l’istanza di un’ immagine, le azioni più diffuse per quanto riguarda un’imma- gine sono salvataggio e condivisione. Nel capitolo successivo sarà evidenziata prima la diffusione delle tecniche di virtualizzazione e poi quella di docker, successivamente sarà introdotto il contesto nel quale un container docker entra in funzione, le principali componenti della sua architettura e alcune caratteristiche. Per terminare sarà fatto un accenno sul funzionamento e sull’uso di un container docker.
14 2. Ambienti di virtualizzazione
Capitolo 3
Docker: storia e caratteristiche
principali
Il seguente capitolo espone una panoramica generale sui container docker,
partendo dalla storia della compagnia Docker Inc., non prima di aver mo-
strato la fulminea ascesa della virtualizzazione come tecnica general purpo-
se. Verranno successivamente analizzati alcuni dei principali problemi legati
al software deployment e i modi di affrontarli usando docker. Successiva-
mente sarà introdotta l’architettura e le principali componenti che popolano
la piattaforma. Nelle sezioni successive si osserverà il funzionamento della
piattaforma, alcuni esempi di comandi per usare i container docker e per
concludere uno sguardo alla modalità swarm e alla possibilità di comporre
container per realizzare applicazioni basate su micro-servizi. Bisogna infatti
fare una distinzione che sarà fondamentale nel parlare di container software,
tra applicazioni monolitiche e applicazioni basate su microservizi.
• Applicazioni monolitiche: hanno la principale caratteristica di avere
tutte le funzioni in un unico componente. Questa caratteristica tende
a generare componenti sempre più complessi e difficili da gestire con
il passare del tempo. Il problema principale di questo approccio è
che, per applicazioni di grandi dimensioni, diventa molto difficile capire
dove una determinata funzione è implementata. Questo problema porta
1516 3. Docker: storia e caratteristiche principali
spesso ad introdurre ridondanze. Un altro problema si riscontra in caso
di guasti, infatti si perderanno tutte le funzionalità della applicazione
qualora una sola di esse subisca un guasto.
• Applicazioni basate su microservizi: la principale caratteristica
che le differenzia dalle applicazioni monolitiche è che in questo tipo di
applicazioni sono presenti più componenti. Ognuno di questi compo-
nenti sviluppa una funzionalità dell’applicazione ed è indipendente dalle
altre componenti. Le componenti posso comunicare tra loro tramite il
protocollo REST per scambiarsi informazioni utili allo svolgimento di
una funzionalità. I vantaggi di un approccio del genere sono molteplici
: scalabilità dell’applicazione, resistenza in caso di guasti ad un com-
ponente. Bisogna anche pensare che la gestione della comunicazione
tra le componenti dell’applicazione può non essere semplice. Per citare
alcune compagnie, Netflix e Spotify adottano un approccio basato su
microservizi.
La nascita di Docker come piattaforma per l’uso di container è una diretta
conseguenza della vastissima diffusione che la virtualizzazione ha avuto nel
corso degli ultimi anni. Come descritto nelle sezioni successive l’apice di
attenzione sulla nuova tecnologia si raggiunge intorno agli anni 2000.
