Sistemi per Open Information Extraction - Università degli Studi di Roma "Tor Vergata"
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù

Università degli Studi di Roma “Tor Vergata” ______________________________________________________ Sistemi per Open Information Extraction Manuel Fiorelli fiorelli@info.uniroma2.it
Cos'è L'Open Information Extraction (Open IE) è stato introdotto da Banko et al (2007): a novel extraction paradigm that facilitates domain-independent discovery of relations extracted from text and readily scales to the diversity and size of the Web corpus Mausam (2016) ci dice: "Open Information Extraction (Open IE) extracts textual tuples comprising relation phrases and argument phrases from within a sentence, without requiring a pre-specified relation vocabulary" "Its key insight is to not only extract arguments, but also extract relation phrases from text itself" Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 2
Arità delle relazioni I primi sistemi di Open IE estraevano relazioni binarie "Bill Gates co-founded Microsoft" (Bill Gates, founded, Microsoft) Tuttavia, sistemi più recenti sono in grado di gestire relazioni di arità maggiore di 2: "Yakub flew from London to Seattle" (Mausam, 2016) (Yakub, flew, from London, to Seattle) Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 3

Assunzioni linguistiche Alcuni sistemi sono in grado soltanto di estrarre relazioni mediate da verbi: "Bill Gates co-founded Microsoft" Ci sono sistemi (in particolare quelli più recenti) che supportano relazioni mediate da altre tipologie di parole (es. nomi): "Microsoft co-founder Bill Gates…" Un'altra assunzione molto comune nei primi sistemi è che la relation phrase si trovi in mezzo alle argument phrase: "Microsoft co-founder Bill Gates…" Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 4
Analisi del contesto Negli esempi successivi, tratti da Mausam et al (2012), sono mostrati fenomeni di attribuzione e di verità condizionata: – "Early astronomers believed that the earth is the center of the universe" – "If he wins five key states, Romney will be elected President.” Questi fenomeni possono essere gestiti estendendo le tuple con componenti addizionali (es. attribuzione, condizione), oppure attraverso tuple nidificate. Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 5

Problema della sinonimia e della disambiguazione Le componenti delle tuple estratte da un sistema di Open IE sono generalmente stringhe (normalizzate), senza che venga fatto alcun tentativo di riconoscere sinonimi o risolvere le ambiguità Bill Gates was the president of Microsoft (Bill Gates, be the president of, Microsoft) Relation phrase diverse per la Bill Gates was the chairman of Microsoft (Bill Gates, be the chairman of, Microsoft) stessa relazione Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 6
Vantaggi dell'Open IE [Banko et al (2007)] Automazione – Non richiede esempi, regole né alcun materiale di addestramento specifici per le relazioni da estrarre (che comunque non sono note a priori) Eterogeneità del corpus – Utilizza tecniche in grado di operare su documenti di tipologia e dominio diversi (NER e parser sintattici possono avere dei problemi) Efficienza – Utilizza tecniche efficienti e, in generale, compie un solo passaggio sul corpus da elaborare – Estrae tutte le relazioni dal corpus di input in una sola esecuzione, mentre nell'IE tradizionale occorre rieseguire il sistema (dopo averlo configurato/addestrato) ogni volta che cambia lo schema da popolare Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 7
Applicazioni dell'Open IE [Mausam(2016)] (1/2) Applicazioni end-user – Interrogazione delle tuple estratte. • (?, kill, bacteria) – Esplorazione di un corpus • Per esempio, andando a leggere i documenti dai quali è stata estratta una certa tupla – Riepilogo delle informazioni (information summarization) • Per esempio, “(Jahangir, ?, ?) restituisce tutte le triple riguardanti " Jahangir" Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 8

Applicazioni dell'Open IE [Mausam(2016)] (2/2) Applicazioni in task NLP Le tuple prodotte da un sistema di Open IE possono essere usate per costruire una rappresentazione intermedia del testo per implementare vari task: – Traditional IE – Event Schema Induction – Sentence Similarity – Text Comphrension – Lexical Similarity and Analogy Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 9

Sistemi di Open IE Alcuni sistemi per l'Open IE • TextRunner • ReVerb • OLLIE • Claus-IE • CSD-IE • DefIE • Open-IE 5 Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 10