3.1 Virtualizzazione: dal giorno zero ad oggi
Il giorno zero per la virtualizzazione è rappresentato dall’ uscita dell’IBM
System/370 nel Gennaio del 1970, questo sistema fu il primo che offriva a
diversi utenti la possibilità di avere una copia personale del sistema in esecu-
zione su un’ unica macchina fisica(mainframe all’epoca). Questa innovativa
funzione era permessa grazie alle componenti Virtual Machine(VM) e Con-
versational Monitor System(CMS) . Oltre a questo evento fanno parte della
“preistoria” della virtualizzazione altri due avvenimenti, lo sviluppo del pri-
mo Virtual Machine Monitor (VMM) chiamato “Simultask” da parte della3.1 Virtualizzazione: dal giorno zero ad oggi 17 Locus Computing Corp. (1985) e lo sviluppo del primo emulatore di sistema MS-DOS su sistema Unix da parte di Insigna Solutions con il nome di Soft- PC(1988). Intorno agli anni 2000 si concentrano la maggior parte degli eventi che hanno segnato la storia e l’ascesa della virtualizzazione,in successione, nasce VMware(1998) oggi una delle compagnie leader in campo di virtualiz- zazione,viene pubblicata Virtual PC (2001)per windows da parte di Connec- tix,successivamente acquisita da Microsoft(2003),Intel e AMD aggiungono il supporto alla virtualizzazione nei loro processori(2005) , le piattaforme ven- gono rilasciate gratuitamente e hypervisor presente su tutte le macchine per lanciare macchina virtuale da desktop(2008) , sviluppo di Android Studio da parte di Google e Docker da parte di Docker Inc. (2013) .Al giorno d’oggi la virtualizzazione è una tecnica usata per risolvere molti problemi, è stata proprio questa sua caratteristica general purpose a rendere la sua diffusione cosı̀ vasta. Questa tecnica è utilizzata per diversi scopi , c’è chi la usa per rendere ‘portabili’ le proprie applicazioni come Java Virtual Machine(JVM), che può essere installata su qualsiasi sistema operativo moderno e permet- te l’esecuzione di applicazioni scritte in Java,o chi rende questa tecnica di virtualizzazione user-friendly , cioè permette a chiunque di creare la propria macchina virtuale, con il sistema operativo che si è scelto,bisognerà però pos- sedere l’immagine del sistema operativo. Di quest’ ultima categoria abbiamo notevoli esempi ma le piattaforme più diffuse sono senza dubbio Vmware (piattaforma leader nel settore indicata anche per tramutare una macchina fisica in una macchina virtuale) , VirtualBox (piattaforma compatibile con ogni sistema operativo e con configurazioni Vmware) . 3.1.1 Docker Inc. : la storia Docker nasce nel 2013 da un progetto open-source della compagnia dot- Cloud,impegnata nel campo del “platform-as-a-service”, il linguaggio scelto per il progetto fu GO (sviluppato da Google con sintassi simile a C) . Ini- zialmente la compagnia si concentrò sulle tecnologie cloud ma solo per pochi mesi. La svolta la diede l’avvento di Solomon Hykes,il nuovo CEO , che in
18 3. Docker: storia e caratteristiche principali
poco tempo rivoluzionò la compagnia modificando il nome della stessa in
Docker Inc. e spostando l’interesse dell’intera compagnia sullo sviluppo di
questa nuova tecnologia[2]. Nel giro di pochi mesi la tecnologia suscita un
interesse tale da portare la compagnia, prima a un importante accordo con
Red Hat nel settembre del 2013 , e poi alla collaborazione con Microsoft
nell’ottobre del 2014.Parallelamente nasce anche il progetto open-source Ku-
bernetes di Google , ormai tutto il mondo aveva messo gli occhi su Docker.
Nascono presto i primi attriti tra compagnia e vendor,la volontà di rendere
i container docker affiancabili ad altre soluzioni tipo Kubernetes(Red Hat)
o Amazon EC2 da parte dei vendor porta la società Docker a proseguire in
maniera autonoma allo sviluppo della tecnologia. Il punto di non ritorno si
raggiunge nell’estate del 2016 [3] quando Docker annuncia l’implementazione
di swarm, la propria soluzione di orchestrazione di container; a questo punto
Red Hat presenta OCID(Open Container Initiative Daemon) considerato da
molti un fork parziale di docker, la scissione tra le società non si concre-
tizza ma di fatto avviene. Un cambiamento rilevante si ha quando Docker
decide di rendere pubblico il codice sorgente di alcune componenti alla base
della tecnologia, mediante donazione alla Cloud Native Computing Foun-
dation(progetto collaborativo della Linux Foundation lanciato nel 2015) nel
marzo del 2017, questa mossa garantirà alla piattaforma la compatibilità con
soluzioni di terze parti. Questo cambiamento porterà ad affievolirsi l’attrito
con i vendor anche se la divisione interna continuerà ad esistere.
3.2 Caratteristiche dei container software
Per capire lo scopo di docker bisogna dare uno sguardo ad alcuni dei
principali problemi legati al software deployment e alla soluzione adottata
da docker per risolverli o aggirarli , di seguito prenderò in considerazione
alcuni problemi noti e ne mostrerò la soluzione pensata da docker per il
problema stesso.
• Inferno delle dipendenze: ho perso il conto ormai delle volte in cui3.2 Caratteristiche dei container software 19
ho provato ad installare un software e non ci sono riuscito per un proble-
ma di dipendenze,un problema molto comune e allo stesso tempo senza
una soluzione standard. Il problema è che installare un’applicazione ri-
chiede,spesso, l’installazione di software aggiuntivo per funzionare;ogni
applicazione richiede la creazione di un ambiente specifico per eseguire
i suoi compiti e spesso non è ben chiaro come questo ambiente vada
definito. Rimedio: non c’è nulla di più facile che usare un container
nel quale tutto il software che ci serve è già stato installato,configurato
e testato.
• Documentazione imprecisa : la documentazione riguardante le di-
pendenze,l’installazione e l’esecuzione del codice è spesso imprecisa
, sbagliata o addirittura mancante, rendendo il codice inutilizzabile.
Rimedio: il file di configurazione di un container docker detto Doc-
kerFile è uno script nel quale si definisce esattamente come costruire
l’ambiente,passo per passo.
• Codice obsoleto: le dipendenze citate sopra sono dei pacchetti e
come tali subiscono aggiornamenti ,aggiunta di nuove funzionalità o la
scomparsa di altre ed ognuna di queste può, potenzialmente ,corrompe-
re la nostra esecuzione[4]. Rimedio: anche in questo caso il dockerfile
risolve il problema.
• Portabilità: eseguire il mio codice su un’altra macchina spesso com-
porta lo scontro con uno dei problemi citati sopra. Rimedio: il Doc-
kerFile è un file di testo di dimensioni molto ridotte, quindi se il sistema
operativo ospitante supporta docker possiamo ‘portare’ il DockerFile
su qualsiasi macchina trasportando l’intero ambiente computazionale
in un file di dimensioni molto ridotte.20 3. Docker: storia e caratteristiche principali
3.3 Elementi principali dell’architettura
Ci sono diversi aspetti interessanti da considerare quando si parla di
docker ,le sue componenti giocano un ruolo fondamentale in ogni singola
funzionalità di docker dall’ isolamento alla documentazione passando per il
versioning o per la composizione di container. Di seguito faccio un quadro
sugli elementi principali che compongono l’architettura della piattaforma. In
figura 3.1 è mostrata l’architettura della piattaforma docker, nelle sezioni
successive analizzo i componenti principali di tale architettura.
Figura 3.1: Architettura Docker
3.3.1 Docker Engine
Il cuore di Docker è docker engine, un ‘architettura che comunica con
il kernel Linux e accetta comandi da un client,sia da riga di comando che
tramite API. Docker engine è basato su un’architettura client-server :
• server: è un host sul quale risiede un demone(“dockerd”) che si oc-
cupata della creazione e della gestione di uno o più contenitori docker,
e di comunicare con il client e il sistema operativo host.3.3 Elementi principali dell’architettura 21
• client: prende comandi da utente(linea di comando) e comunica con
il server.
• registry(pubblico o privato): contiene immagini docker, il registro
pubblico ufficiale è Docker Hub.
3.3.2 Ambiente e Filesystem
Linux Container è un ambiente di virtualizzazione system-level nel quale
è possibile eseguire diversi ambienti Linux virtuali (container),isolati tra loro,
su una sola macchina reale avente il kernel Linux. LXC oltre che emulare un
intero sistema può essere usato anche per isolare una singola applicazione,
differenziando quindi i container di tipo “sistema” da quelli di tipo “appli-
cazione”[5]. L’uso di LXC viene poi sostituito dalla libreria libcontainer che
si prenderà carico di risolvere il medesimo problema. Un altro componente
importante di Docker è il file system per container AuFS (Advanced Multi-
Layered Unification Filesystem) , un file-system a strati che permette tra le
altre cose di gestire il versioning dei container. L’immagine del container è
salvata una sola volta, se un processo utilizza quell’immagine viene creato
un container con l’immagine citata e successivamente viene salvata solo la
differenza tra l’immagine citata e l’immagine generata dal lavoro effettuato
nel container(principio del “copy-on-write”).