TextRunner [Banko et al (2007)] (1/2) TextRunner elabora una frase alla volta (single-pass extractor): – Effettua il pos tagging della frase – Utilizzare un chunker per identificare NP che potrebbero denotare entità – Per ogni coppia di NP, viene analizzato il testo nel mezzo, eliminando parti non essenziali: • "Scientists from many universities are studying…" "Scientists are studying…" • "definitely developed” "developed" – La coppia di NP ed il testo normalizzato tra di loro è una tupla candidata – Le tuple candidate sono filtrate per mezzo di un classificatore (appreso in precedenza) La confidenza di una tupla viene quindi stimata in base al numero di frasi che la supportano (redundancy-based assessor). Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 11
TextRunner [Banko et al (2007)] (2/2) Il classificatore (Self-Supervised Learner) che stabilisce se un candidato è affidabile viene appreso offline in maniera self-supervised: 1. Annota automaticamente i propri dati di addestramento 2. Apprende un classificatore (Naive Bayes) che usa feature non lessicalizzate e che non richiedono un parse tree (es. presenza di certi POS tag, lunghezza della relation phrase, etc.) il modello appreso si può applicare anche a relazioni mai viste nei dati di training Il primo punto può sembrare strano: – Perché non sfruttare capacità di annotare i dati di addestramento per annotare le tuple candidate in fase di estrazione? – La ragione è che questa capacità sfrutta una rappresentazione (basata sull'analisi delle dipendenze) dei dati di esempio diversa da quella che viene usata in fase di estrazione (basata sui pos tag) Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 12
ReVerb [Fader et al (2011)] (1/6) ReVerb usa un approccio relation-first: – Identifica prima la relation phrase – Successivamente identifica le argument phrase Rispetto all'approccio argument-first (es. di TextRunner), riduco il rischio che certe parole vengano erroneamente inserite negli argomenti invece che nella relation phrase: – "Faust made a deal with the devil" produce in TextRunner la tupla (Faust, made, a deal) invece di (Faust, made a deal with, the devil) – In generale, possono essere gestite male tutte le costruzioni con light verb Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 13
ReVerb [Fader et al (2011)] (2/6) ReVerb usa un modello prestabilito delle relazioni (invece di apprenderlo come nel caso di TextRunner) Circa l'85% delle relation phrase binarie rette da verbi in un corpus di documenti Web soddisfa la seguente espressione regolare su POS tag (vincolo sintattico) V | V P | VW*P V = verb particle? adv? W = (noun | adj | adv | pron | det) P = (prep | particle | inf. marker) Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 14
ReVerb [Fader et al (2011)] (3/6) Il vincolo sintattico aiuta ReVerb ad evitare estrazioni problematiche: • Incoerenti: relation phrase incomprensibile – " The guide contains dead links and omits sites" (relation phrase "contains omits") • Non informative: omettono informazioni critiche – "Faust made a deal with the devil" (Faust, made, a deal) Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 15
ReVerb [Fader et al (2011)] (4/6) ReVerb utilizza, inoltre, un vincolo lessicale: – Una relation phrase deve avere diverse istanze – In questo modo, si evita di estrarre tuple con una relation phrase eccessivamente specifica Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 16
ReVerb [Fader et al (2011)] (5/6) L'estrazione delle tuple in ReVerb funziona così: – Di ogni frase viene fatto il pos tagging e il chunking – Le relation phrase sono identificate andando a trovare le corrispondenze dell'espressione regolare (vincolo sintattico) nella frase (annotata con i pos tag). Corrispondenze adiacenti sono fuse. – Per ogni relation phrase r: • Il primo argomento x è la NP più vicina alla sinistra di r, che non è un pronome, un WHO- adverb o un there esistenziale • Il secondo argomento y è la NP più vicina alla destra di r – Vengono così prodotte le triple candidate (x, r, y) Ogni relation phrase deve anche soddisfare il vincolo lessicale. La confidenza delle tuple candidate viene calcolata usando una funzione appresa in precedenza su un training set. Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 17
ReVerb [Fader et al (2011)] (6/6) Analisi degli errori REVERB - Incorrect Extractions 65% Correct relation phrase, incorrect arguments 16% N-ary relation 8% Non-contiguous relation phrase 2% Imperative verb 2% Overspecified relation phrase 7% Other, including POS/chunking errors REVERB - Missed Extractions 52% Could not identify correct arguments 23% Relation filtered out by lexical constraint 17% Identified a more specific relation 8% POS/chunking error Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 18
OLLIE [Mausam et al (2012)] (1/5) • Estrae relazioni mediate non solo da verbi ma anche da nomi, aggettivi ed altro maggiore capacità di estrazione • Aggiunge alla tuple informazione contestuale (attribuzione e condizione) maggiore precisione Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 19