3.3.3 DockerFile
Consiste in uno script con le precise istruzioni su come creare il contai-
ner;una lista di istruzioni che rendono il processo di creazione facile e chiaro.
Il dockerfile è un file di testo simile ad un Makefile, consiste in una lista di
comandi per il terminale con lo scopo di settare tutte le variabili d’ambiente
in modo opportuno ,scaricare ed installare tutte le dipendenze richieste. In
figura 3.2 è mostrato un esempio di dockerfile. Alcune delle istruzioni che
troviamo in un dockerfile sono:22 3. Docker: storia e caratteristiche principali
• FROM: specifica l’immagine base dalla quale partire,presente in tutti
i dockerfile.
• ENTRYPOINT: specifica l’eseguibile o il comando da eseguire nel
contenitore creato a partire dall’immagine, di solito ultima istruzione
di un dockerfile.
• RUN: specifica un comando da eseguire durante la costruzione del-
l’immagine.
Figura 3.2: Esempio di DockerFile
Quando il dockerfile viene eseguito da un terminale, viene creato il con-
tainer, e avviato successivamente.
3.3.4 Docker Compose
È uno strumento (facoltativo) che permette di definire ed eseguire appli-
cazioni docker su più contenitori, un esempio è mostrato in figura 3.3. In3.3 Elementi principali dell’architettura 23
compose un‘ applicazione è composta da uno o più servizi o micro-servizi
,dove un servizio corrisponde ad un container dedicato alla fruizione del ser-
vizio stesso. Compose non fa altro che definire automaticamente una rete
dedicata all’applicazione e collegare tutti i servizi(container) a questa rete.
Dove ogni blocco di istruzioni indica un container che eseguirà un servizio ,
per ogni container i campi :
• image: indica l’immagine dalla quale partire per creare il singolo
container.
• container name: indica il nome da dare al singolo container.
• networks: indica la rete alla quale il container andrà collegato,di
solito tutti i container in un docker compose sono collegati alla stessa
rete per poter comunicare tra loro e scambiarsi informazioni e servizi.
• command: indica le istruzioni da eseguire una volta che il container
sarà creato.
Figura 3.3: Esempio di Docker-Compose24 3. Docker: storia e caratteristiche principali
3.4 Dalla definizione all’esecuzione
Per un corretto uso di container docker è consigliabile costruire un imma-
gine, creare un container a partire dall’immagine creata e poi avviare quel
container per lavorare. Per farlo la piattaforma docker mette a disposizione
una serie di semplici comandi per il terminale che andremo ad introdurre più
avanti. Nulla vieta di non seguire questi passi e, magari, partire da un’imma-
gine creata da terzi , in questo caso è però consigliabile prendere le dovute
precauzioni sulla fonte. Di seguito andrò a descrivere per passi la defini-
zione o costruzione di un’immagine, la creazione di un container a partire
dall’immagine creata e l’esecuzione di un container. A fine sezione ci sarà un
breve esempio di uso dei comandi per effettuare le suddette operazioni con
container docker.
1. Costruzione immagine: un’ immagine è costituita a partire da
strati(AuFS) , dove ogni strato è un insieme di file; un file viene letto
nello strato più alto in cui si trova,ma può essere scritto solo nello strato
più alto in assoluto. La costruzione di un’immagine consiste nell’ese-
guire un dockerfile (adatto) ,a questo punto : l’immagine specificata
dall’istruzione FROM viene scaricata da registry e posizionata in un
host. Questa immagine viene usata come strato di base della nuova
immagine. Ogni istruzione successiva del dockerfile (RUN) andrà a
formare un nuovo strato dell’immagine personalizzata. È però consi-
gliabile limitare il numero di strati di un’immagine,quindi minimizzare
l’uso dell’istruzione RUN.
2. Costruzione container: un container consiste in un file-system po-
polato da meta-dati, il filesystem è ottenuto dall’immagine iniziale più
un nuovo strato scrivibile,solo questo strato viene realmente allocato
sull’ host. La stessa immagine può essere condivisa da più contenitori,
sarà infatti non scrivibile.
3. Esecuzione container: prima di eseguire un container si dovrà allo-
care le risorse destinategli, successivamente si potrà avviare il conteni-3.5 Caratteristiche Docker 25
tore ,come ultima istruzione, in genere ,è eseguita ENTRYPOINT che
chiuderà l’esecuzione del dockerfile . A fine esecuzione il container è
avviato e pronto all’uso.
Per effettuare le operazioni appena descritte il passo zero sarà scaricare
ed installare docker. Come primo passo bisogna creare un’immagine perso-
nalizzata, per farlo bisogna recarsi nella directory contenente il dockerfile e
da terminale digitare il comando :
$ docker-build ubuntu-img
Una volta creata un’immagine personalizzata si potrà creare un container
a partire da quell’immagine, digitando :
$ docker create --name=test_ubuntu ubuntu-img
A questo punto non resta che far partire il container chiamato test ubuntu
appena creato digitando :
$ docker start test_ubuntu
3.5 Caratteristiche Docker
La vera potenzialità di docker viene fuori quando 2 o più container co-
municano tra loro, attraverso una rete interna privata (può anche essere
pubblica) per scambiarsi informazioni e/o servizi, questo concetto introduce
la modalità swarm prevista da docker,la quale permette di creare una rete
di nodi(host), con annessa gestione di essi . Un nodo è un’istanza di docker
engine che partecipa ad un raggruppamento di nodi(cluster), inoltre ci sono
due tipi di nodo : il nodo worker riceve la richiesta di un task e lo esegue,
il nodo manager che riceve da utenti la richiesta del rilascio di un servizio e
divide esso in una serie di compiti (task) da assegnare ai nodi worker,gestisce
cluster e suoi nodi. Il concetto di nodo in docker introduce quello di orche-
strazione, cioè di gestione dei nodi sulla rete. Una rete di host può essere
gestita seguendo 2 approcci :26 3. Docker: storia e caratteristiche principali
• Orchestrazione: per orchestrazione si intende un modello per la
gestione del lavoro degli host sulla rete. In particolare sarà un host
(direttore d’orchestra) a gestire il flusso dei dati tra gli altri host della
rete per il raggiungimento di uno scopo, che può essere la realizzazione
di un servizio.
• Coreografia: questo approccio a differenza del precedente non preve-
de un host speciale che dirige il lavoro degli altri , ma bensı̀ , ogni host
sulla rete sa cosa fare e con chi comunicare (come in una coreografia)
, spetterà all’host che si trova al termine del flusso dei dati rendere il
servizio tale.
Per quanto riguarda la gestione della rete la piattaforma Docker consen-
te tale gestione per attuare una comunicazione in rete tra contenitori. In
particolare durante l’installazione Docker crea 3 reti :bridge,host,none, ed è
anche possibile aggiungerne altre. Quando un contenitore viene mandato in
esecuzione docker engine gli assegna un indirizzo IP libero della rete bridge,
è possibile anche collegare il container con una rete diversa(opzione : - -
network=nuovarete). I contenitori possono comunicare tra loro se conoscono
la posizione assoluta(indirizzo IP e porta) dei servizi presenti in rete; è anche
possibile rendere questi servizi visibili all’host o al di fuori dell’ host. Un
container può anche essere associato a più reti. La comunicazione tra contai-
ner appena descritta ha come potenzialità quella di permettere di comporre
container per realizzare un unico servizio o applicazione. Per composizione
si intende la possibilità di definire ed eseguire applicazioni multi-container.
Tali applicazioni possono essere viste come uno stack,costituito dall’insieme
dei servizi(contenitori) che la compongono. La specifica di uno stack va de-
scritta in un file YAML, la struttura del file è quella del docker compose.