OLLIE [Mausam et al (2012)] (2/5) In fase di estrazione: – OLLIE lavora sulla rappresentazione a dipendenze della frase in input (mentre TextRunner e ReVerb lavorano solo sui postag). – OLLIE cerca delle corrispondenze per degli open pattern template, consistenti in • Pattern sull'albero delle dipendenze • Template di tupla • Corrispondenza tra "variabili" nei due template Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 20
OLLIE [Mausam et al (2012)] (3/5)
({arg1}, {rel}, {arg2})
{arg1} {rel} {arg2}
(Bill Gates, founded, Microsoft)
({arg1}, be {rel} of, {arg2})
{arg2} {rel:type=person} {arg1}
Qualunque iponimo della
parola "person"
(Bill Gates, be co-founder of, Microsoft)
Argomenti e relatione possono essere
espansi attraverso certi tipi di dipendenze
Manuel Fiorelli fiorelli@info.uniroma2.it
29/11/2018 http://art.uniroma2.it/fiorelli 21OLLIE [Mausam et al (2012)] (4/5) Attribuzione riconosciuta come dipendenza di tipo ccomp con un verbo comunicativo o cognitivo (in base a VerbNet) “Early astronomers believed that the earth is the center of the universe.” ((the earth; be the center of; the universe) AttributedTo believe; Early astronomers) Modificatori riconosciuti come dipendenza di tipo advcl, filtrata lessicalmente considerando un lessico di 16 termini (if, when, etc..) “If he wins five key states, Romney will be elected President.” ((Romney; will be elected; President) ClausalModifier if; he wins five key states) Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 22
OLLIE [Mausam et al (2012)] (5/5) Gli open pattern template sono appresi mediante una tecnica di bootstrapping: – Si parte da un insieme di tuple (x, r, y) ad elevata confidenza prodotte da un sistema come ReVerb – Si cercano nel corpus di addestramento frasi che contengono le content word che costituiscono x, r, y (nota:il distant supervision differisce perché non cerca una corrispondenza per r) – Si considera il percorso nell'albero delle dipendenze associato a ciascuna corrispondenza: sulla base di alcuni controlli su questo percorso, si distinguono • Pattern puramente sintattici: non contengono alcune parole né restrizioni di tipo • Pattern lessico/semantici: vengono lasciate alcune parole (nel predicato o fuori), oppure sono calcolate (mediante una risorsa lessico-semantica delle restrizioni di tipo) Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 23
ClausIE [Del Corro & Gemulla (2013)] (1/10) ClausIE elabora una frase alla volta, senza alcun post- processing. Estrazione in 4 fasi: – Parsing alle dipendenze – Determinazione delle clausole all'interno della frase usando le dipendenze – Identificazione del tipo di clausola, e derivazione di un insieme di clausole coerenti – Generazione delle proposizioni da un sottoinsieme delle clausole coerenti Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 24
ClausIE [Del Corro & Gemulla (2013)] (2/10) Una clausola è una parte di una frase che esprime un pezzo di informazione coerente. Essa consiste di: – Un subject (S) – Un verb (V) – Un direct object (O) – Un indirect object (O) – Un complement (C) – Zero o più adverbial (A) Solo certe combinazioni sono ammesse dalla grammatica inglese Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 25
ClausIE [Del Corro & Gemulla (2013)] (3/10) Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 26
ClausIE [Del Corro & Gemulla (2013)] (4/10) • I costituenti di una clausola che fanno parte del suo tipo sono detti essenziali: rimuoverli renderebbe la clausola priva di significato (o cambierebbe il senso del verbo) • Gli altri costituenti sono detti opzionali. In generale, possono essere opzionali gli adverbial Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 27
ClausIE [Del Corro & Gemulla (2013)] (5/10) Le clausole possono essere determinate dall'analisi alle dipendenze. Per esempio: per ogni dipendenza di tipo nsubj si costruisce una clausola con: – Il dipendente è il subject (S) – Il governatore è il verb (V) Gli altri costituenti sono dipendenti del verbo: – Object (O) e complement (C) tramite dobj, iobj, xcomp e ccomp – Gli adverbial (A) tramite relazioni quali advmod, advcl o prep_in Altre clausole sono sintetizzate per (può gestire alcune relazioni non mediate da verbi): – Clausole relative in cui il pronome relativo è sostituito dal proprio antecedente (tramite rcmod) – Apposizioni e possessivi, introducendo un verbo sintetico, rispettivamente is o has – Participial modifiers Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 28
ClausIE [Del Corro & Gemulla (2013)] (6/10) Clausole identificate (S: Bell,V: makes, O: products) (S: Bell,V: based, A: Angeles) (S: Bell,Vc: is, C: Company) Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 29
ClausIE [Del Corro & Gemulla (2013)] (7/10) Dopo aver identificato le clausole, occorre determinarne il tipo: • I tipi SVC, SVOO, and SVOC possono essere determinati soltanto dalla loro struttura; tutti gli adverbial sono opzionali • Per distinguere SV da SVA e SVO da SVOA, occorre vedere se: – L'adverbial è un candidato per essere essenziale (dipendente dal verbo ed alla sua destra) – il verbo è extended copular (SV vs SVA) oppure complex transitive (SVO da SVOA): a tale scopo sono usati dei lessici contenti verbi che sicuramente hanno oppure non hanno tale caratteristica Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 30
ClausIE [Del Corro & Gemulla (2013)] (8/10) Dopo aver determinato il tipo di una clausola, ClauIE genera tante clausole coerenti: – Selezionando tutti i costituenti essenziali – Al più un adverbial opzionale Inoltre, fa un'espansione delle clausole rispetto alle congiunzioni coordinanti. Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 31
ClausIE [Del Corro & Gemulla (2013)] (9/10) Clausole identificate (S: Bell,V: makes, O: [electronic] products) Espansione (S: Bell,V: makes, O: [computer] products) (S: Bell,V: makes, O: products) congiunti (S: Bell,V: makes, O: [building] products) (S: Bell,V: based, A: Angeles) (S: Bell,V: distributes, O: [electronic] products) (S: Bell,Vc: is, C: Company) (S: Bell,V: distributes, O: [computer] products) (S: Bell,V: distributes, O: [building] products) Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 32
ClausIE [Del Corro & Gemulla (2013)] (10/10) Dalle clausole così ottenute sono generate le triple: (“Bell”, “is”, “a telecommunication company”), (“Bell”, “is based”, “in Los Angeles”), (“Bell”, “makes”, “electronic products”), (“Bell”, “makes”, “computer products”), (“Bell”, “makes”, “building products”), (“Bell”, “distributes”, “electronic products”), (“Bell”, “distributes”, “computer products”), (“Bell”, “distributes”, “building products”) Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 33
CSD-IE [Bast & Haussmann (2013)] CSD-IE utilizza la tecnica della contextual sentence decomposition, che era stata sviluppata originariamente per la ricerca semantica. Un contesto è una sotto-sequenza di parole che "si appartengono semanticamente". La frase seguente: Ruth Gabriel, daughter of the actress and writer Ana Maria Bueno, was born in San Fernando Contiene i seguenti contesti: #1:Ruth Gabriel was born in San Fernando #2: Ruth Gabriel, daughter of Ana Maria Bueno #3: actress Ana Maria Bueno #4: writer Ana Maria Bueno Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 34
CSD-IE [Bast & Haussmann (2013)] L'identificazione dei contesti viene fatta in due fasi: – Sentence constituent identification (SCI): applicando un insieme di regole al parse tree a costituenti si deriva un albero SCI che rappresenta i componenti principali dei contesti in una frase – Sentence constituent recombination (SCR): ricombina i nodi di un albero SCI per identificare i contesti finali della frase Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 35
CSD-IE [Bast & Haussmann (2013)] Ciascun contesto produce una tripla: – la prima verb phrase esplicita e l'eventuale avverbio vanno nella relazione – tutto ciò che viene prima va nel soggetto – tutto ciò che viene dopo va nell'oggetto In alcuni casi, viene sintetizzato un verbo Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 36
CSD-IE [Bast & Haussmann (2013)] Ruth Gabriel, daughter of the actress and writer Ana Maria Bueno, was born in San Fernando contesti #1:Ruth Gabriel was born in San Fernando #2: Ruth Gabriel, daughter of Ana Maria Bueno #3: actress Ana Maria Bueno triple #1: (Ruth Gabriel) (was born) (in San Fernando) #4: writer Ana Maria Bueno #2: (Ruth Gabriel) (is) (daughter of Ana Maria Bueno) #3: (Ana Maria Bueno) (is) (actress) #4: (Ana Maria Bueno) (is) (writer) Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 37
CSD-IE [Bast & Haussmann (2013)] Frasi come questa: Soubry graduated in law from the University of Birmingham in 1979 Non sono decomposte nella fase di SCI; tuttavia, durante la fase di SCR, usando il parse tree viene notata la presenza di un nome e di sintagmi preposizionali; quindi saranno generate le seguenti triple: #1: (Soubry) (graduated) (in law) #2: (Soubry) (graduated) (in law from the University of Birmingham) #3: (Soubry) (graduated) (in law in 1979) Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 38
CSD-IE [Bast & Haussmann (2013)] Gli obiettivi di CSD-IE sono: – Accuratezza delle estrazioni – Numero di estrazioni (estrarre quanti più possibili fatti da una frase) – Minimalità delle estrazioni (un'estrazione non dovrebbe contenere altre estrazioni accurate) Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 39