Le funzionalità di base di Docker permettono di gestire la composizione solo
nei casi più semplici[6],nei quali ci sono diversi container(servizi) e ognuno
ha un numero prefissato di istanze. Per composizioni più complesse ci sono
notevoli estensioni per docker che ne permettono la gestione. Per quanto
riguarda l’orchestrazione in docker sono presenti notevoli elementi nativi che3.5 Caratteristiche Docker 27
la permettono , oltre agli strumenti nativi per docker ci sono una serie di
strumenti noti per l’orchestrazione di container docker, tra i più diffusi Ama-
zon EC2 Container Service, Google Container Engine,Kubernetes, Apache
mesos. L’orchestrazione come anche la composizione sono degli strumen-
ti fondamentali per il rilascio in produzione di applicazioni multi-servizi e
multi-contenitori in un nodo o in cluster di nodi. Per mettere in atto un’or-
chestrazione di container docker deve essere eseguito in modalità swarm,ciò
comporta che il nodo sul quale viene eseguito vada a far parte di uno swarm
di nodi. In uno swarm le azioni eseguite dai nodi si distinguono in:
• Servizio: è una funzionalità da realizzare nello swarm, costituisce il
centro del dibattito tra amministratori e lo swarm stesso.
• Task: un’istanza di un container ,l’esecuzione di un servizio dipende
dall’esecuzione di un certo numero di task relativi a quel servizio.
Per aggiungere un nodo al cluster(o swarm) bisogna eseguire la piattafor-
ma docker in modalità swarm,il nodo può essere distribuito su più macchine
fisiche,virtuali,o su cloud . In un cluster ci posso essere più nodi worker
e più nodi manager. Un ultimo aspetto fondamentale è il supporto che i
sistemi operativi danno alla piattaforma docker, di seguito riporto alcune
informazioni sul supporto da parte dei sistemi Windows, macOS e Linux :
• Windows: docker è compatibile con i sistemi windows ma funziona
in modo sostanzialmente diverso dal solito;viene installata una mac-
china virtuale linux(virtual box) nella quale sarà eseguito il contai-
ner,questa macchina virtuale è eseguita dall’Hypervisor di windows
(Hyper-V),quindi una virtualizzazione ibrida senza apparenti vantaggi.
Nelle ultime versioni di windows 10 e windows 10 server è supporta-
to un container linux nativo quindi è possibile scegliere tra la modalità
con macchina virtuale e hypervisor citata prima e la modalità container
nativo .Se si sceglie la modalità container nativo si avranno gli stessi
vantaggi di usare un sistema linux.28 3. Docker: storia e caratteristiche principali
• MacOS: docker è compatibile con i sistemi MacOS ma anche in que-
sto caso avviene una virtualizzazione ibrida, viene installato un Hyper-
kit,gestore virtualizzazione per macOS, al posto di virtual box ma il
funzionamento è il medesimo dei sistemi windows con hypervisor.
• Linux: docker è concepito per Linux e quindi compatibile con qualsiasi
distribuzione che abbia un kernel linux[13].
Nel prossimo capitolo ci sarà una panoramica sulla piattaforma di hosting
Github ,sulle api offerte dalla piattaforma per interrogare il sistema e sulle
limitazioni che ci sono su di esse. Successivamente sarà introdotto il con-
cetto di scraping e il linguaggio xpath che saranno fondamentali nell’analisi
che sarà esposta nel capitolo 5. Per concludere il capitolo ci saranno delle
sezioni che descrivono la progettazione dello script che ho usato per portare
effettuarel’analisi, dalla scelta delle informazioni da studiare, alla sua imple-
mentazione vera e propria per poi terminare con esempi sull’uso dello stesso
script per personalizzare le proprie ricerche.Capitolo 4
Creazione del dataset: github
mining
Questo capitolo si fa carico di descrivere le varie tecnologie e gli ambienti
usati per condurre la ricerca. Saranno visti nel dettaglio i singoli argomenti,
iniziando con esporre un quadro generale sulla piattaforma di hosting on-line
Github, dalla storia alle sue caratteristiche base. Successivamente si affron-
terà l’argomento delle api REST messe a disposizione degli utenti da parte
di github per interrogare il sistema e delle limitazioni che vengono fatte sul
loro uso. Sarà poi introdotto il concetto di scraping e il linguaggio xpath per
estrarre elementi da documenti XML. Conclude il capitolo un quadro sulla
progettazione e implementazione dell’algoritmo di ricerca automatica. In sin-
tesi nelle sezioni successive andrò a spiegare nel dettaglio lo studio effettuato
sullla piattaforma github e i metodi per poter interrogare la piattaforma
,personalizzando le interrogazioni. Una volta acquisito il giusto background
oltre che su github anche su docker e l’uso che ne viene fatto ho iniziato a
progettare un algoritmo che :
1. Interrogasse github: con lo scopo di ovviare alle limitazioni imposte
dal sistema ed ottenere circa 200000 progetti come risultati .