DefIE [Delli Bovi et al (2015)] (1/6) Utilizza tecniche di Open IE migliorate semanticamente su corpus più piccoli e densi di natura prescrittiva (es. definizioni tratte da Wikipedia) – Combina analisi sintattica alle dipendenza con un approccio unificato per l'entity linking e word sense disambiguation – Produce triple semanticamente disambiguate su named entity e concetti tratti da risorse come Wikipedia e WordNet – Costruisce una tassonomia di relazioni Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 40
DefIE [Delli Bovi et al (2015)] (2/6) DefIE utilizza: – BabelNet come fonte di conoscenza di background che include sia named entity sia concetti generali – Babelfy per l'annotazione unificata di named entity e word senses Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 41
DefIE [Delli Bovi et al (2015)] (3/6) Da ciascuna definizione, viene calcolato l'albero delle dipendenze sintattiche (a) e viene effettuato l'entity linking/word sense disambiguation (b). Viene, quindi, creato un albero sintattico-semantico: i) i vertici sono annotati con i sensi (eventualmente fondendo multiword expressions), ii) aggiunti e modificatori non disambiguati vengono scartati. ( è l'i-esimo senso della parola "band" all'interno di BabelNet) Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 42
DefIE [Delli Bovi et al (2015)] (4/6) Da ciascun albero sintattico-semantico, vengono identificati relation pattern come i) cammini minimi tra coppie di concetti, che ii) contengono almeno un verbo. → → 1 → → → → Successivamente sono eliminate le relazioni con un numero di istanze al di sotto di un certa soglia ρ Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 43
DefIE [Delli Bovi et al (2015)] (5/6) Di ciascuna relazione, viene determinato il dominio ed il range: l'iperonimo diretto della maggioranza dei soggetti e degli oggetti, rispettivamente. In aggiunta, viene calcolato uno score per ciascun relation pattern: Numero di istanze = Entropia della distribuzione degli + 1 ℎ( ) iperonimi degli argomenti Lunghezza del pattern Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 44
DefIE [Delli Bovi et al (2015)] (6/6) Viene, infine, creata una tassonomia di relation pattern, andando a confrontare tutte le relazioni il cui pattern differisce soltanto per un nome. Hypernym (a) and substring (b) generalizations Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 45
OpenIE 5 OpenIE 5 è il successore di Open IE 4, che a sua volta era il successore di OLLIE. Esso combina diversi sistemi: • CALMIE (Saha & Mausam, 2018) per trattare frasi congiuntive • BONIE (Saha et al., 2018) per estrarre relazioni numeriche, anche se esse sono implicite (es. inferire da "square kilometers" la relazione "area") • RelNoun (Pal & Mausam, 2016) per estrarre relazioni mediate da nomi • SRLIE (Christensen et al., 2011) per estrarre le relazioni mediante tecniche di Semantic Role Labeling (SRL) Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 46
Ulteriori sfide Ci sono un numero di sfide (alcune accennate in precedenza) che meritano di essere sottolineate: – Sinonimia e ambiguità – Complessità del linguaggio naturale – Correttezza dell'informazione – Aspetti temporali/spaziali – Controllo di consistenza Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 47
Sinonimia (1/2) Una stessa entità può essere menzionata in modi diversi: John Fitzgerald Kennedy, John F. Kenney, John Kennedy, Jack Kennedy, JFK ma anche Kennedy, John nel caso di riferimenti parziali (vedi dopo) Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 48
Sinonimia (2/2) Similmente, una certa relazione può essere espressa da parole diverse: X is the chairman of Y, X is the president of Y, ma anche con costrutti sintattici differenti: X is the ceo of Y, Y ceo X Alcuni sistemi (es. OLLIE) sono in grado di gestire relazioni mediate da diversi tipi di parole, e spesso possono generare la stessa relation phrase. Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 49
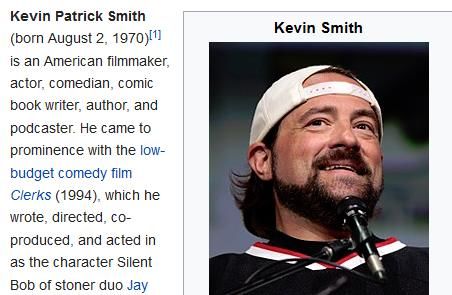
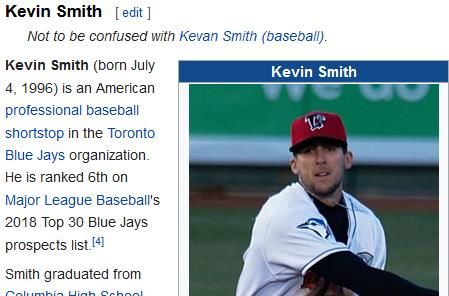
Ambiguità La phrase "Kevin Smith" ha significati diversi nelle due pagine sottostanti tratte da Wikipedia (in inglese). https://en.wikipedia.org/wiki/Kevin_Smith https://en.wikipedia.org/wiki/Toronto_Blue_Jays_mi nor_league_players#Kevin_Smith Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 50
WordNet (1/2) WordNet1 è una risorsa lessico-semantica per l'inglese americano. – Parole (divise tra nomi, verbi, aggetti e avverbi) – Sensi delle parole – Synset (raggruppamenti di sensi che esprimono lo stesso concetto, descritto tramite una glossa) – Relazioni tra synset (es. iperonimia/iponimia) o tra sensi (es. antonimia) Tipicamente, in WordNet non troveremo named entity, ma soprattutto nomi comuni. 1 https://wordnet.princeton.edu/ Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 51
WordNet (2/2) "president" e "chairman" sono quasi sinonimi, perché hanno dei sensi che esprimono lo stesso concetto. Tuttavia, per essere precisi dovremmo sapere con quale senso le due parole sono state usate nel testo, cioè dovremmo avere effettuato la word sense disambiguation. Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 52