2. Analizzasse risultati: una volta raccolti i 200000 progetti , uno ad
uno analizzasse i repository e salvasse i dati per l’elaborazione.
2930 4. Creazione del dataset: github mining
3. Elaborasse e stampasse i risultati: la stampa avviene in un foglio
di calcolo cosı̀ da potermi permettere in modo semplice di creare dei
grafici relativi a quei dati e analizzarli .
4. Permettesse personalizzazione: come ultimo compito ho reso per-
sonalizzabile la ricerca tramite il mio algoritmo in modo da permettere
a chiunque di effettuare analisi su una qualsiasi parola chiave.
4.1 Github
Github è una piattaforma sociale per programmatori nella quale è possi-
bile creare il proprio repositry(directory di file, in genere il termine repository
è usato per indicare la cartella contenente i file sorgente di un programma
o applicazione) e condividerlo con l’intera community o visionare milioni di
repository condivisi in precedenza dalla community. Per entrare a fare parte
della community basta iscriversi a github.com , fornendo un indirizzo email
valido e confermando l’iscrizione tramite il link inviato all’email fornita, una
volta confermata l’iscrizione si è a tutti gli effetti membri della piattaforma.
Una volta entrati come utenti github da a disposizione 1 GB di spazio gratis
per creare il proprio repository, che sarà però pubblico, a meno che non si
scelgano dei piani tariffari i quali permettono,tra le altre cose, di oscurare
i propri repository alla community rendondoli privati. Un utente github ha
anche la possibilità di clonare un qualsiasi repository presente nella com-
munity,purchè sia un repository pubblico, nel proprio storage e farci ciò che
vuole. Github è basato sul sistema di controllo delle versioni ‘git’ creato dal
fondatore di linux Linus Torvalds, questo sistema consiste in un gestore di
aggiornamenti per un progetto, cioè aggiorna il progetto non sovrascrivendo
nulla di esso, semplicemente portandolo ad una versione successiva. Oggi gi-
thub è nel suo campo la piattaforma più usata, gli scopi per i quali gli utenti
la usano sono diversi :
• area di lavoro professionale con controllo versioning.4.1 Github 31
• condividere area di lavoro in più persone, anche dislocate tra loro.
• semplice cloud per file,fogli di lavoro o foto.
• didattico , in quanto è possibile insinuarsi in qualsiasi file di qualsiasi
repository e consultarlo, scaricarlo e modificarlo, purché i file siano
pubblici ovviamente.
• sociale , in quanto è possibile seguire progetti o utenti interessanti e
scambiare messaggi, opinioni.
4.1.1 Breve storia
La storia di github inizia circa 5 anni prima della sua nascita quando si
sente l’esigenza di un sistema come git,un sistema di controllo delle versioni.
Siamo nel 2005 e nel corso dello sviluppo della versione 2.6.12 del kernel linux
da parte di Linus Torvalds e i suoi collaboratori si avverte il bisogno di un
gestore degli aggiornamenti, un software che sarebbe stato in grado di tornare
indietro se l’installazione degli aggiornamenti non fosse andata a buon fine o
se si fossero riscontrati degli errori negli aggiornamenti appena installati. In
pochi mesi viene progettato e presentato git in concomitanza con la nuova
versione del kernel linux che sarà la prima gestita con il nuovo sistema di
versioning [7]. Qualche anno più tardi , nel 2009 , viene fondato Github
da Tom Preston-Werner, Chris Wanstrath e PJ Hyett [8], una piattaforma
basata sul sistema git di Linus Torvalds e sul concetto di social network. Nel
giro di pochi anni github diventa la piattaforma di hosting più frequentata
dagli sviluppatori di tutto il mondo e conta più di 10.000.000 di repository.
4.1.2 Api github
Github mette a disposizione degli utenti una vasta gamma di api REST
per personalizzare e rendere automatiche le ricerche dei repository. In par-
ticolare è possibile interrogare la piattaforma attraverso una stringa( query)
personalizzabile, la ricerca può basarsi su uno dei seguenti campi :32 4. Creazione del dataset: github mining
• repositories: la ricerca viene effettuata tra i repository presenti.
• commits: la ricerca è effettuata tra tutti gli aggiornamenti presenti
nella piattaforma,un singolo aggiornamento è quello che ogni utente
apporta al proprio repository.
• code: la ricerca si basa su file contenenti del codice.
• users: la ricerca viene effettuata tra gli utenti iscritti alla piattaforma.
Inoltre è possibile basare la propria ricerca su : issues, topics o text
match metadata . Per ognuno di questi campi è possibile settare una serie di
parametri per filtrare la propria ricerca come ad esempio : l’ordine, la data di
creazione, il linguaggio utilizzato ,la licenza , il numero di stelle , effettuare
la ricerca solo in un determinato file del repository, l’autore del commit ed
un’altra lunga serie[9]. Qui sotto mostro due esempi di uso di api github :
https://api.github.com/search/commits?=repo:octocat/Spoon-Knife+css
Tramite l’uso di quest’ api interroghiamo github sui commit relativi al CSS
nello specifico repository “Spoon-Knife” dell’utente “octocat”.
https://api.github.com/search/repositories?=docker+created%3A2014
Questa api permette di avere come risultato tutti i repository che usano
docker creati nel 2014. La risposta che github da ad una interrogazione come
questa consiste in una lista di elementi,in formato JSON, ogni elemento della
lista rappresenta un repository che ha soddisfatto la richiesta,ed ha notevoli
campi tra cui:nome repository, linguaggio usato , numero stelle repository ,
url del repository.In figura 4.1 e 4.2 un esempio di un elemento della lista
JSON:4.1 Github 33
Figura 4.1: esempio lista JSON (pt.1)34 4. Creazione del dataset: github mining
Figura 4.2: esempio lista JSON (pt.2)4.2 Tecnologie ausiliarie 35
4.1.3 Limitazioni
Il servizio di risposta alle api da parte di github ha delle limitazioni sia
nel tempo che nel numero di risultati .Potenzialmente potrei inserire un’
api in un programma che la modella e la esegue migliaia di volte ,github
per non permette di sovraccaricare i propri server con milioni di richieste al
secondo,quindi, impone due tipi di limitazioni :
• rate-limit: un utente non iscritto a github sarà identificato con il
proprio indirizzo IP e può effettuare 10 richieste al secondo con un
massimo di 60 richieste all’ora. Il discorso invece cambia con un utente
iscritto a github, infatti l’utente sarà identificato con il suo id utente e
,soprattutto, avrà a disposizione 30 richieste al minuto per un massimo
di ben 5000 richieste all’ora.
• paginazione: per limitare le risorse impiegate github ha imposta-
to per i risultati delle richieste delle limitazioni in termini di numero,
infatti effettuando una richiesta la risposta del sistema sarà solo par-
ziale,per default solo 100 saranno i risultati visualizzati, inoltre una
richiesta non può avere più di 1000 risultati visualizzati[10]. Se io vo-
lessi visualizzare tutti i 2900 repository di una qualche tipologia dovrei
impostare la paginazione a 1000 risultati per pagina ed inoltre effettua-
re tre richieste al sistema github , nella prima richiederò la pagina uno
dei miei risultati(primi 1000), nella seconda chiederei la pagina due di
risultati(secondi 1000) e nella terza chiederei la terza ed ultima pagina
di risultati(ultimi 900).Dove per risultati si intendono gli elementi della
lista citati a fine sezione 4.1.2 .
4.2 Tecnologie ausiliarie
Per arrivare ad un’analisi consistente sorge il bisogno di analizzare ogni
singolo elemento della lista dei risultati e estrapolare le informazioni interes-
santi per poi elaborare statistiche grafici e conclusioni. L’analisi che voglioPuoi anche leggere

















