Word sense disambiguation (WSD) Una parola può avere più sensi: Tuttavia, all'interno di una frase ciascuna parola dovrebbe essere usata in un determinato senso (a meno di fenomeni particolari come il doppio senso). In linguistica computazionale, il task di word sense disambiguation consiste nel determinare con quale senso una parola è usata all'interno di una frase (quando la parola ha più significati). Questo task presuppone l'esistenza di un repertorio di word sense (es. WordNet). Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 53
Entity Linking o Named Entity Disambiguation Citando https://en.wikipedia.org/wiki/Entity_linking: In natural language processing, entity linking, named entity linking (NEL),[1] named entity disambiguation (NED), named entity recognition and disambiguation (NERD) or named entity normalization (NEN)[2] is the task of determining the identity of entities mentioned in text. […] Entity linking requires a knowledge base containing the entities to which entity mentions can be linked. Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 54
DBpedia Spotlight DBpedia Spotlight1 riconosce (soltanto) risorse definite in DBpedia. Manuel Fiorelli non è riconosciuto come menzione di una Person, perché non c'è una risorsa corrispondente in DBpedia 1 https://www.dbpedia-spotlight.org/ Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 55
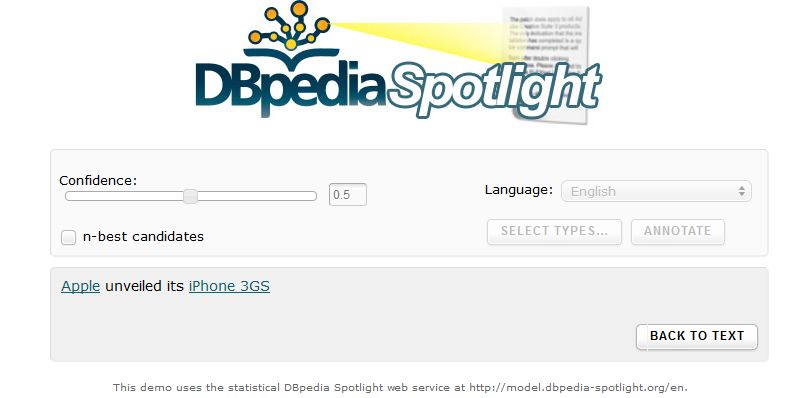
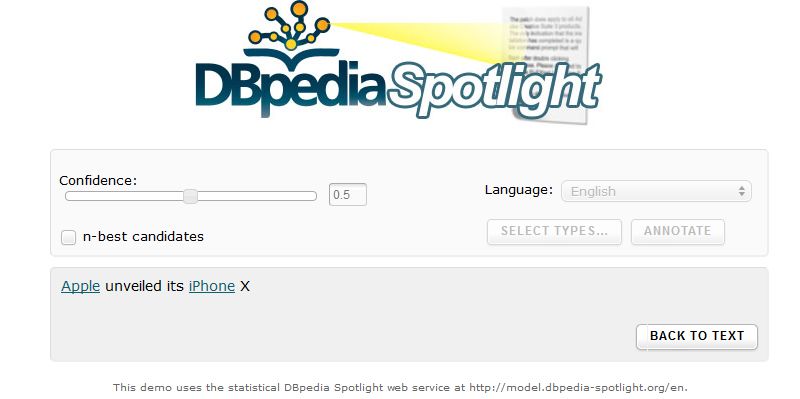
DBpedia Spotlight iPhone 3GS è riconosciuto come menzione di un prodotto della Apple iPhone X non è riconosciuto come menzione di un prodotto della Apple. La sua pagina su Wikiepedia è stata create il 10 settembre 2017, mentre la versione attuale di Dbpedia è basata su un dump di Wikipedia generato nell'ottobre 2016. Pertanto, l'iPhone X non ha attualmente una risorse in Dbpedia. Questo problema sarebbe evitato dall'uso di Dbpedia Live; tuttavia, ci sarebbe comunque un problema con i modelli usati da Spotlight, che non sono aggiornati. Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 56
DBpedia Spotlight - Flow Input content Spotting Identifica le porzioni del documento che potrebbero essere menzioni di entità Candidate Selection Associa alle menzioni identificate le entità di Dbpedia che sono candidate ad esprimere il significato di queste menzioni 1 2 3 Disambiguation 21 1 Decide qual è il significato delle menzioni 1 2 3 Filtering 21 1 Aggiusta il processo di annotazione attraverso dei parametri di configurazione Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 57
DBpedia Spotlight – Due varianti Esistono due varianti di DBpedia Spotlight. Entrambe usano l'insieme dei link all'interno di Wikipedia. – lucene: basata sul vector space model (VSM). Associa a ciascuna risorsa una sorta di documento virtuale ottenuto combinando tutti i paragrafi all'interno di Wikipedia che la menzionano. La disambiguazione si basa sulla similarità tra il contesto di una menzione e questo documento virtuale. Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 58
DBpedia Spotlight – Due varianti Esistono due varianti di DBpedia Spotlight. Entrambe usano l'insieme dei link all'interno di Wikipedia. – model (più accurata, minore consumo memoria/tempo): basata su un modello generativo. La disambiguazione si effettua come un problema di Assumendo s e c indipendenti, possiamo esprimerla ottimizzazione: come prodotto di due probabilità Numero di e e link che e = e e = e ( ) = e e e puntano a e Probabilità che un token t occorre nel = e e e e contesto di una menzione (e) e t = e + 1 − e = c|e = ෑ e ( ) Smoothed unigram language model | | (e, ) Numero s|e = e ( ) totale di link ( ) e_ML t = σ e ( ) Numero di link ad e con Assumendo che i token siano Numero di occorrenze del token t nel surface form s indipendenti contesto di link a e Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 59
DBpedia Spotlight - Evaluation Source: (Mendes et al., 2011) Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 60
DBpedia Spotlight – on premises See https://github.com/dbpedia-spotlight/dbpedia- spotlight-lucene or https://github.com/dbpedia- spotlight/dbpedia-spotlight-model wget http://downloads.dbpedia-spotlight.org/spotlight/dbpedia-spotlight-1.0.0.jar wget http://downloads.dbpedia-spotlight.org/2016-04/en/model/en.tar.gz tar xzf en.tar.gz java -jar dbpedia-spotlight-1.0.jar en_2+2 http://localhost:2222/rest Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 61
DBpedia Spotlight - API curl http://model.dbpedia-spotlight.org/en/annotate \ --data-urlencode "text=President Obama called Wednesday on Congress to extend a tax break for students included in last year's economic stimulus package, arguing that the policy provides more generous assistance." \ --data "confidence=0.35" \ -H "Accept: application/json" Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 62
Vinculum (Ling & Sing, 2015) Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 63
Vinculum (Ling & Sing, 2015) Fonte: https://kgtutorial.github.io/wsdm-slides/Part2_knowledge-extraction.pdf Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 64
EL incontra WSD [Moro et al (2015)] (1/2) Si può utilizzare una base di conoscenza che combina informazione lessicale (sulla parole) e enciclopedica (sulle named entity) BabelNet è un candidato ideale, perché combina Wikipedia, WordNet, ed altre risorse Annotando il testo si risolveranno in modo unificato sia entity linking sia word sense disambiguation. Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 65
EL incontra WSD [Moro et al (2015)] (2/2) L'approccio proposto funziona grandi linee così: Offline – Per ogni entità della KB si determina la sua semantic signature, ovvero una distribuzione di probabilità su altre risorse della KB (ottenuta mediante Random Walk with Restart avendo calcolato in maniera strutturale un peso per ciascun collegamento) Online – Si associano ai frammenti di testo dei significati candidati – Un candidato per un frammento viene collegato ad un candidato di un altro frammento, se il secondo è nella semantic signature del primo (quindi sono relazionati) – Viene estratto un sottografo denso da questa rappresentazione, e si seleziona il miglior candidato per ogni frammento Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 66
Risoluzione di sinonimi non supervisionata [Yates & Etzioni (2007)] (1/2) Elaborazione a posteriori delle tuple estratte da un sistema di Open IE, al fine di rilevare relation e argument phrase sinonime. Due sorgenti di evidenza per stabilire la probabilità che due phrase sono sinonime: – Similarità tra stringhe – Numero di proprietà in comune (per gli oggetti) o di istanze (per le relazioni): es. (Mars, lacks, ozone layer) (Red Planet, lacks, ozone layer), … Clustering delle phrases determinata da questa misura di probabilità. Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 67
Risoluzione di sinonimi non supervisionata [Yates & Etzioni (2007)] (2/2) Il processo di clustering delle phrase comporta una mutua ricorsione: – Quando accorpiamo due relation phrase, è possibile che scopriamo ulteriori proprietà condivise da argument phrase coreferenti (ma non ancora classificate come tali) – Quando accorpiamo due argument phrase, è possibile che scopriamo ulteriori istanze condivise da relation phrase coreferenti (ma non ancora classificate come tali) Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 68
Complessità del linguaggio naturale • Coreferenza • Metafora • Ironia, sarcasmo • Frasi complesse o sgrammaticate Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 69
Complessità del linguaggio naturale - Coreferenza Citando https://en.wikipedia.org/wiki/Coreference: In linguistics, coreference, sometimes written co-reference, occurs when two or more expressions in a text refer to the same person or thing; they have the same referent, […] When two expressions are coreferential, the one is usually a full form (the antecedent) and the other is an abbreviated form (a proform or anaphor). Linguists use indices to show coreference, as with the i index in the example Billi said hei would come. Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 70
Complessità del linguaggio naturale - Coreferenza anaphora Immagini ottenute modificando l'output di: http://corenlp.run/ partial reference Split antecedent Split antecedent & coreferring noun phrase Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 71
Complessità del linguaggio naturale - Coreferenza La risoluzione dell'anafora ci aiuta ad avere estrazioni più significative: (he, developed, theory of relativity) (Albert Einstein, developed, theory of relativity) La risoluzione della coreferenza serve a riconoscere che gli argomenti di due tuple sono la stessa entità (a dispetto di nomi diversi) Essa può servire per passare da una noun phrase come "these scientists" alle named entity coinvolte, Albert Einstein and Erwin Schrödinger Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 72
Complessità del linguaggio naturale - Metafora La comprensione del linguaggio naturale è resa più complicata dall'uso di metafore e, più in generale, di forme la cui comprensione richiede di andare oltre il significato letterale. • "Roma deve mettere nero su bianco le modifiche della manovra": la parola "Roma" non indica la città, bensì il governo della Repubblica Italiana che ha sede a Roma (metonimia) • "Questo problema è solo la punta dell'iceberg": si intende che c'è altro oltre il problema di cui si parla, attraverso un riferimento al fatto che sotto la parte visibile di un iceberg (la punta) c'è una massa sommersa nascosta. Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 73
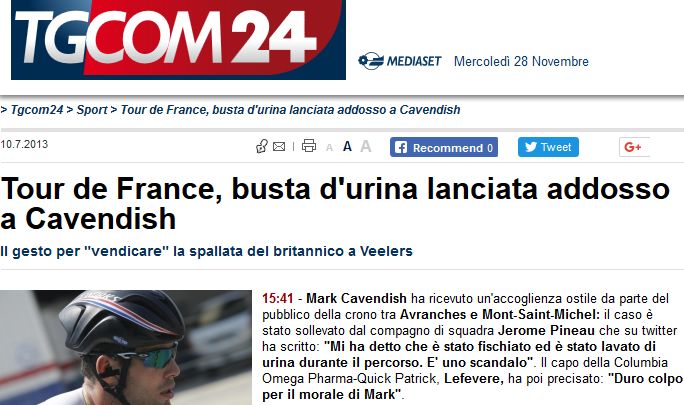
Complessità del linguaggio naturale - Sarcasmo Fatto accaduto al Tour de France del 2013 Fonte: https://www.tgcom24.mediaset.it/sport/articoli/1105362/tour-de-france-busta-d-urina-lanciata-addosso-a-cavendish.shtml Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 74
Complessità del linguaggio naturale - Sarcasmo Qualcuno l'ha commentato su Twitter più o meno così (purtroppo non ho conservato il link): Mark Cavendish ha conquistato la maglia gialla Da un simile post si potrebbe estrarre il fatto che Mark Cavendish ha ottenuto la maglia gialla… Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 75
Correttezza dell'informazione Un pezzo di informazione estratto da un sistema di (Open) IE potrebbe non essere corretto: – Errore del processo di estrazione – Oppure, si è estratto in maniera corretta dell'informazione falsa L'affidabilità di un'estrazione può essere valutata in base alla: – Confidenza dell'estrattore (rischio di errore in estrazione) – Numero di occorrenze (ma attenzione alle bufale virali) – Credibilità dei documenti in cui occorre Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 76
Aspetti temporali/spaziali Tempo: – La capitale del Brasile: Salvador, Rio de Janeiro, Brasilia (in diversi periodi) Spaziale: – In natura orsi polari e pinguini non si incontrano (dal 1844) Vedi: https://www.focus.it/ambiente/animali/si-potrebbero-far-vivere-i-pinguini-al-polo-nord Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 77
Controllo di consistenza Verificare che la conoscenza estratta non contenga contraddizioni. Difficile in un contesto di Open IE: – Apprendimento degli assiomi – Oppure, aggiunta di una o più ontologie di riferimento Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 78
Riferimenti (1/3) • Banko, M., Cafarella, M. J., Soderland, S., Broadhead, M., & Etzioni, O. (2007, January). Open information extraction from the web. In IJCAI (Vol. 7, pp. 2670-2676). • Bast, H., & Haussmann, E. (2013, September). Open information extraction via contextual sentence decomposition. In Semantic Computing (ICSC), 2013 IEEE Seventh International Conference on (pp. 154- 159). IEEE. • Bovi, C. D., Telesca, L., & Navigli, R. (2015). Large-scale information extraction from textual definitions through deep syntactic and semantic analysis. Transactions of the Association for Computational Linguistics, 3, 529-543. • Del Corro, L., & Gemulla, R. (2013, May). Clausie: clause-based open information extraction. In Proceedings of the 22nd international conference on World Wide Web (pp. 355-366). ACM. • Daiber, J., Jakob, M., Hokamp, C., & Mendes, P. N. (2013, September). Improving efficiency and accuracy in multilingual entity extraction. In Proceedings of the 9th International Conference on Semantic Systems (pp. 121-124). ACM. • Etzioni, O., Banko, M., Soderland, S., & Weld, D. S. (2008). Open information extraction from the web. Communications of the ACM, 51(12), 68-74. Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 79
Riferimenti (2/3) • Fader, A., Soderland, S., & Etzioni, O. (2011, July). Identifying relations for open information extraction. In Proceedings of the conference on empirical methods in natural language processing (pp. 1535-1545). Association for Computational Linguistics. • Ling, X., Singh, S., & Weld, D. S. (2015). Design challenges for entity linking. Transactions of the Association for Computational Linguistics, 3, 315-328. • Mausam, M. (2016, July). Open information extraction systems and downstream applications. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (pp. 4074-4077). AAAI Press. • Mendes, P. N., Jakob, M., García-Silva, A., & Bizer, C. (2011, September). DBpedia spotlight: shedding light on the web of documents. In Proceedings of the 7th international conference on semantic systems (pp. 1-8). ACM. • Moro, A., Raganato, A., & Navigli, R. (2014). Entity linking meets word sense disambiguation: a unified approach. Transactions of the Association for Computational Linguistics, 2, 231-244. Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 80
Riferimenti (3/3) • Schmitz, M., Bart, R., Soderland, S., & Etzioni, O. (2012, July). Open language learning for information extraction. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (pp. 523-534). Association for Computational Linguistics. • Yates, A., & Etzioni, O. (2007). Unsupervised resolution of objects and relations on the web. In Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics; Proceedings of the Main Conference (pp. 121-130). Manuel Fiorelli fiorelli@info.uniroma2.it 29/11/2018 http://art.uniroma2.it/fiorelli 81
Puoi anche leggere

















































